[論文介紹] Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
1 前言
本篇文章介紹 Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory 論文,Mem0 是一個由 mem0.ai 公司所開發的 Agentic Memory 方法。雖然這篇論文在 2025 年 4 月才剛發布到 arXiv 上,但早在 2023 年 7 月第一版 Mem0 就已經在 GitHub 上釋出。
Mem0 的主要目的是要解決 LLM 在長期記憶 (Long-Term Memory) 上的問題,並且提供一個 Production-Ready 的解決方案。來到 Mem0 的 GitHub 頁面,相信你也會蠻吃驚的,Mem0 的 GitHub Stars 數量截至 2025 年 5 月 11 日已經超過 29K,這個專案的熱度著實不容小覷。
本篇文章將會著重在 Mem0 論文的介紹,理解 Mem0 的設計理念、架構以及實驗結果。Mem0 的 GitHub 上有提供詳細的使用說明,這邊就不再贅述。
2 Mem0 想解決的問題

Mem0 主要是希望解決 Agent 在長期記憶 (Long-Term Memory) 上的問題。當 Agent 缺乏長期記憶時,就無法記住過去與人類互動的經驗,就無法根據人類的偏好,提供最適合的回答。如上圖 Figure 1 左圖所示,當人類在對話的一開始告訴 Agent 自己是一位素食主義者,要避免含有奶製品的食物時,Agent 在對話的後期因為缺乏記憶能力而忘記這些資訊,導致提供的建議不符合人類的需求。相反的,在 Figure 1 右圖中,Agent 透過長期記憶的能力,能夠記住人類的偏好,並且在後續的對話中提供符合人類需求的建議。
即使現在的 LLM 的 Context Window 不斷的增加,仍然無法完全解決長期記憶的問題。Mem0 的作者提出以下三點:
- 隨著與人類互動的次數增加,累積的對話內容以及思考過程終究會超過 LLM 的 Context Window,導致 LLM 無法記住所有的資訊
- 人類與 LLM 的互動過程中,經常會跳脫不同主題的討論。換句話說,當今天人類詢問一個主題 A 的問題時,LLM 的 Context Window 卻充斥著各種主題 A 不相關的資訊,可能會影響 LLM 的回答
- 大多數 LLM 都是基於 Transformer 架構,Transformer 的 Self-Attention 機制除了會隨著 Context Window 的增加而增加計算的複雜度,表現也會隨之下降
3 Mem0 方法簡介
Mem0 主要包含以下兩種 Memory Architecture:
- Mem0: 單純透過 LLM 以及 Vector/Relational Database 來管理記憶
- Mem0g: 在 Mem0 的基礎上,加入了 Grpah-Based 的記憶結構
3.1 Mem0 的記憶管理方式
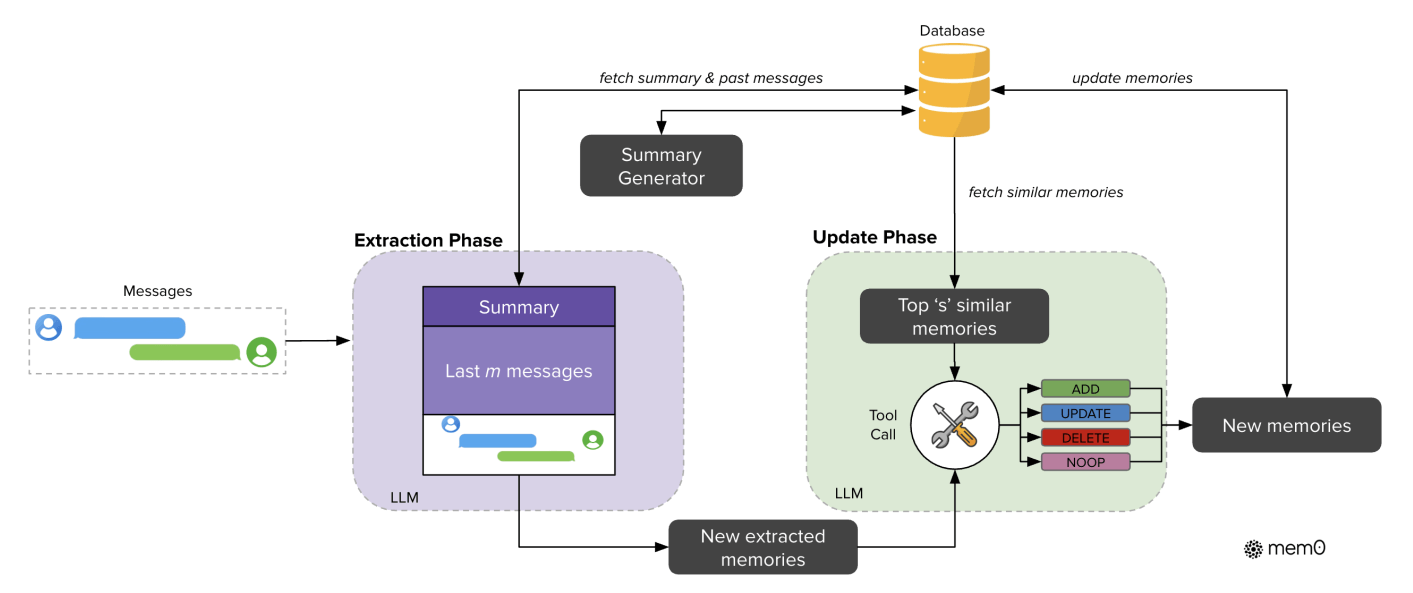
Mem0 的記憶管理方式如上圖 Figure 2 所示,主要分為兩個階段:Extraction Phase 以及 Update Phase。
- Extraction Phase: 從對話紀錄中,提取值得被記住的資訊
- Update Phase: 將這些新的資訊與既有的記憶進行比對,再對既有記憶進行更新或是刪除
具體來說,在 Extraction Pahse 中,會由一個 LLM 根據以下資訊,提取出一些 Candidate Fact,也就是有機會成為記憶的新資訊:
- 過去長時間的對話摘要 (Summary): 這個摘要由另外一個 LLM 根據資料庫中所儲存的對話紀錄定期產生
- 過去 M 則對話紀錄: 代表最新的 M 則對話紀錄,也是 Extraction Phase 要提取 Candidate Fact 的來源
而在 Update Phase 中,每個 Candidate Fact 都會與既有的記憶進行比對,確保記憶資料庫中的一致性。具體來說,針對每一個 Candidate Fact,都會從資料庫中取出與其 Embedding 最相似的 K 個 Retrieved Memory,然後將這些 Retrieved Memory 與 Memory Candidate 進行比對。
比對的方式是透過一個 LLM 以 Function-Calling 的方式,來決定要進行以下哪一種操作:
- ADD: 由於這個 Candidate Fact 是全新的資訊,因此將 Candidate Fact 加入到記憶資料庫中
- UPDATE: 透過 Candidate Fact 來更新資料庫中已經存在的記憶
- DELETE: 由於資料庫中已經存在的記憶與 Candidate Fact 是矛盾的,因此將資料庫中的記憶刪除
- NOOP: 不做任何操做
作者在後續的實驗階段中,在 Extraction Phase 會取 M = 10 作為最新的對話紀錄。在 Update Pahse 中,會取 K = 10 作為 Retrieved Memory。 在兩個階段所使用的 LLM 都是 GPT-4o-mini。
3.2 Mem0g 的記憶管理方式
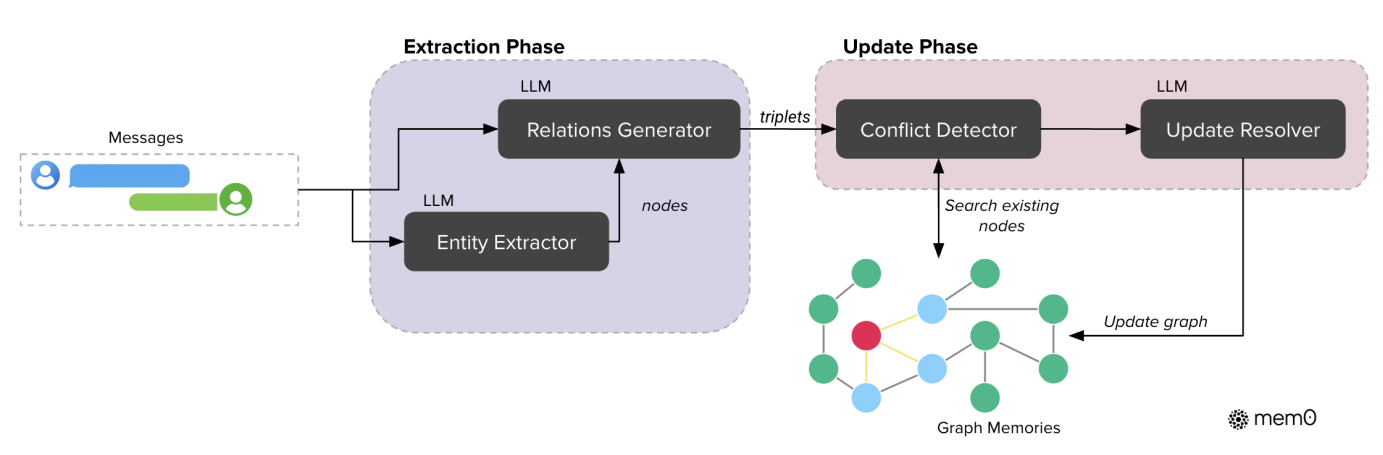
從上圖 Figure 3 可以看到,Mem0g 與 Mem0 的 Memory Architecture 相當類似,兩者都有 Extraction Phase 以及 Update Phase。不同的地方在於 Mem0g 是以 Graph-Based 的方式來管理記憶,而 Mem0 則是以 Vector/Relational Database 的方式來管理記憶。
在 Mem0g 中,Memory 會透過一個 Graph 來表示,一個 Graph 會包含 Node , Edge 以及 Label 。具體來說:
- Node : 代表實體 (Entity),例如:Alice, San Francisco
- Edges : 代表實體之間的關係 (e.g., lives_in)
- Labels : 代表實體的語意類型 (e.g., Alice - Person, San Francisco - City)
每個 Entity Node 包含三個組成部分:
- Entity 的類別 (例如:Person, Location, Event)
- Entity 的 Embedding ,捕捉實體的語意
- Entity 的 Metadata,包括創建時間
在 Mem0g 中,Node 之間的關係會透過一個 Triplet 表示,其中 和 是 Source Node 和 Target Node, 是連接它們的 Edge。
在 Extraction Phase 中,會透過 LLM 進行兩階段的處理:Entity Extraction 以及 Relationship Generation。
Entity Extraction 就是透過一個 Extity Extractor LLM 來從對話紀錄中提取出所有的 Entity,並且標示出這些 Entity 的類型。例如,如果對話內容是討論與旅遊相關的主題,那麼 Entity 就可能是「出發地點」、「目的地」、「出發時間」等。這些 Entity 會被轉換成 Graph 中的 Node,並且會被標示上類別 (Label),例如「出發地點」的類別可能是「Location」,而「出發時間」的類別可能是「Date」。
Relationship Generation 則是透過一個 Relationship Generator LLM 來從對話紀錄中提取出所有的 Entity 之間的關係,並且標示出這些關係的類型。例如,如果對話內容是討論與旅遊相關的主題,那麼 Entity 之間的關係就可能是「出發地點」和「目的地」之間的關係是「Travel From-To」,而「出發時間」和「目的地」之間的關係是「Travel Date」。
在 Update Phase 中,則是根據目前新建立的 Triplet ,比較 Source Node 以及 Target Node 與 Graph 中既有的 Node 的 Embedding,從 Graph 中取出與這兩個 Node 較為類似的 Node,然後透過 Conflict Detection 以及 Update Resolver 來決定要將新的 Source Node 以及 Target Node 都加入到 Graph 中,還是只加入一個 Node,或是都不加入僅更新 Graph 中的資訊。
在 Mem0g 中,採用兩種 Memory Retrieval 的方式:
- Entity-Centric Approach: 基於一個 Query,先分析 Query 中的 Entity,然後從 Graph 中取出與這些 Entity 相關的 Node,並將這些 Node 既有的 Relationship 建立一個 Subgraph,這個 Subgraph 就是代表這個 Query 的 Relevant Contextual Information。
- Semantic Triplet Approach: 基於一個 Query,先將這個 Query 轉為一個 Dense Embedding,再拿這個 Embedding 與 Graph 中所有 Triplet 的 Textual Encoding 的 Embedding 進行比對,取出最相似的 K 個 Triplet,這 K 個 Triplet 就是代表這個 Query 的 Relevant Contextual Information。
在實驗階段中,作者使用 Neo4j 作為 Graph Database,並且使用 GPT-4o-mini 作為 Entity Extractor LLM 以及 Relationship Generator LLM。
4 Mem0 的實驗結果
4.1 測試資料集的選擇
作者選用 LOCOMO 資料集作為 Benchmark,LOCOMO 專門用來為評估對話系統中模型的長期記憶能力。LOCOMO 包含 10 個 Conversation,每個 Conversation 平均包含 600 則對話(平均約為 26K 個 Tokens)。每個 Conversation 平均有 200 個問題及其對應的標準答案。這些問題被分為多種類型:Single-Hop, Multi-Hop, Temporal (時間相關)以及 Open-domain。
4.2 衡量指標上的選擇
除了基本的 F1 Score (F1) and BLEU-1 (B1) 之外,作者再加入 LLM-as-a-Judge (J) 來提昇衡量的準確性。這三個指標都是衡量 LLM 的輸出與 Groundtruth 之間是否足夠一致。
除了上述指標外,作者也加入了 Token Consumption 來衡量不同的方法平均在處理每一個 Query 時,需要從 Memory Database 中題取出多少 Tokens (這些 Tokens 會變成 LLM 的輸入),以及 Latency 來衡量不同的方法平均在處理每一個 Query 時,所需要的時間。
4.3 實驗結果
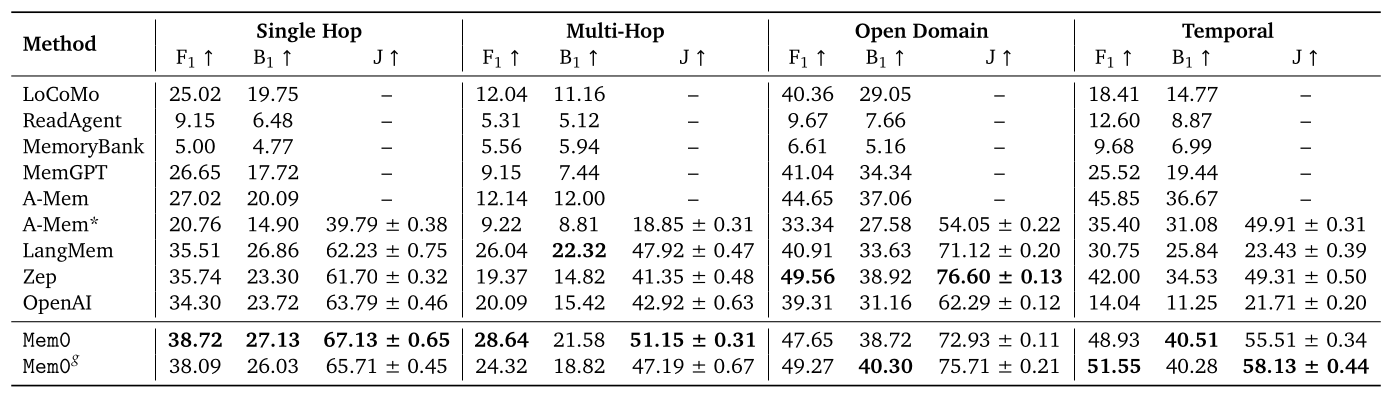
從 Table 1 的實驗數據中,令我感到相當的驚訝,Mem0 的表現不只在 Single-Hop, Multi-Hop 以及 Temporal 上都達到的 State-of-the-Art (SOTA) 的表現,而且在三個指標上都比第二名高出許多。在 Open-domain 上,雖然不是 SOTA,但是與第一名相較起來也只有一點點落差。
LOCOMO 這個 Benchamrk 的有效性也在 Reddit 上被討論。有人認為 LOCOMO 這個資料集是有一些問題存在的,稍微修改一些實驗設定 Zep 的表現甚至超越 Mem0 24%,又或者是許多鄉民認為 Mem0 的實驗設定有問題,才導致 Mem0 遠遠勝過其他的方法。
此外,第二個值得注意的點是,Mem0g 相對於 Mem0 加入了 Graph-Based 的結構來儲存記憶,設計更複雜的 Extraction Phase 以及 Update Phase,然而卻只有在 Open-Domain 與 Temporal 的類別上表現的比 Mem0 好。作者針對原因並沒有做太深入的分析。
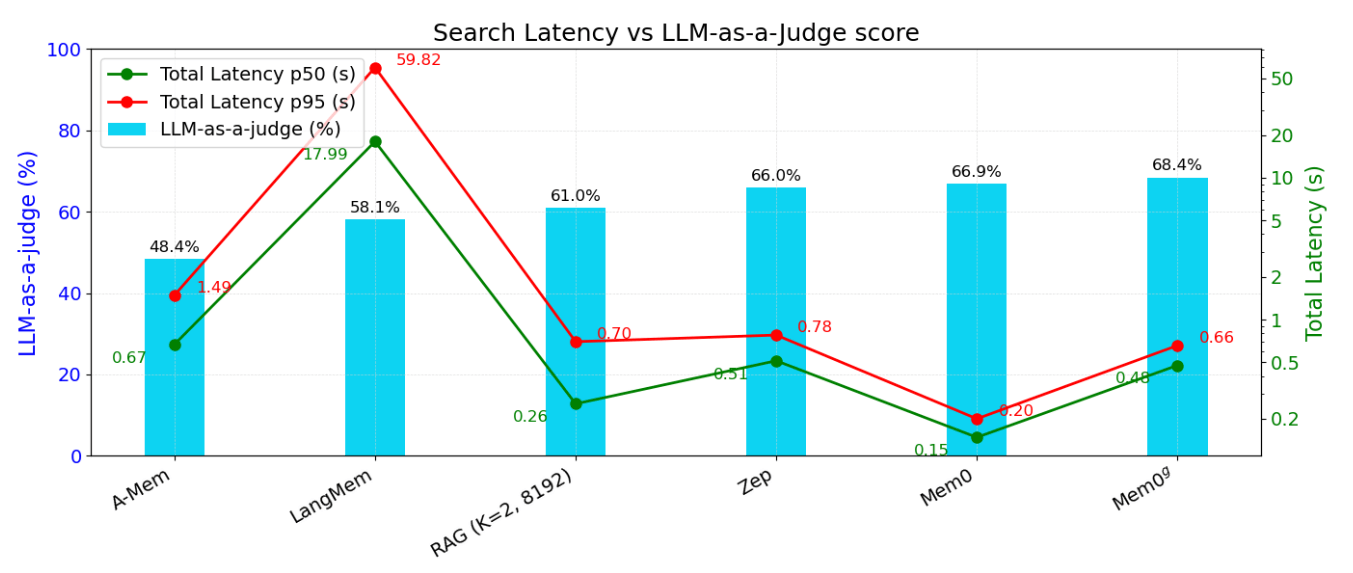
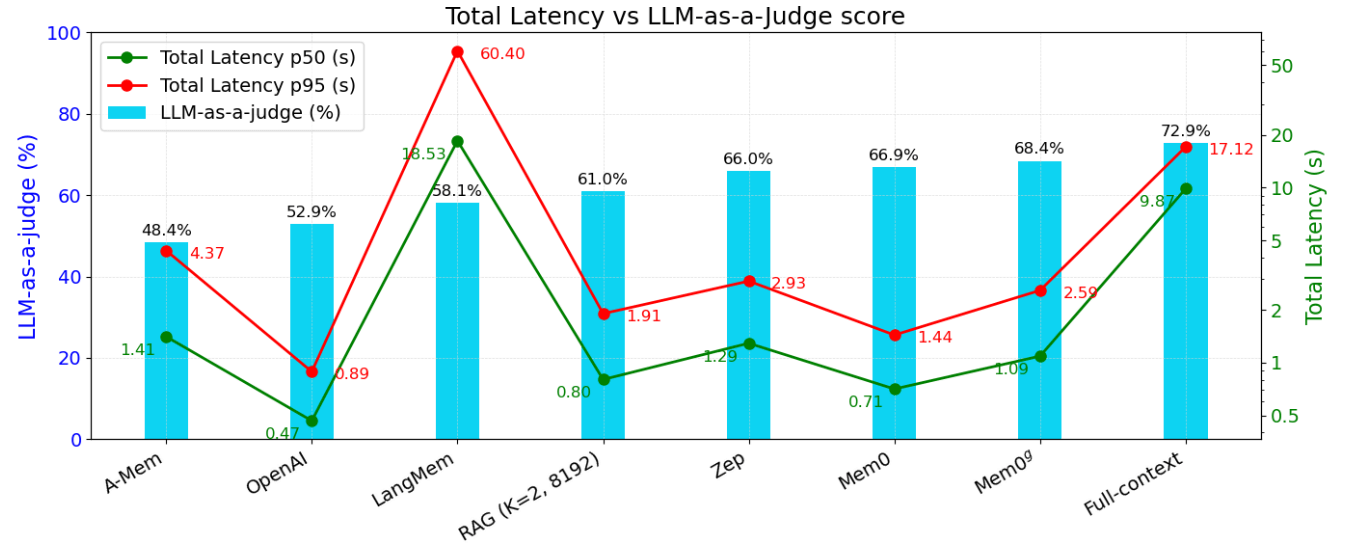
上圖的 Figure 4a 與 Figure 4b 分別是針對不同方法衡量在 LOCOMO 整體資料集上的 LLM-as-a-Judge Score, Search Latency 以及 Total Response Latency 的表現。可以發現到 Mem0 和 Mem0g 在 Latency 以及 LLM-as-a-Judge 的分數上展現了很強的優勢。
5 結語
本篇文章介紹 Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory 論文,了解 Mem0 與 Mem0g 是如何從原始的對話紀錄透過 Extraction Phase 與 Update Phase 來管理長期記憶;以及 Mem0g 如何透過 Graph-Based 的結構來儲存記憶。
從作者選擇的 LOCOMO 測試資料集上,我們看到了 Mem0 與 Mem0g 在 Single-Hop, Multi-Hop 等多個面向都勝過 Baseline 方法,也看到 Mem0 與 Mem0g 在 Latency 上相較於其他方法的優勢。
在論文中並沒有詳細的呈現 Mem0 與 Mem0g 中所使用的 Prompt,但是從 GitHub 上找到兩個 Prompt 檔案,有興趣的讀者可以再研究看看:
- Mem0: mem0/configs/prompts.py
- Mem0g: mem0/graphs/utils.py