別讓 AI 每次都從零開始!深度解析 ERL 框架:讓 LLM Agent 透過「單次反思」實現持續學習

1 前言
1.1 💡 TL;DR
這篇論文提出了一個名為 ERL (Experiential Reflective Learning) 的輕量級框架。它讓 LLM Agent 能夠在「不需要微調模型參數」且「不需要反覆試錯」的情況下,透過單次任務的執行軌跡進行自我反思,萃取出高度濃縮的「啟發式規則 (Heuristics)」。當面對新任務時,系統會智慧檢索出最相關的經驗注入到提示詞中,讓 Agent 真正做到「吃一塹,長一智」,在 Gaia2 基準測試中將成功率大幅提升了 7.8%。
1.2 🎯 核心價值
在目前的 LLM Agent 發展中,我們遇到了一個巨大的瓶頸:Agent 學不會教訓。 當我們把 Agent 部署到真實世界(如客服、個人助理)時,它們每次遇到新任務都像是「失憶」一樣從零開始。傳統的解法是「微調 (Fine-tuning)」,但這對於閉源大模型(如 GPT-4)來說根本行不通,且成本極高。
本篇論文的核心價值在於,它為 Agent 打造了一個 「外掛式的錯題本與武功秘笈」。我們不需要去更動 Agent 底層的思考邏輯(例如標準的 ReAct 迴圈),而是透過一個極其優雅的反思與檢索雙模組設計,將冗長且難以遷移的「原始執行軌跡 (Raw Trajectories)」,昇華為具有高度泛化能力的「條件式操作準則 (Trigger-Action Guidelines)」。
2 問題定義
2.1 痛點分析:為什麼現有的 Agent「學不會教訓」?
在深入探討這篇論文的方法之前,我們先來看看目前的 LLM Agent 領域到底面臨著什麼樣的困境。我們都知道,現今的通用型 Agent(如基於 GPT-4 的 ReAct Agent)具備強大的推理能力。但是,當我們把它們部署到一個包含特定領域規則或陌生工具的「新環境」時,它們的表現往往差強人意。
最致命的問題在於:它們每次面對新任務時,都是「從零開始(from scratch)」的。 它們無法從過去的互動經驗中記取教訓,同樣的錯誤(例如工具參數輸入錯誤)可能會一犯再犯。
為了解決這個「失憶症」,學界過去提出了幾種解法,但都存在難以克服的缺陷:
微調模型 (Fine-Tuning):最傳統的做法,但極度消耗運算資源、無法應用於 API 形式的閉源大模型,且完全不支援動態的「持續學習(Continuous Learning)」。
基於軌跡對比的經驗學習 (Trajectory-based Learning,如 ExpeL 或 AutoGuide):
- 不切實際的假設:這些 SOTA 方法強烈依賴「反覆試錯」。它們要求 Agent 對同一個任務進行多次嘗試,並對比「成功」與「失敗」的軌跡來提取經驗。但在真實世界場景(如幫主管發 email、修改資料庫)中,任務往往是不可逆的,我們只有「單次嘗試(Single-attempt)」的機會。
- 擴展性災難 (Scalability Issues):以 ExpeL 為例,它會把提取出來的所有經驗「無腦塞進」每一個新任務的提示詞中。隨著經驗庫膨脹,上下文(Context Window)很快就會爆滿,且無關資訊反而會干擾 Agent 的判斷。
- 執行延遲 (Overhead):而 AutoGuide 則是走向另一個極端,它在 Agent 執行的「每一個步驟(every single turn)」都去動態檢索經驗。這不僅帶來龐大的 API 呼叫成本,也造成了難以忍受的系統延遲。
原始軌跡提示 (Raw Trajectory Few-shotting):最直觀的想法是直接把過去失敗的完整對話歷史塞給 Agent。但我們在實驗中發現這根本行不通,因為原始軌跡過於冗長且充滿特定任務的瑣碎細節,Agent 很難從中提煉出能應用於新任務的「抽象原則」。
2.2 💡 本篇解法:ERL 的核心洞見
看懂了上述痛點,我們就能瞬間明白 ERL (Experiential Reflective Learning) 為什麼厲害了。這篇論文的洞見在於:我們不需要完美的「成敗對比」,我們只需要一個會「自我檢討」的系統。
ERL 打破了反覆試錯的限制,提出了一套只需單次嘗試即可提取經驗的機制。它將冗長的原始軌跡壓縮成高度抽象的「啟發式規則(Heuristics)」,並將這些規則存入持久化的經驗池中。當面對新任務時,它採用「考前複習」的策略——在任務開始前,精準檢索 Top- 條最相關的規則注入背景中,從而實現零干擾的高效執行。
3 方法介紹
ERL 框架是一個非常優雅的「外掛式設計」。它完全不需要去改動 Agent 底層的基礎架構(例如保持原本的 ReAct 迴圈),而是透過兩個獨立的階段來完成系統的「自我進化」。
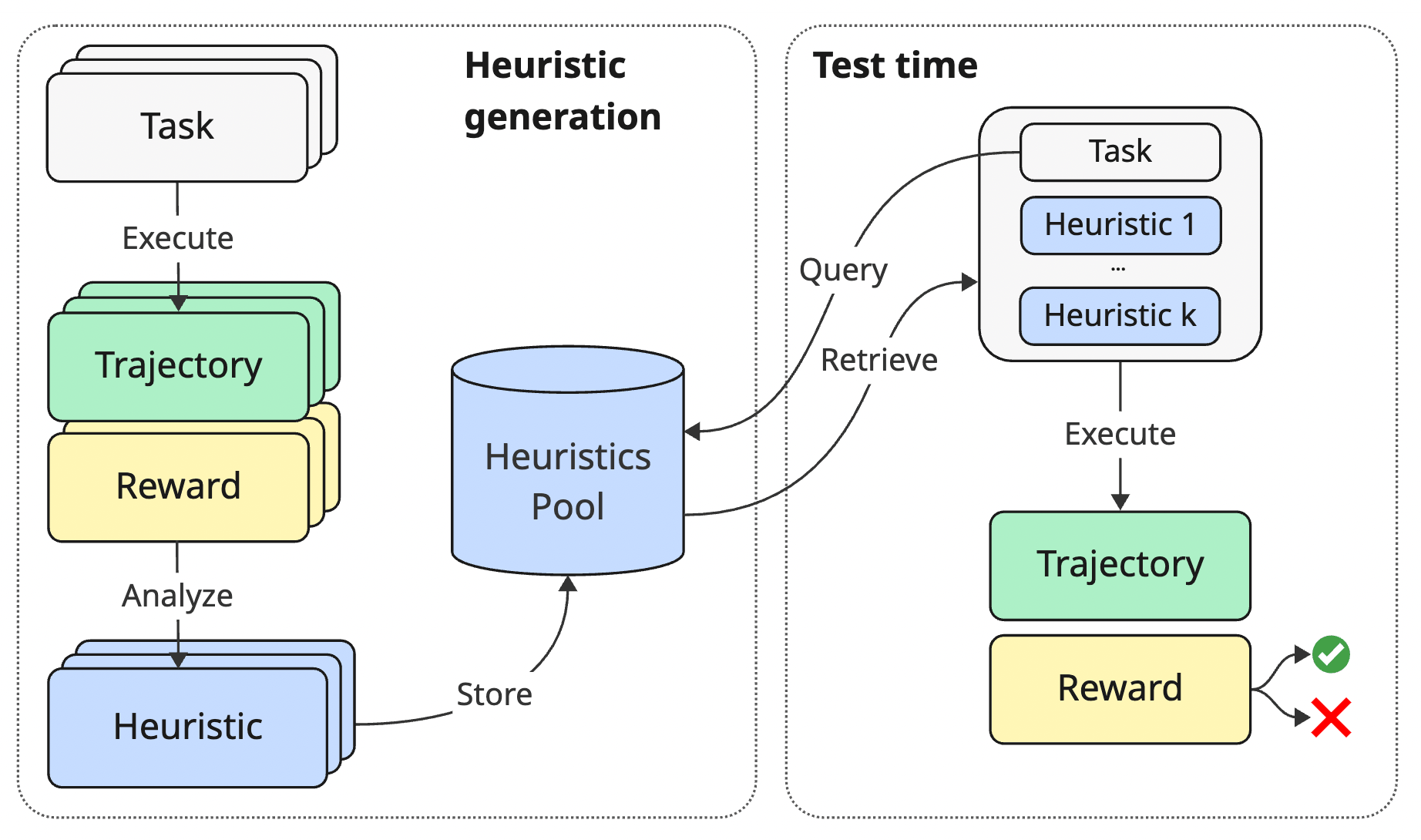
整個資料流可以清晰地分為兩個階段:
3.1 第一階段:經驗累積與反思 (Heuristic Generation)
當 Agent 在環境中執行完一個任務後(不管最終是成功還是失敗),這個階段就會被觸發。你可以把它想像成 Agent 每天下班後的「寫日記與檢討」時間。
3.1.1 單次軌跡輸入 (Single-attempt Input)
系統會收集剛剛完成的這單一次執行的所有資訊,打包成上下文交給扮演「反思者」的 LLM:
- Task:原始任務描述(例如:請幫我取消明天的品酒會)。
- Trajectory:完整的執行軌跡(包含推論過程、呼叫了哪些工具、以及環境的回饋)。
- Reward:一個二元的反饋訊號,標示任務最終是
Success還是Failure。
3.1.2 事後分析與規則生成 (Post-Mortem Analysis)
這是 ERL 最精彩的地方——作者設計了一個結構嚴謹的 Prompt,強制 LLM 根據「成功」或「失敗」走不同的反思邏輯:
- 若任務失敗 (IF FAILURE):LLM 必須先「定位斷點 (Pinpoint the Breakpoint)」,找出邏輯在哪裡出錯或工具在哪裡被誤用。接著,推導出一條具體的修正規則來預防此類錯誤。
- 若任務成功 (IF SUCCESS):LLM 必須找出「致勝關鍵 (Winning Move)」,分析是什麼決策讓執行變得高效,並將其昇華為最佳實踐。
3.1.3 結構化輸出的威力:Trigger -> Action
不論成敗,LLM 最終輸出的「啟發式規則(Heuristic)」都必須被強制規範為特定的格式。這包含了分析(Analysis)與一條學習到的準則(Learned Guideline),而這條準則必須是條件式的:
- Trigger (觸發條件):例如「當我需要發送電子郵件,且輸入只有參與者姓名時…」
- Action (行動建議):例如「我必須先呼叫 Contacts 工具檢索地址,驗證格式後再呼叫 Emails 工具。」
這條規則生成後,會被存入一個持久化的「經驗池 (Heuristics Pool, 記為 )」中。
我們在討論中發現,將經驗轉化為 Trigger -> Action 的形式,不僅達到了「壓縮資訊」的目的(大幅節省 Token),更重要的是,它與 Agent 的 ReAct (Reasoning and Acting) 執行框架完美契合!
當未來 Agent 在 Thought (思考) 階段遇到符合 Trigger 的情境時,它就像是被觸發了肌肉記憶,會自動回想起該採取的 Action SOP,從而巧妙避開陷阱,將「案例」真正轉化為「可泛化的法則」。
3.2 第二階段:檢索增強執行 (Retrieval-Augmented Execution)
當 Agent 面對一個全新的未知任務時,ERL 系統會啟動第二階段,也就是我們所謂的「考前複習」。
3.2.1 任務拆解與 LLM 智慧檢索
面對巨大的經驗池 ,如何挑出最合適的經驗?作者在實驗中發現,單純使用 Embedding(語意向量)比對字面相似度的效果並不好。因此,ERL 採用了基於 LLM 的智慧檢索 (LLM-based Retrieval)。
具體運作的資料流如下:
- 任務拆解:LLM Retriever 首先會分析新任務,並將其拆解為潛在的「子任務」與「行動步驟」(這是一種隱式的 Chain-of-Thought,有助於更精準地匹配底層的具體經驗)。
- 多維度評分:接著,LLM 會對經驗池中的規則進行 0~100 的打分。評分的依據不只有「任務相似度 (Similarity)」,還嚴格包含了「經驗多樣性 (Diversity,避免選出的規則都在講同一個工具)」與「內容資訊量 (Informativeness,規則是否具體可執行)」。
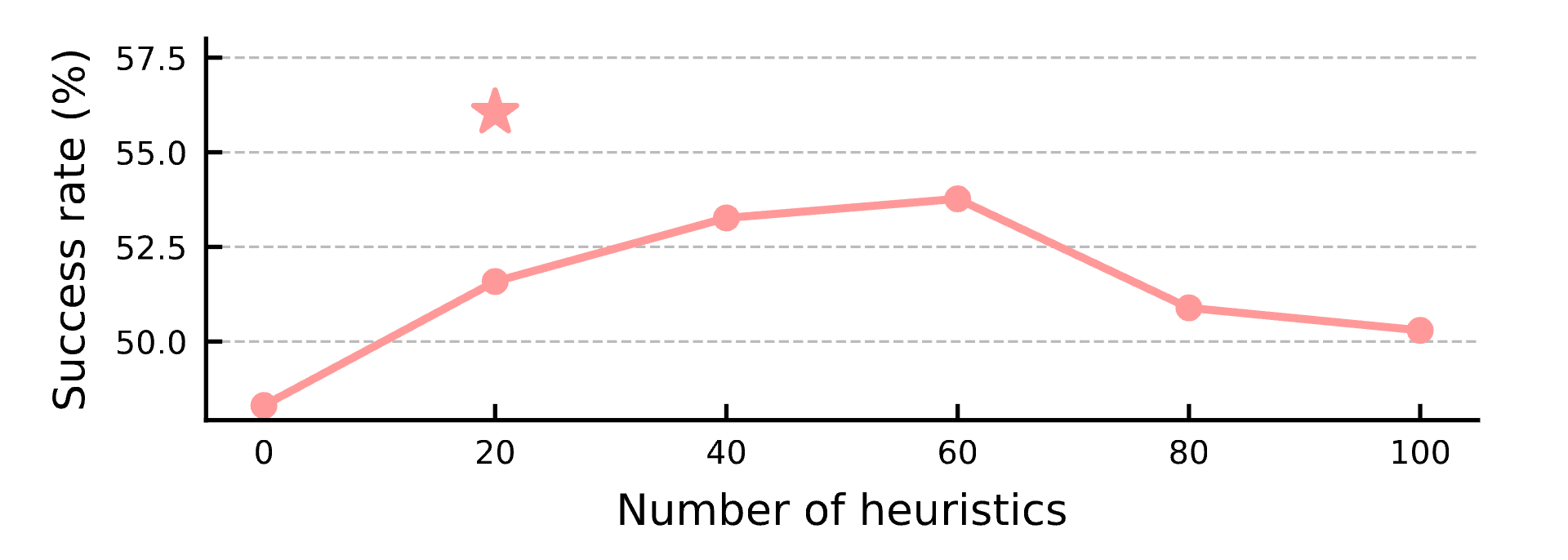
- 精準提取:最終,LLM 輸出得分最高的 Top- 條(實驗證明 效果最佳)規則的情境 ID 與挑選理由。
3.2.2 注入上下文與零干擾執行
選出這 Top- 條啟發式規則後,系統會直接將它們安插進 Agent 的 System Prompt(系統提示詞) 中。 接著,Agent 正式進入環境,開始它標準的 ReAct 執行迴圈。
這是一個非常聰明的架構抉擇:因為已經在任務開始前把「秘笈」給了 Agent,在實際操作的每一步(turn)中,我們不需要再像 AutoGuide 那樣消耗運算資源去動態檢索經驗。這完美實現了我們所說的 Zero-overhead during execution。
4 實驗結果
為了驗證 ERL 的實戰能力,作者選擇了 Gaia2 基準測試。這是一個極具挑戰性的環境,包含 12 個應用程式與 101 個工具,且任務通常需要長路徑推理。
4.1 核心成效:顯著超越 SOTA 方法
ERL 在 Gaia2 的「搜尋 (Search)」與「執行 (Execution)」任務中展現了強大的競爭力。
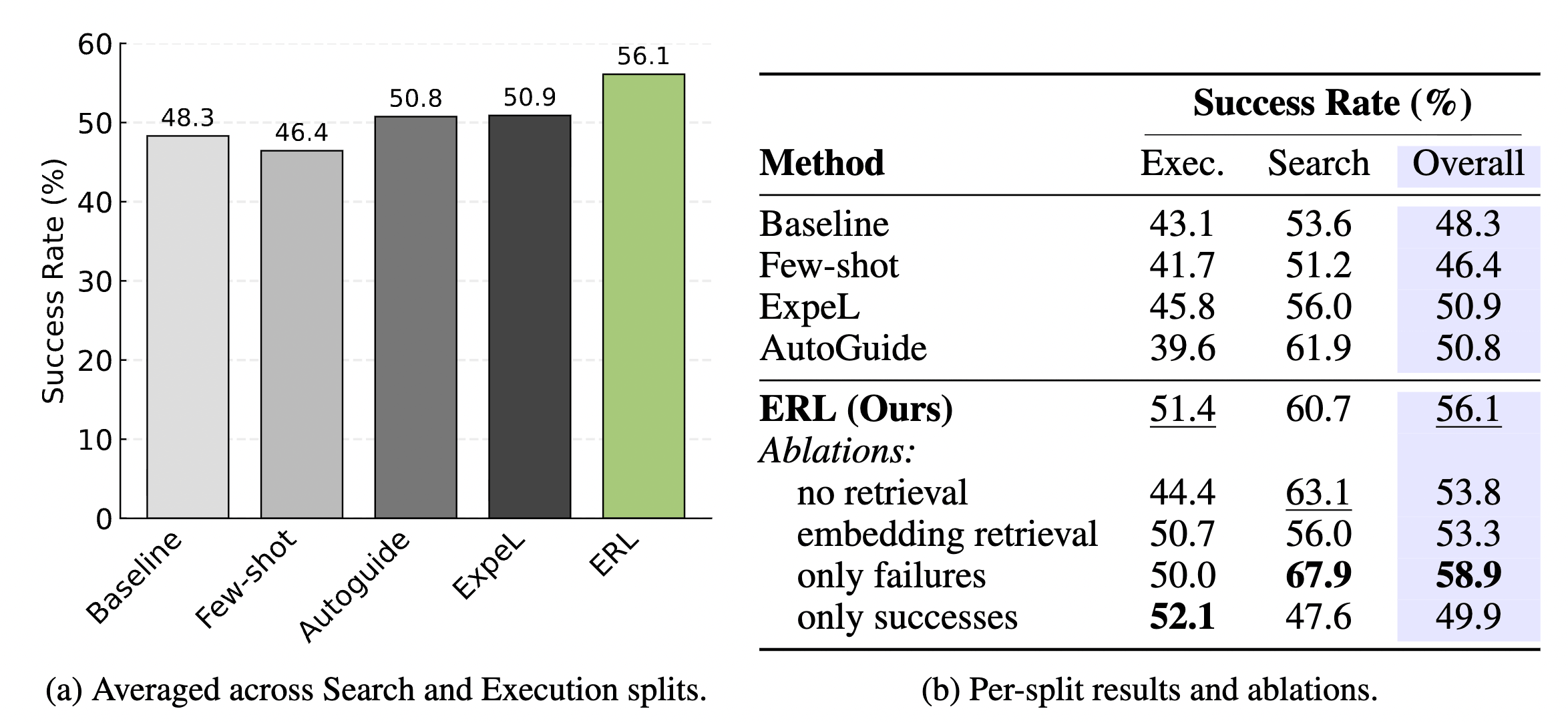
為什麼 ERL 會贏?
- 穩定性 (Reliability):我們在討論中提到過,ERL 不僅提高了成功率,更大幅提升了 (即:連續三次執行任務都成功)。這代表 Agent 不再是「靠運氣」賽到答案,而是真正掌握了穩定的操作 SOP。
- 泛化能力:比起直接餵原始軌跡(Few-shot),ERL 提供的啟發式規則(Heuristics)過濾掉了不必要的干擾資訊,讓 Agent 能更專注於底層邏輯。
4.2 消融實驗分析:模組的必要性
作者透過一系列「拆解」實驗,證明了 ERL 每個設計都不是多餘的。
4.2.1 啟發式規則 vs. 原始軌跡
這可能是我們最在意的一個實驗。如果直接把過去的原始對話(Raw Trajectories)給 Agent 看呢?
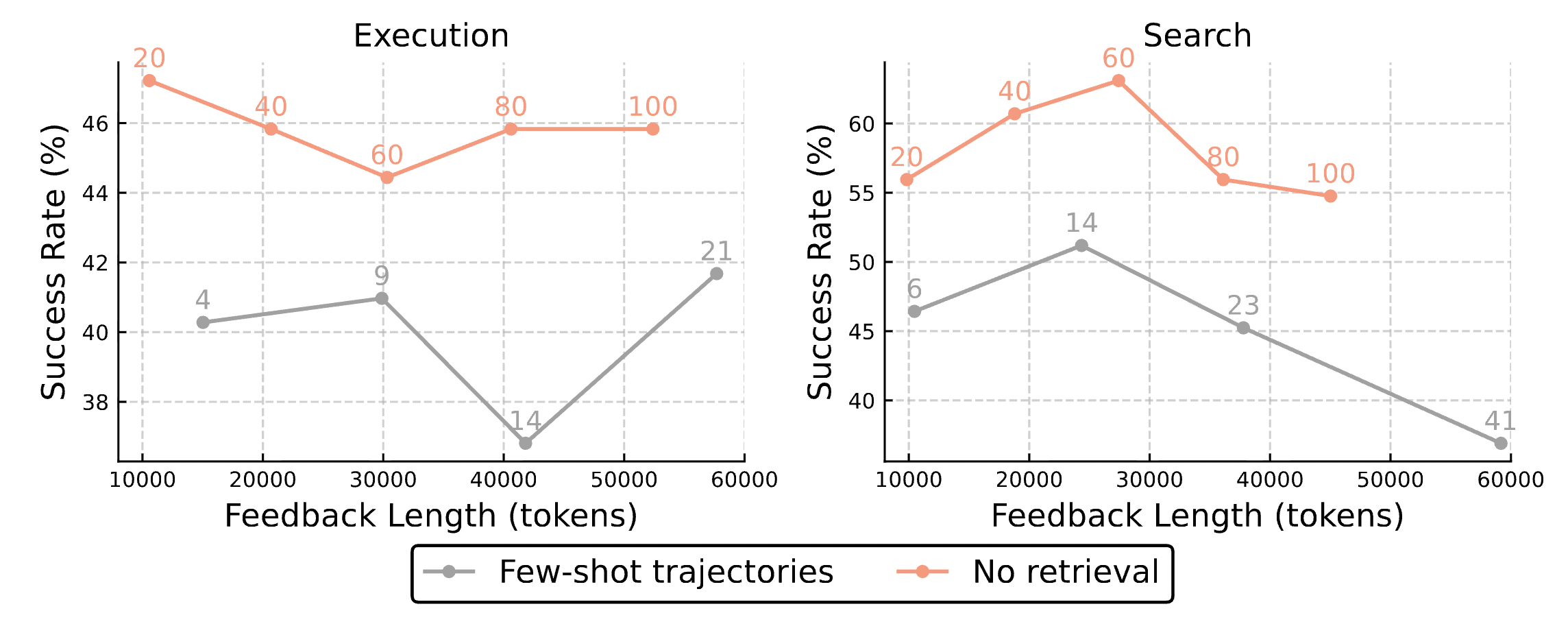
4.2.2 檢索品質的重要性
如果我們不要用昂貴的 LLM 來檢索,隨機挑選規則會怎樣?
5 結論
本篇論文針對 LLM Agent 「缺乏持續學習能力」且「依賴反覆試錯」的痛點,提出了 ERL (Experiential Reflective Learning) 框架。
透過單次執行後的自我反思,將經驗轉化為結構化的 Trigger-Action 規則。在執行期,利用 LLM 智慧檢索 將最相關的 20 條規則注入上下文。最終在 Gaia2 基準測試中,實現了超越 SOTA 方法的性能與穩定度。
儘管 ERL 表現優異,我們必須指出它的局限性:
- 擴展性與成本:目前的檢索機制(Full-context LLM ranking)雖然精準,但面對成千上萬條經驗時,其 Token 成本與延遲將變得不可接受。這需要未來透過「兩階段檢索」來優化。
- 衝突解決:如果經驗池中存在兩條互相矛盾的規則(例如不同宇宙的規則衝突),目前系統尚未有明確的仲裁機制。
- 自動維護:隨著經驗累積,如何自動清理過時或錯誤的規則(Memory Consolidation)也是一個值得探討的方向。