拒絕 AI 盲猜!NAACL 2025 論文詳解:教 LLM 學會「不懂就問」的 INTENT-SIM 演算法

1 前言
大家在開發 LLM 應用 (或是單純用 ChatGPT) 的時候,應該都有過這種經驗: 你丟出一個稍微模糊的指令,比如問「蘋果最近表現如何?」,你心裡想的是那家科技巨頭的股價,結果模型一本正經地回你今年水果市場的批發價。
這就是現今 LLM 最大的痛點之一: 太愛「盲猜」。
目前的模型大多被訓練成「有問必答」的乖學生,即使面對語意不清的指令,它們也會傾向選一個機率最高的答案直接輸出。但在真實落地的 LLM 中,這種「不懂裝懂」的代價很高。我們希望 AI 像個資深顧問 —— 當我不確定你的意思時,我應該主動停下來問你,而不是胡亂生成一通。
今天要聊的這篇 Paper “Clarify When Necessary” (NAACL 2025),就提出了一個非常優雅的解法。作者不只定義了什麼時候該問,更提出了一套名為 INTENT-SIM 的演算法,讓模型在「腦海中」模擬使用者的多種意圖,藉此精準判斷是否需要發起對話。
- 拒絕盲猜: 互動式 AI 的核心能力不只是回答問題,更在於判斷「何時該發問」。
- 解耦不確定性: 傳統方法看 Logits (Likelihood) 常常分不清是「模型自己笨」還是「題目沒說清楚」。本篇論文完美解耦了這兩者。
- INTENT-SIM 演算法: 透過讓模型生成一個釐清問題,並自我模擬多種可能的回答 (User Simulator) ,計算意圖的 Entropy 來決定是否發問。
- 對話 > 完美指令: 實驗發現,透過「一問一答」釐清後的表現,竟然比直接給定「完美無歧義的指令」還要好,這顛覆了我們對 Prompt Engineering 的認知。
2 為什麼「決定何時發問」這麼難?
在進入演算法之前,我們先來拆解一下問題。為什麼我們不能簡單地設定一個 Threshold,當模型信心分數 (Confidence Score) 低的時候就發問?
這裡有兩個魔鬼細節:
2.1 歧義不是二分法
過去學術界常把歧義 (Ambiguity) 當成一個 True/False 的分類問題。但在真實世界,語言是有 「主導解釋 (Dominant Interpretation)」 的。
舉個例子,如果我說「我要去波士頓」,雖然喬治亞州也有個波士頓,但 99% 的人都會預設是麻薩諸塞州的那個。如果你的 LLM 每次聽到波士頓都要跳出來問: 「請問是指 MA 還是 GA?」,使用者體驗絕對會崩潰。
所以,系統必須懂得權衡: 發問帶來的準確度提升 vs. 打擾使用者的互動成本 (Interaction Cost)。
2.2 混在一起的不確定性
這是最技術性的痛點。當模型輸出一個低信心的答案 (High Entropy) ,通常有兩種可能:
- 認知不確定性 (Epistemic Uncertainty): 模型自己笨。例如問它一個沒看過的冷門知識,或是它沒被訓練好的語言。這時候問使用者是沒用的,因為模型根本不知道自己在講什麼。
- 偶然/內在不確定性 (Aleatoric Uncertainty): 題目本身模糊。輸入資訊包含多種合理解釋。只有這種情況,才需要向使用者發問。
現有的 SOTA 方法 (如直接看 Output Likelihood) 無法區分這兩者。這導致系統常常在自己知識不足時亂問問題,卻在真正有歧義時選擇閉嘴。
這篇論文的核心貢獻,就是透過 INTENT-SIM 成功「解耦」了這兩種不確定性。
3 方法論: 讓模型學會「腦補」
作者提出了一個三階段的方法 (Three-Stage Pipeline) ,以及核心演算法 INTENT-SIM。
3.1 三階段的方法
這是一個通用的決策框架,模擬真實世界中「預算有限」的場景:
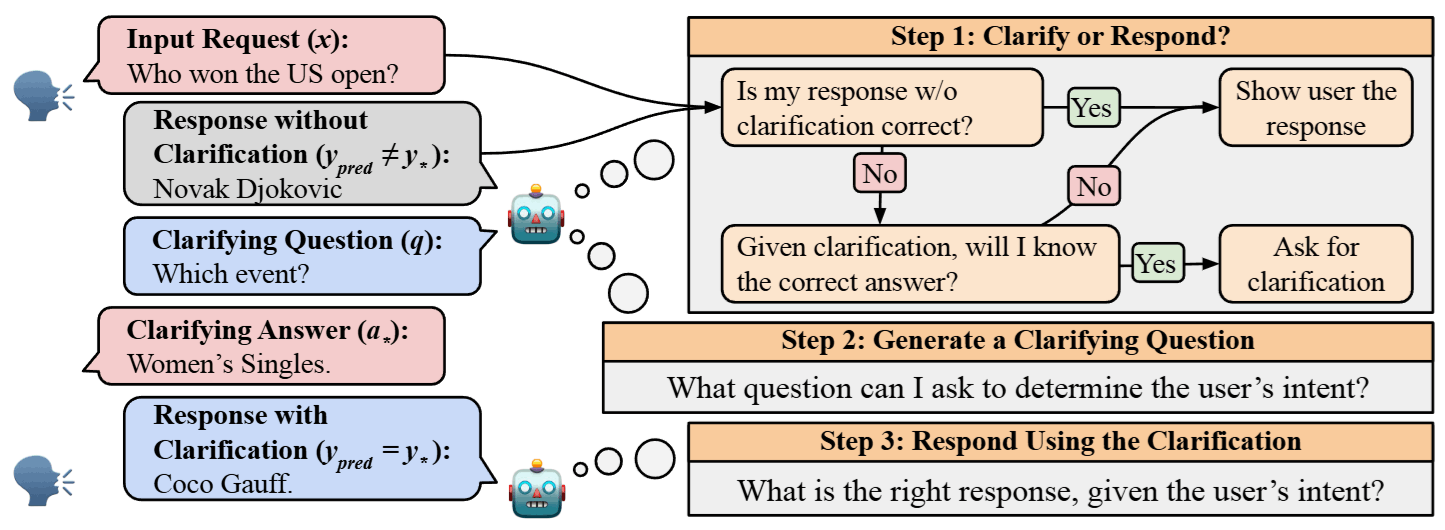
- 決策階段 (Clarify or Respond?): 計算不確定性分數 。如果超過門檻 (例如預算只允許我們對前 10% 最模糊的問題發問) ,就進入階段 2;否則直接回答。
- 釐清階段 (Generate & Ask): 系統生成問題 ,使用者回答 。
- 回應階段 (Final Response): 根據 或 生成最終答案。
3.2 核心演算法: INTENT-SIM
這是本篇論文的靈魂。作者的想法很直觀: 要判斷一個問題有沒有歧義,最好的方法就是看「如果我問了這個問題,使用者會有多少種截然不同的回答?」
這個過程分為四步:

3.2.1 讓模型「自問」 (Generate Clarifying Question)
收到輸入 後,先用 Few-shot prompting 逼模型生成一個它覺得最該問的釐清問題 。
- 這一步很關鍵,它相當於給模型戴上了一個「尋找歧義」的濾鏡,強迫模型關注輸入中不明確的部分。
3.2.2 影分身之術 (Simulate User Responses)
有了問題 ,系統接著扮演「使用者」,模擬回答這個問題。
- 我們將溫度參數 (Temperature) 調高 () ,隨機採樣 次。
- 得到 10 個模擬回答 。例如針對 “trunk”,可能得到「Car’s rear storage」、「Elephant’s nose」、「Large box」等。
3.2.3 意圖分群 (Intent Clustering via NLI)
這裡遇到一個 NLP 的經典問題: 換句話說。 「後車廂」和「汽車尾部的置物空間」字面上不同,但意圖 (Intent) 是一樣的。我們不能因為字面不同就說有歧義。
作者使用 NLI (Natural Language Inference) 模型來解決這個問題:
- 對 10 個回答進行兩兩比對。
- 如果 與 互相蘊含 (Entailment) ,則視為同一類。
- 利用圖論演算法 (DFS) 找出連通分支 (Connected Components) ,每個分支代表一個獨立的使用者意圖。
3.2.4 計算不確定性分數 (Entropy Calculation)
最後,計算意圖分佈的 Entropy。
- 高 Entropy: 模擬出的回答很發散 (一下說是象鼻,一下說是後車廂) 真歧義,該問!
- 低 Entropy: 模擬出的回答高度集中 (大家都說是波士頓麻州) 有主導解釋,直接回答!
透過這個流程,如果模型是因為「知識不足」而困惑,它通常無法生成具體的釐清問題,或者模擬出的回答會是一堆無意義的雜訊 (被 NLI 過濾掉) ,從而成功避免了無效發問。
4 實驗數據: 打臉直覺的發現
作者在 QA (AmbigQA)、NLI (AmbiEnt)、機器翻譯 (DiscourseMT) 三個任務上進行了測試。
4.1 提問真的有用嗎?
首先要確認的是,多問一句話真的能提升 Performance 嗎?作者比較了:
- Direct: 直接盲猜。
- Clarify: 系統提問,獲得答案後再回答。
- Disambig: 直接給定人工改寫的「完美無歧義指令」。
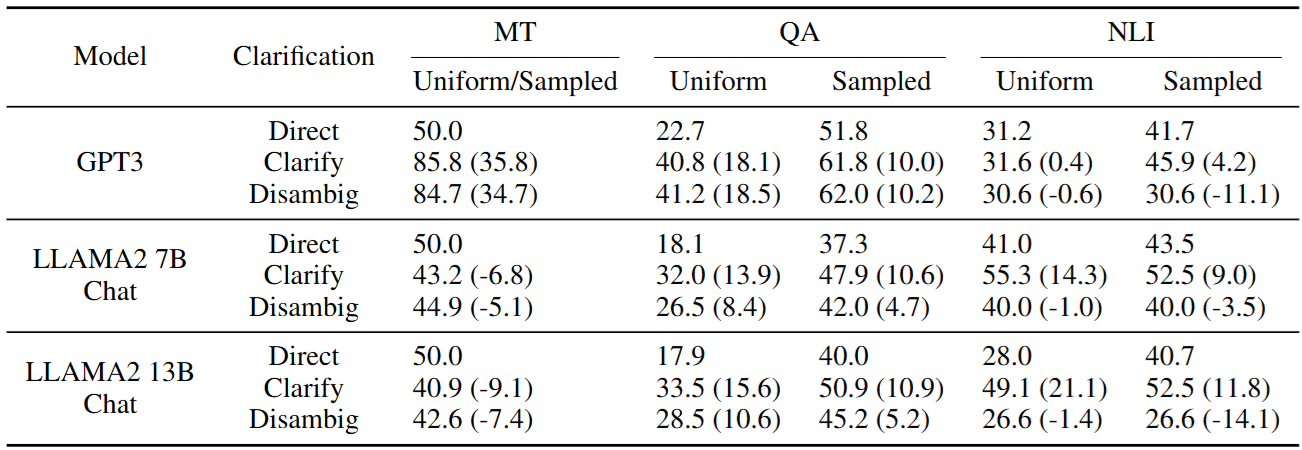
這裡有個非常有趣的發現:
在 Table 2 中,Clarify (一問一答) 的表現竟然經常優於 Disambig (直接給定完美句子) !
為什麼?作者推測,這是因為現在的 Chat 模型 (Instruction Tuned LLMs) 看過了海量的對話數據。相比於人工改寫的生硬長句 (Disambig) ,「問答互動」的形式更符合模型的訓練分佈。這給了我們一個 Prompt Engineering 的大啟發: 有時候把 Context 塞進對話歷史裡,比寫在 System Prompt 裡更有效。
4.2 誰最會抓時機?
在固定互動預算 (例如只能問 20% 的問題) 下,比較不同方法挑選題目的準確度 (AUROC) :
- Likelihood: 傳統方法,看 Logits。
- Self-Ask: 讓模型自己問自己「需不需要發問?」。
- INTENT-SIM (Ours): 本文方法。
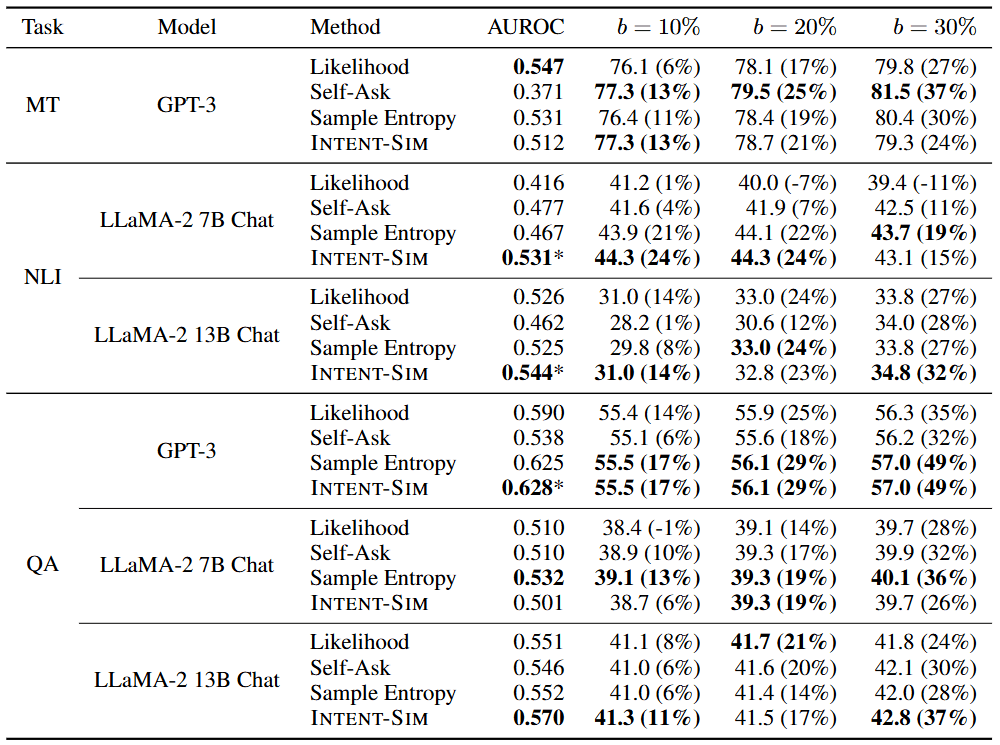
結果分析:
- Likelihood 的慘敗: 在 LLaMA-2 QA 任務上,Likelihood 的表現甚至不如隨機 (Random) 。這證實了「低信心 歧義」。
- INTENT-SIM 的勝利: 它之所以能贏,是因為它引入了「釐清問題 」這個中間變數,強迫模型將注意力集中在「歧義」上,而非「知識盲區」。
5 結論
這篇論文挑戰了 LLM 互動設計的一個預設假設 —— 「LLM 應該總是試圖直接回答」。INTENT-SIM 展示了如何讓 LLM 具備後設認知 (Metacognition) : 知道自己什麼時候該閉嘴,什麼時候該開口。
雖然 INTENT-SIM 很強,但要落地到產品中,有兩個坑要注意:
Latency: 要在 Runtime 生成 10 個回答還要跑 NLI Clustering,這在即時對話中絕對是災難。
- 解法: 建議採用 Cascade System。先用快速的 Likelihood 過濾掉 80% 顯然沒問題的 Case,只對那些處於「模糊地帶」的輸入啟動 INTENT-SIM。
Cost: 的 NLI 比對很貴。
- 解法: 如果是新聞分群等大規模任務,請乖乖用 Embedding (如 NV-Embed)。但在這種 One-shot 的決策場景,為了精確度,NLI 還是首選。