不再需要微調!MemRL 如何讓 AI Agent 透過強化學習實現「自我進化」?

1 前言
最近在跟幾個做 Agentic Workflow 的朋友聊天,發現到大家最頭痛的問題通常不是 LLM 推理能力不夠,而是 「Agent 沒辦法從錯誤中學習」。
目前的解決方案通常很兩極:要嘛是砸錢去做 Fine-tuning,結果遇到「災難性遺忘 (Catastrophic Forgetting) 」,新技能學會了,舊的邏輯卻壞掉;要嘛是掛一個傳統的 RAG,但 RAG 只會根據「語義相似度」去撈資料,撈出一堆看起來很像但其實沒用的垃圾 (Noisy Retrieval)。
難道就沒有一種方法,能讓 Agent 在不動模型權重 (Frozen LLM) 的前提下,像人類一樣「吃一塹,長一智」嗎?
今天要跟大家分享的這篇論文 《MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory》 ,就提出了一個非常優雅的解法。它把「記憶」這件事從單純的資料庫檢索,提升到了 強化學習 (Reinforcement Learning) 的決策層級。
- 核心挑戰:解決 Agent 在持續學習中的「穩定性 - 可塑性困境」,避免 Fine-tuning 的高成本與 RAG 的低效率。
- 理論創新:引入 M-MDP (Memory-Based MDP),將記憶檢索視為一種「可學習的策略」,並透過 GEM 理論 保證學習過程不會越學越笨。
- 雙階段機制:結合語義相似度 (Phase A) 與 Q-Value 價值評估 (Phase B) ,確保撈出來的經驗既「相關」又「實用」。
- Runtime 進化:Agent 在運行時動態更新記憶的「實用性得分 (Utility) 」,實現真正的自我進化。
2 為什麼現在的 Agent 總是「學不乖」?
在深入 MemRL 之前,我們先來吐嘈一下現有的兩條路徑:
- Fine-tuning (微調):這就像是為了讓員工學會一個新工具,直接對他進行開腦手術。成本高不說,最怕的是手術完他忘了怎麼走路 (參數分佈被破壞) 。這對需要不斷面對新場景的 Agent 來說,簡直是惡夢。
- 傳統 RAG (檢索增強生成):這是目前的主流,但它有一個致命傷 —— 「相似度 實用性」。
- 想像你在修水管,RAG 幫你翻出一本《如何修電力系統》,因為兩者都叫「系統修復」。這種語義上的接近,對於解決問題可能毫無幫助。
- 傳統 RAG 缺乏回饋閉環,系統根本不知道上次撈出來的 Prompt 到底有沒有幫到忙。
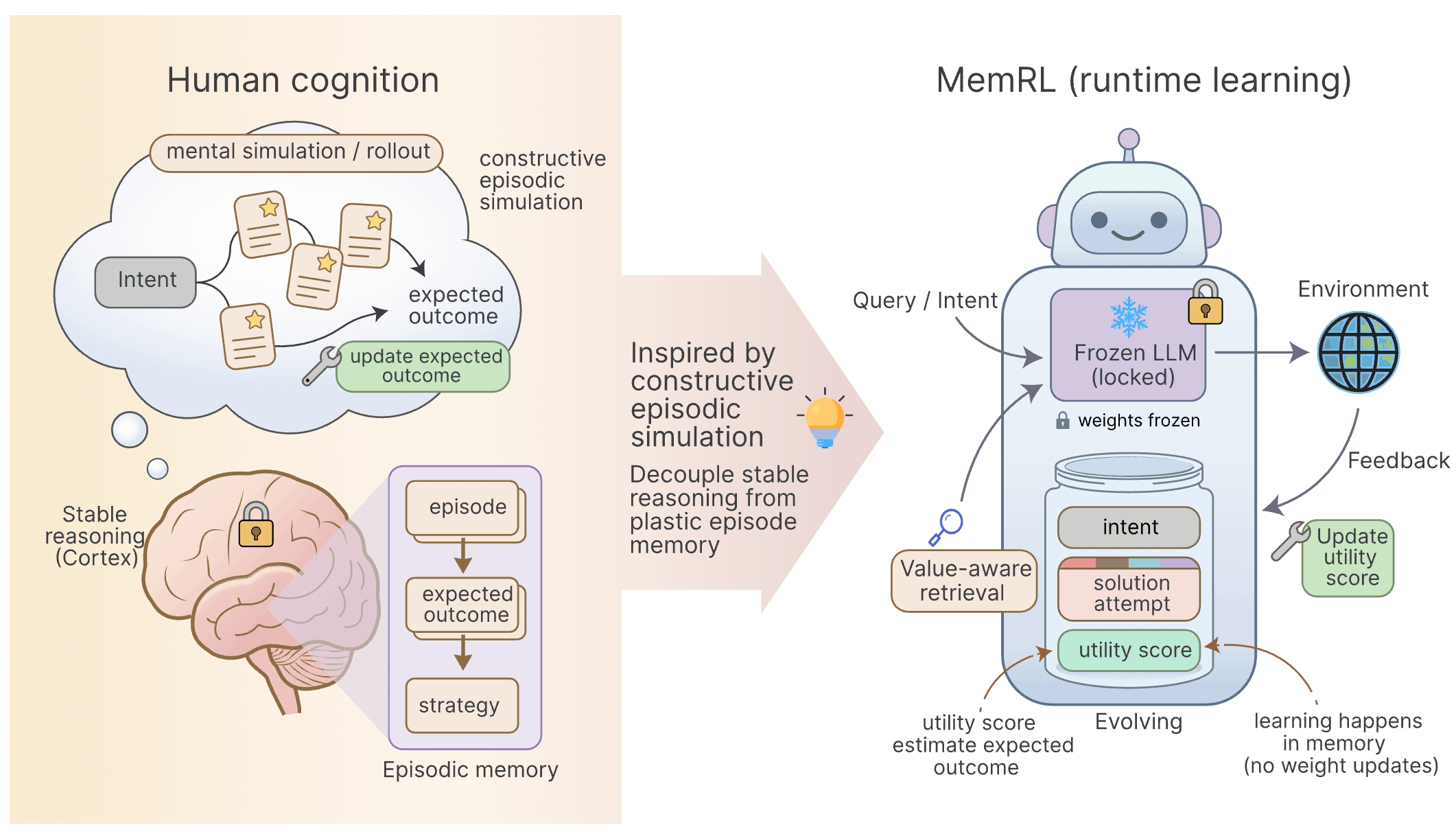
3 MemRL 的核心思維:把記憶當作「作弊筆記」
MemRL 的開發者提出了一個很有趣的轉向:與其修改大腦 (LLM) ,不如給 Agent 一本會自動更新「星級評等」的筆記本。
這本筆記本不再只是 Key-Value 結構,而是升級為 意圖-經驗-實用性三元組 (Intent-Experience-Utility Triplet):
- 意圖 ():你的問題是什麼? (作為索引)
- 經驗 ():上次是怎麼解決的? (具體的 Prompt 或步驟)
- 實用性 ():🔥 這是靈魂所在。 代表「在這種情況下,用這個經驗成功的期望值」。
傳統 RAG 就像一般的圖書館目錄,只能告訴你「這裡有本關於蛋糕的書」。 MemRL 的記憶庫則是 米其林指南:
- :分類是「法式甜點」。
- :具體的食譜。
- :星級評分 (過去 100 個人照著做,95 個人給好評) 。
4 技術細節:MemRL 是如何運行的?
MemRL 的運作可以拆解成兩個關鍵步驟:怎麼找 (檢索) 與 怎麼學 (更新)。
4.1 雙階段檢索 (Two-Phase Retrieval):不只要像,還要有用
為了兼顧檢索的效率與品質,MemRL 採用了漏斗式的篩選過程:
Phase A: Similarity-Based Recall 先用標準的 Embedding 相似度,從大海中撈出前 20% 相關的記憶。這一步是為了確保我們不會拿「修水管」的經驗去處理「寫 Python」的問題。
Phase B: Value-Aware Selection 這是重頭戲。系統會對候選記憶進行 Re-ranking,分數計算公式如下:
這裡使用了 Z-Score 正規化。為什麼?因為相似度通常在 0.7~0.9 之間,而 Q 值可能在 0~1 之間,不正規化的話,Q 值很容易被淹沒。透過這個公式,我們能選出那些「雖然相似度略低,但歷史成功率極高」的黃金經驗。
4.2 Runtime 實用性更新:吃一塹,長一智
當 Agent 執行完任務後,會根據環境給的 Reward () 來更新記憶。
- 更新舊記憶:使用 Q-Learning 的概念:。如果成功了,這個經驗的「星級」就往上調;失敗了就往下調。
- 寫入新記憶:Agent 會把這次的執行過程壓縮成精簡的經驗。
5 數學背後的保證:它會不會「學壞」?
很多人會擔心,這種不斷自我更新的機制會不會導致 Model 崩潰? 作者引入了 GEM (Generalized Expectation-Maximization) 理論來證明:只要有 Phase A 的語義約束 (作為 Trust Region) ,Agent 的預期回報會是 單調非遞減 (Monotonically Non-Decreasing) 的。簡單來說,它在數學上保證了只會越學越聰明,不會越學越笨。
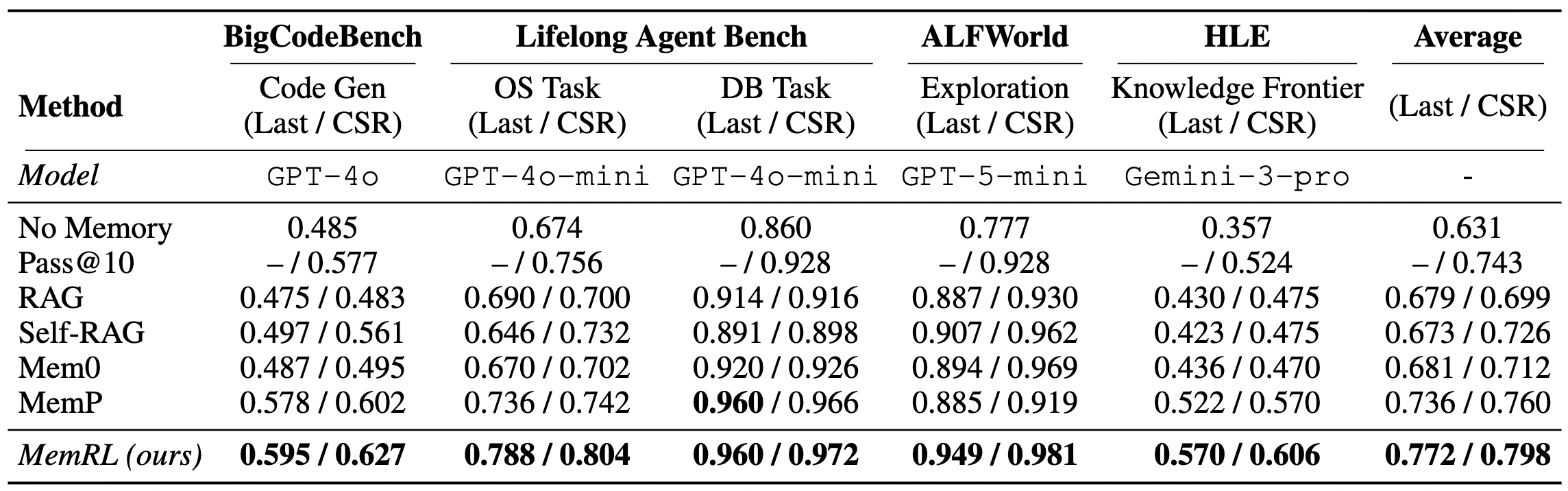
6 實驗結果:不僅是理論,實戰也超強
作者在 ALFWorld、BigCodeBench 以及難度極高的 HLE 進行了測試。
幾個有趣的觀察:
- 長期任務表現極佳:在需要多步驟規劃的 ALFWorld 和 OS Task 中,MemRL 的提升幅度最顯著。這證明了「記住成功路徑」對複雜決策非常有幫助。
- 抗遺忘能力強:實驗顯示 MemRL 的遺忘率 (Forgetting Rate) 極低且穩定。這解決了長期運行 Agent 最怕的「越用越笨」的問題。
- HLE 的驚人發現:在題目之間幾乎沒有相似度的 HLE 測試中,MemRL 的表現竟然也提升了許多。這代表系統學會了 「精準背誦」——對於極難的題目,Agent 透過 Q 值機制強行記住了正確答案,這在處理特定的 Edge Case 時非常強大。
7 結語
讀完這篇論文,我最大的啟發在於它 「重新定義了失敗的價值」。
在傳統的開發思維中,我們總是想盡辦法過濾掉錯誤。但在 MemRL 的架構裡,錯誤是被允許且被轉化的資產。 一個老練的工程師之所以厲害,不只是因為他知道怎麼寫對,更是因為他記得以前在哪裡跌倒過。
MemRL 透過一套優雅的數學框架 (M-MDP + GEM),在不改動 LLM 權重的情況下,賦予了 Agent 這種「老練」的智慧。如果你正在開發需要長期運行、持續進化的 Agent 系統,MemRL 的這種「非參數化強化學習」思路,非常值得借鑒。