[論文介紹] Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search

1 前言
本篇文章介紹一篇有趣的論文 — Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search。本篇論文於 2025 年 7 月被發表於 arXiv 上。
從論文的標題就可以馬上知道,這篇論文主要是針對 “Deep Search” 的技術,提出一個更好的 Reasoning Framework,也可以說是一種 Agentic Workflow/Framework。本篇論文所提出的方法一樣也隱藏於標體中,稱為 Hierarchical Reasoning (HiRA)。 HiRA 所提出的 Worflow 由三個 Agent, Planner, Coordinator 以及 Executor 組成,他們之間互相傳遞資訊以及合作來生成最終更好的搜尋結果。
雖然 HiRA 的定位是在 Deep Search 方法,但是其所提出的 Planner, Coordinator 以及 Executor 之間的合作模式,我覺得是完全可以應用到其他領域的,作者也有開源其程式碼!
Planner-Executor 的框架在 Agentic Worflow 的方法中非常常見。通常這類的方法大多主張:與其讓 Single Agent 同時做 Planning 與 Tool Calling,不如拆解為 Planner Agent 以及 Executor Agent。如此一來,Planner Agent 就可以更專心的理解使用者的任務以及最終目標,決定更正確的下一步;同時,Executor Agent 也可以根據 Planner Agent 的指示,選擇適合的 Tool,提供正確的 Tool Input,並回傳 Tool Execution Result。
本篇論文 HiRA 基於 Planner-Executor 的框架,額外加上 Coordinator Agent,目的是為了提昇 Planner 與 Executor 之間的資訊傳遞。
如果你是第一次聽到 Planner-Executor Agentic Workflow 的設計模式,不妨先閱讀我們之前所介紹過得幾篇文章,快速掌握基本概念 😉:
2 HiRA 想解決的問題
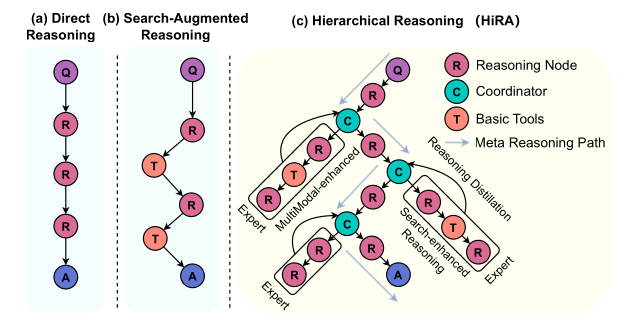
如 Figure 1 所示,一般的 Deep Search 方法中,單純提供 Search Tool 給 Large Reasoning Model (LRM),讓 LRM 經過 Reasoning 後透過一些特殊 Token 來表示其 Action。例如,在 WebThinker 中,會透過 <|begin search query|> 和 <|end search query|> 來觸發 Search Action。
而作者認為一個 LRM 同時進行 Planning 以及 Execution (Tool Calling) 會有以下缺點:
- Limited Capability Extensibility: 每當要給予 Agent 新的 Tool 時,就必須要修改既有的 Prompt,來讓 Agent 能夠產生新的特殊 Token,而這可能也會影響到原來的 Planning 表現
- Reasoning Disruption: 將 Tool 執行完的結果直接加入到 Agent 既有的 Reasoning Chain 中,有時會加入一些 Noise 而影響到 Agent 後續的 Reasoning
針對 Limited Capability Extensibility,顯而易見的作法就是將 Single Agent 拆解為 Planner Agent 以及 Executor Agent,如此一來,當 Executor 加入更多 Tool 時,也不會影響到 Planner 本身的 Prompt;而針對 Reasoning Disruption,則是在 Planner 與 Executor 之間再加入一個 Coordinator,如此一來 Executor 的 Tool Execution Result 就可以再經由 Coordinator 的處理後回傳給 Planner。
基於這樣的思路就形成了本篇論文 HiRA 中 Planner-Coordinator-Executor 的雛型!
3 HiRA 所提出的方法
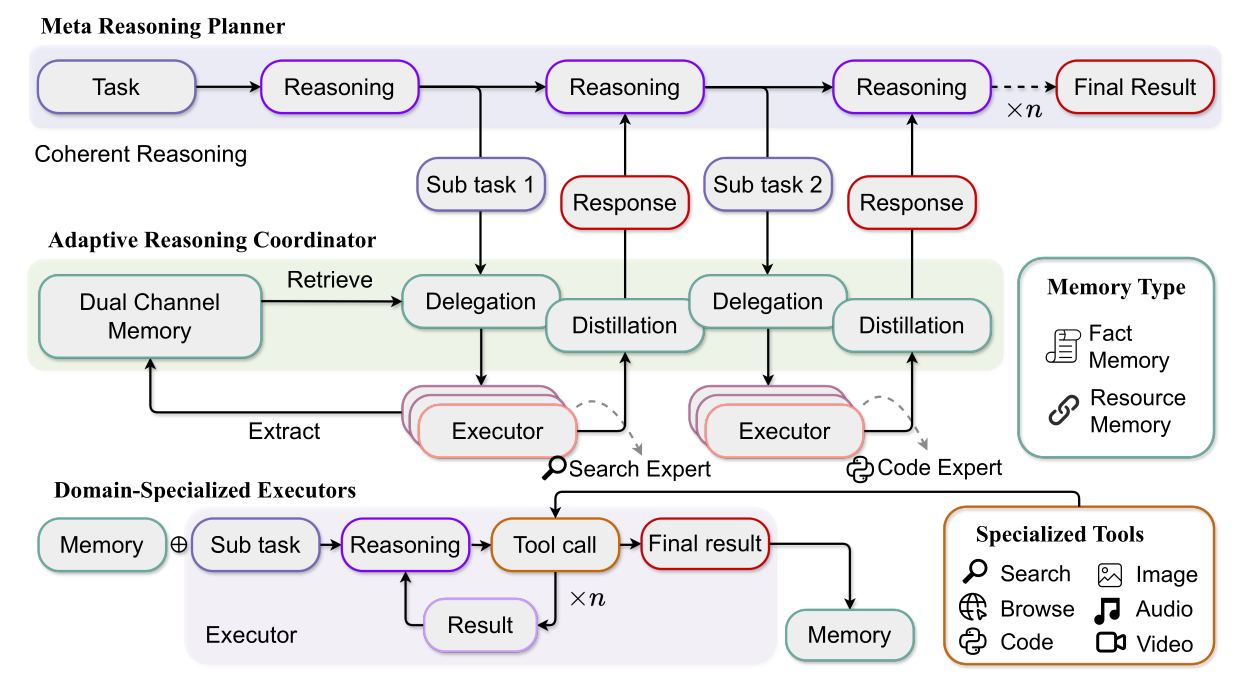
如同前文所述,HiRA 框架中包含 Planner Agent, Coordinator Agent 以及 Executor Agent。而他們在論文中的正式名稱為:
- Meta Reasoning Planner
- Adaptive Reasoning Coordinator
- Domain-Specialized Executors
3.1 Meta Reasoning Planner
Meta Reasoning Planner 作為整個框架的 Core Orchestrator,負責將原來的任務拆解為多個子任務,並且生成最終的答案。Planner 每次在產生新的子任務時,都是基於過去的 Reasoning 過程,以及既有的子任務的執行結果。如下方 Prompt 所示,Planner 新產生的子任務描述必須放置在 <|begin_call_subtask|> 與 <|end_call_subtask|> 特殊 Token 之間:
You are a reasoning and planning assistant. Your goal is to solve the user's task by decomposing it into atomic, well-scoped and self-contined sub-tasks, which you delegate to specialized execution agents.
The sub tasks given should be effective, you need to use as few sub tasks as possible to correctly solve users' task. You have limited calls (10 max) to these agents, so be strategic.
Sub-agent types:
1. Search-agent: This agent can search the web for information, including reading web pages and analyzing the content.
2. Code-agent: This agent can write python code to complete tasks, including reading files, data analysis, and use other python libraries.
3. Multimodal-agent: This agent can use multimodal understanding tools to assist in reasoning and problem-solving, including image, video, and audio.
To invoke a sub-task, use the format (you only need to give task, sub-agent will be selected automatically):
<|begin_call_subtask|> Describe the atomic task you want the sub-agent to perform here. Be specific and actionable, don't add any unnecessary information. Optionally, include your expected reasoning path. <|end_call_subtask|>
Once a sub-task is executed, its result will be returned in this format:
<|begin_subtask_result|> ...content including reasoning and answer... <|end_subtask_result|>
Then you need to carefully check the subtask result and logic, and continue your reasoning.
Rules to follow:
1. Sub-tasks must be **atomic** (not composed of multiple steps) and **clearly defined**, don't have any unnecessary information.
2. **Avoid repeating similar tasks or issuing unnecessary ones — you only have 10 calls**, use calls wisely.
3. Always **consider what you already know** (including previous sub-task results) before planning a new one.
4. If the result includes a clear and valid reasoning path, you can **fully trust the answer**.
5. After each result, **update your plan** and reason about the next best step. If the subtask performs poorly, try providing a different or more specific execution method in subtask call.
6. Once the original question is fully answered, **output the final answer using**: `\\boxed{{your final answer}}`
Example workflow:
User Task: "Who painted the ceiling of the Sistine Chapel, and what year was it completed?"
You:
- First, I need to know who painted the ceiling.
<|begin_call_subtask|>Find out who painted the ceiling of the Sistine Chapel.<|end_call_subtask|>
<|begin_subtask_result|>The ceiling was painted by Michelangelo.<|end_subtask_result|>
- Now I need to know when the painting was completed.
<|begin_call_subtask|>Find out the year Michelangelo completed the ceiling of the Sistine Chapel.<|end_call_subtask|>
<|begin_subtask_result|>It was completed in 1512.<|end_subtask_result|>
\\boxed{{Michelangelo, 1512}}
Please answer the following user's task step by step. Use the subtask calls and previous results wisely to get the final answer.
You should provide your final answer in the format \\boxed{{YOUR_ANSWER}} and end your reasoning process.
Please carefully understand the user's task and strictly pay attention to the conditions inside. Given a detailed plan at first.
User's Task:
{user_task}當一個子任務產生後,會由 Coordinator 將這個子任務分配給適合的 Executor 來處理,Executor 的執行結果會再經由 Coordinator 處理過後再回傳給 Planner。換句話說,Planner 只需要專注的做好 Planning (e.g. 拆解出子任務),並在收集足夠多的資訊後生成最後的答案。
3.2 Adaptive Reasoning Coordinator
Adaptive Reasoning Coordinator 的任務是要站在 Planner 與 Executor 之間,避免他們之間訊息傳遞過程的資訊流失。
針對這部份我在實務經驗上蠻有感覺的!由於敏感資料與硬體資源等限制,我過去開發 Agentic Workflow 的過程中只能透過 Self-host LLM (e.g. Llama-3.3-70B)。在我的開發經驗上,基於 Llama-3.3-70B 所開發的 Single Agent (e.g. ReAct, CodeAct) 類型的方法,表現會相當不穩定。每當 Reasoning Chain (Trajectory) 變得較長時,模型在 Planning 以及 Tool Selection 的表現會明顯變差,甚至有時候還會出現一些難以理解得出錯 (e.g. 在推理過程中是正確的,但是在呈現最後的答案時,卻給出了一個思考過程中不曾出現的錯誤資訊)。
實際上,LangChain 也有針對一些模型 (e.g. Claude-3.5-Sonnet, GPT-4o, o1, o3-mini, Llama-3.3-70B),基於 ReAct 方法,衡量它們在 Planning Task (e.g. Calendar Scheduling Tasks, Customer Support Tasks) 上的表現,由 Benchmark 結果 可以發現到,Llama-3.3-70B 基本上很難單純的透過簡單的 ReAct-Based 的 Single Agent 方法得到好的 Planning 表現。
也因為如此,我將 Single Agent (e.g. ReAct, CodeAct) 的方法拆解為 Planner-Executor 的模式 (e.g. Plan-and-Act, Pre-Act, OctoTools)。由於 Planner Agent 的 Input Context 資訊減少許多,表現也明顯更為穩定。
但在過程中也看見了本篇論文作者所提到的問題 — Planner 與 Executor 之間訊息傳遞的資訊流失。有時 Planner 可能會給 Executor 不那麼明確的任務 (e.g. “比較今天的氣溫和昨天的氣溫”),使得 Executor 所回傳的 Execution Result,會包含雜訊或是過於簡潔 (e.g. “Higher”),而使得 Planner 需要再做更多 Reasoning 來收集更完整的資訊。這個狀況尤其在 Executor 本身是 “Code Agent” 時又更為嚴重。
3.2.1 Planner ➡️ Executor
回到本篇論文 HiRA,基於 Planner 所提供的子任務,Coordinator 需要基於 (1) 子任務的描述 (2) Executor 描述 (3) 分析方法 (e.g. 分析這個子任務需要什麼能力, 分析子任務的複雜度) 來決定最適合的 Executor。如下方的 Prompt 所示:
You are an agent selection system. Analyze the given task and select the most suitable agent based on:
1. Required Capabilities:
- What specific skills/knowledge does this task demand?
- How well does each agent's expertise match these requirements?
2. Task Difficulty:
- Complexity level (simple fact vs multi-step problem-solving). You should consider the effective time cost of each agent.
- Depth of analysis needed (surface information vs deep exploration)
- You need to choose the model **that can complete the task** with the lowest cost/complexity as much as possible.
**Only output the JSON format** with the following fields:
- reason: The reason for selecting the agent
- selected_agent_name: The name of the selected agent
Example Output:
```
{
"reason": "The task requires deep web exploration and analysis, which is beyond the capabilities of the naive RAG agent. The Web-Thinker agent is better suited for this task due to its multi-step reasoning and web browsing capabilities.",
"selected_agent_name": "Web-Thinker"
}
```Agents Available: {agent_info}
Task: {task}
Analyze the task and respond **ONLY the json format**, without any additional explanation.3.2.2 Executor ➡️ Planner
此外,為了避免 Executor 回傳的 Execution Result 過於簡潔或是包含雜訊,Coordinator 會透過以下兩個步驟來整理 Executor 的 Reasoning 過程:
- Reasoning Refinement: 透過 Coordinator 將 Executor 的原始思考過程精鍊出精簡版本的思考過程 ➡️ 得到 Distilled Reasoning
- Conclusion Extraction: 透過 Coordinator 將 Executor 的原始與精簡版本的思考過程抽取出精簡的的結論 ➡️ 得到 Distilled Conclusion
最後將 Distilled Reasoning 與 Distilled Conclusion 回傳給 Planner。如下 Prompt 所示:
You are a professional Conclusion Summarization Assistant. Your primary responsibility is to analyze problems and reasoning processes, then generate a structured summary. Your output should be both concise and clear, optimized for understanding by the meta-reasoning system.
# Please organize your summary into these two key components:
# 1. reasoning_process:
# - Describe the critical reasoning steps leading to the final answer in concise language
# - Ensure each step is necessary and logically coherent
# - Avoid redundant information, focus on the main reasoning path
# - Use clear causal connectors between steps
# 2. final_conclusion:
# - Summarize the final answer in one or two precise sentence
# - Ensure the answer directly addresses the original question
# - Avoid vague or uncertain expressions
# - For numerical results, clearly specify units
# Output Format Requirements:
# Please strictly follow this JSON format:
# ```json
# {{
# "reasoning_process": "First analyzed X data, identified Y pattern, then calculated result using Z method",
# "final_conclusion": "The final answer is [specific result]"
# }}
# ```
# Important Notes:
# - reasoning_process should be brief and concise, and easy to read and understand, not just a list of bullet points
# - Keep the reasoning process concise yet informative enough for verification
# Reasoning Chain:
# {reasoning_chain}
# Task: {task_description}3.2.3 Memory Mechanism
為了讓 Executor 之間的資訊可以更有效率的傳遞,Coordinator 還會維護一個 Memory Repository,這個 Repository 又可以分為兩種類型:
- Fact Memory: 存放 Executor 在思考過程中所發現的事實。每個 Entry 由 Fact 以及 Source 組成。
- Resource Memory: 存放 Executor 在思考過程中探索過得資源。每個 Entry 由 Resource 的 Summary 以及 Source 組成。
不管是在 “Planner ➡️ Executor” 或是 “Executor ➡️ Planner” 的過程都會觸發這個 Memory Mechanism:
Planner ➡️ Executor 過程: 先透過 Semantic Similarity 從 Fact Memory 取出與子任務相似的 Fact 再進行 Filtering,並將這些篩選出來的資訊提供給 Executor
You are an assistant specialized in filtering memory based on a specific task. Your task is to analyze the given memory and select ONLY the most task-relevant memories, with a strict maximum limit of 5 entries. Key Requirements: 1. Relevance First: - Each selected memory MUST have a direct and strong connection to the current task - Reject memories that are only tangentially or weakly related - If there are fewer than 5 highly relevant memories, select only those that are truly relevant 2. Quality Control: - Filter out any memories with invalid or suspicious URLs - Remove memories about failed attempts or negative experiences - Exclude memories that contain speculative or unverified information 3. Output Format: - Output the filtered memories in the following format: ``` Memory Fact 1: [memory1] Memory Fact 2: [memory2] ... ``` Remember: It's better to return fewer but highly relevant memories than to include marginally related ones just to reach 5 entries. Memory: {memory} Task: {task} Filtered Memory:Executor ➡️ Planner 過程: 從 Executor 的思考過程中,抽取出對於子任務有幫助的 Fact 與 Resource,並將這些資訊存回到 Memory Repository
You are a Memory Extraction Agent. Your task is to analyze a reasoning process and extract **only the information that is highly likely to be useful for future tasks**, and organize it into a structured memory format. Your output must be a JSON object with these two fields: 1. fact_memory: List important facts discovered during reasoning. * Each fact must include both content **and** source. * Sources must be specific (e.g., exact URLs, specific document titles, or "Model Inference"). * Consolidate related facts into single entries to reduce fragmentation. * Exclude facts that are relevant only to the current question and unlikely to be reused. * If no valid source exists, mark as [Source: Not Specified]. 2. resource_memory: Map useful resources as `"description": "path"` or `"description": "```variable_name```"` pairs. * Paths must be valid URLs; variable names must be exact and surrounded by triple backticks. * Descriptions should be clear and concise. * Variable name must be exact from code call, including function name, variable name, etc. * If no valid resources exist, set this field as an empty dictionary. Output a JSON object only. Do not include any explanation or comments. Example output: ```json {{ "fact_memory": [ "Key product features: Energy Star certified, frost-free technology, LED interior lighting, smart temperature control with 5 settings (32°F-42°F), and automatic defrost functionality [Source: https://appliance-manual.com/model-x200]", "Energy rating scale: Category A (<400 kWh), Category B (400-500 kWh), Category C (>500 kWh) [Source: Model Inference]" ], "resource_memory": {{ "Energy efficiency standards documentation": "https://energy-standards.org/ratings", "Product specification variable, is a list of integers": "```product_specs```" }} }} ``` Reasoning Chain: {reasoning_chain} Task: {task_description}
3.3 Domain-Specialized Executors
在 Executor 部份,HiRA 基於 3 個面向的能力,設計了 4 種 Executor:
Information Acquisition: 負責取得網路上的資訊
- RAG Executor: 一個簡單的 RAG Wrokflow 來應付簡單的任務
- WebThinker Executor: 同樣為 Deep Search 方法,來應付複雜的任務
Cross-Modal Understanding: 負責理解文字以外的模態 (e.g. Image, Video, Audio)
- Cross-Modal Executor: 在一般的 LRM 上加上 Multimodal Models 作為 Tools
Computational Reasoning: 負責數學相關的運算
- Computational Executor: 在一般的 LRM 上加上 Code Interpreter 作為 Tools
4 HiRA 實驗結果
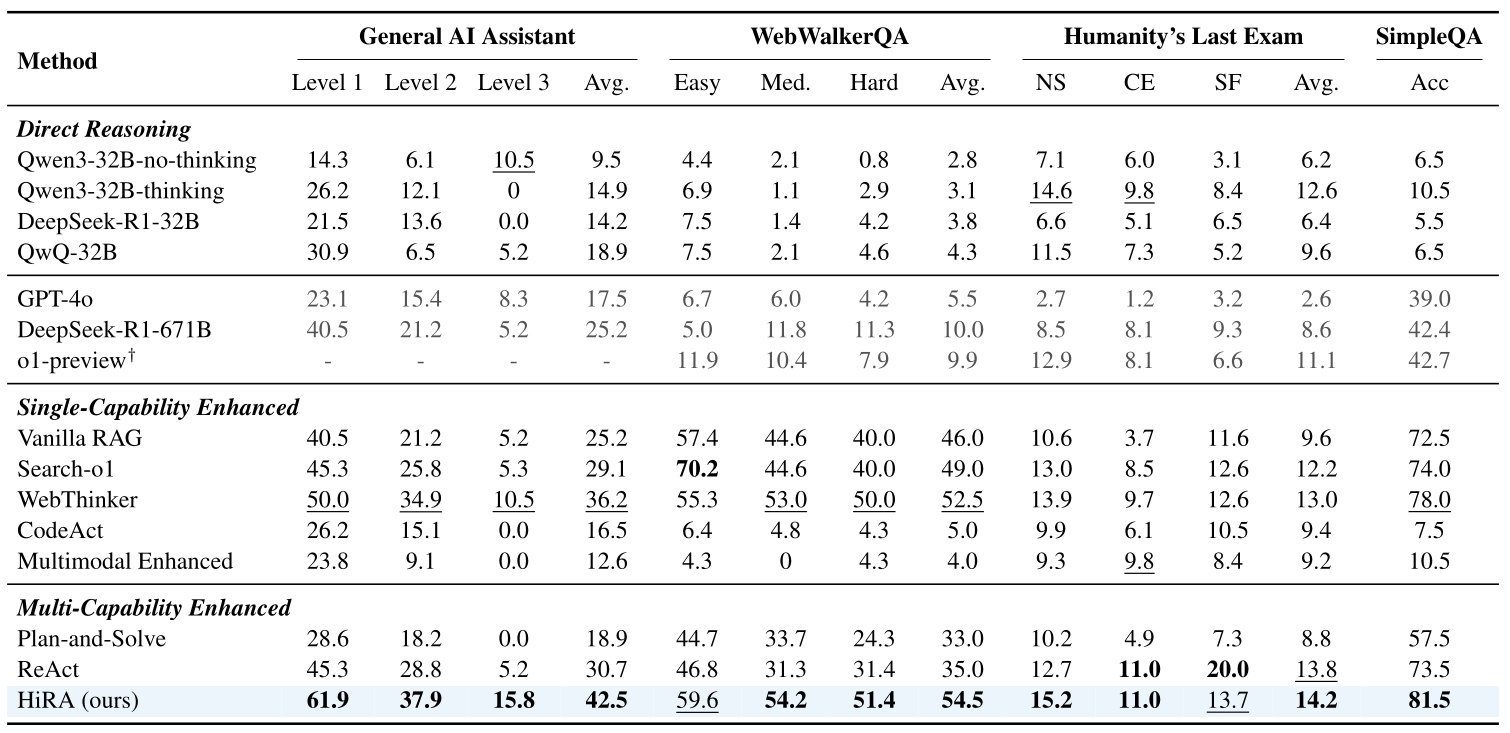
在實驗設定中,HiRA 基於 QwQ-32B 作為 Planner 與 Executor,使用 Qwen-2.5-Insturct-32B 作為 Coordinator,使用 Qwen2.5-Omni-7B 作為 Cross-Modal Executor 中的 Multimodal Model Tools。此外,Decoding 參數分別為 temperature=0.7, top_p=0.95, top_k=20。
由 Table 1 可以明顯看到 HiRA 方法在 4 個 Benchmark 上幾乎都達到了 SOTA 的表現。
5 結語
本篇文章介紹 Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search 論文。本篇論文針對 Deep Search 的技術提出了一個 Planner-Coordinator-Executor 的模式。相較於常見的 Planner-Executor 模式,我認為 Coordinator 的設計是本篇論文的亮點之一。透過 Coordinator 優化了 Executor 回傳給 Planner 的執行結果的資訊,也透過 Memory Mechanism 來提昇 Executor 之間資訊的傳遞。在實驗結果上,也可以看到 HiRA 相較於 Strong Baseline “WebThinker” 有更好的表現。