[論文介紹] MemGPT: Towards LLMs as Operating Systems

1 前言
本篇文章介紹 MemGPT: Towards LLMs as Operating Systems 論文,MemGPT 由 UC Berkeley 的研究人員於 2023 年 10 月被發布到 arXiv 上,截至 2025 年 5 月 14 日已經累積了 154 次 Citation,目前被收錄在 CoRR 2023。
談到 LLM 的 Perceptual Conversation 或是 Long-Term Memory,MemGPT 也算是一篇經典之作,目前 MemGPT 所開源的專案稱為 Letta,與其說是一個專案我覺得它倒是更像一間新創公司。
此外,截至 2025 年 5 月 14 日,Letta 目前在 GitHub 上已經累積了 16.4K 個 Star,代表它確實是一個相當熱門的專案。當我們在網路上搜尋 Agent Memory 相關的開源專案時候,除了 Mem0 之外,Letta 也是一個受歡迎的選擇,甚至大大超越由 LangChain 所開源的 LangMem。
身為 AI 領域的工程師或研究者,如果你還不了解 Mem0 以及 LangMem 的概念,務必閱讀以下兩篇文章:
本篇文章為 DeepLearning.AI 上 LLMs as Operating Systems: Agent Memory 的課程筆記,主要著重於介紹 MemGPT 的方法本身,而不會提及實驗結果等細節,有興趣的讀者再請自行閱讀原論文!
2 MemGPT 想解決的問題
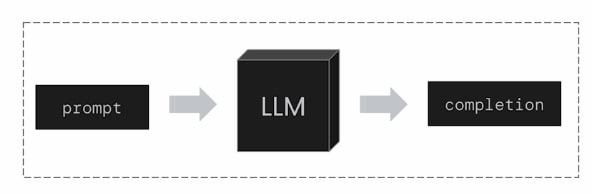
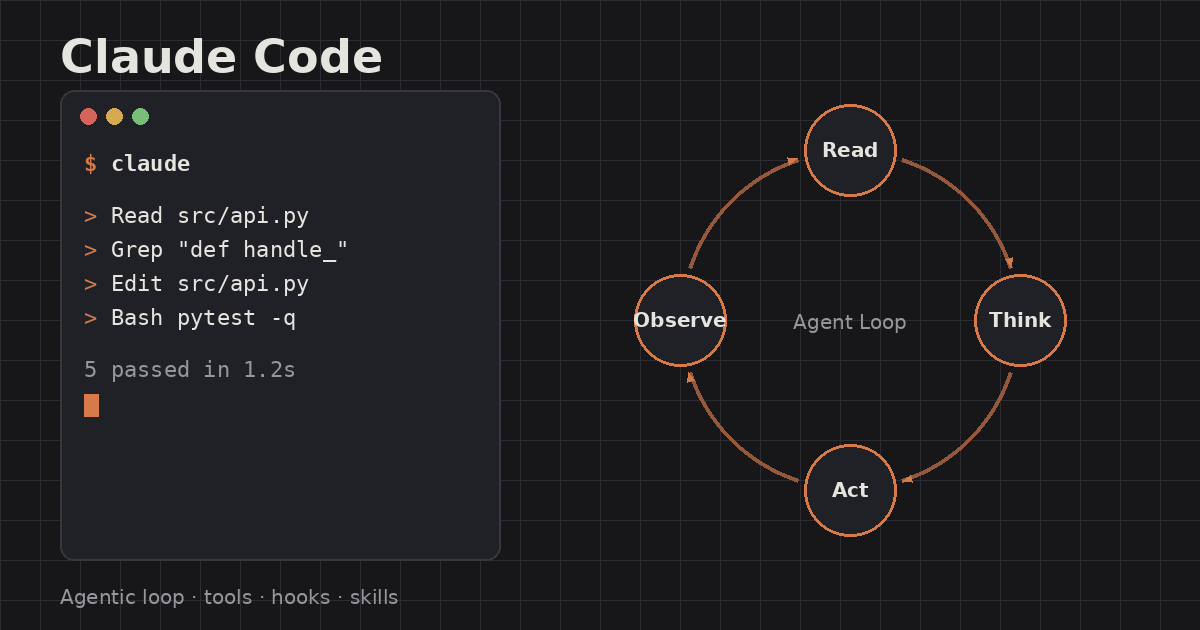
如上圖所示,基於我們的 Prompt,LLM 會以 Auto-Regressive 的方式進行「文字接龍」產生 Completion。如果這一個 LLM 是一個你所開發的 Chatbot,專門解決你的客戶的疑難雜症,那麼你可能會在 Prompt 中提供:客戶的資訊, Chatbot 與客戶的對話紀錄, 外部資料, Chatbot 能夠使用的工具, Chatbot 已經經過的 Reasoning Steps 以及 Observation …
隨著 Chatbot 與客戶的互動時間變長,可以想像的是,Prompt 再也容不下這麼多資訊。即使你是用的是一個 Context Window 非常大的 LLM,也會發現隨著 Context Window 中的資訊愈來愈多,LLM 似乎開始出現失憶的狀況。
因此,LLM 在進行長時間的對話任務時,所經常面對的挑戰就是如何有效的管理「長期記憶」,這也正式 Mem0 與 LangMem 等方法所處理的問題。
3 MemGPT 的核心概念
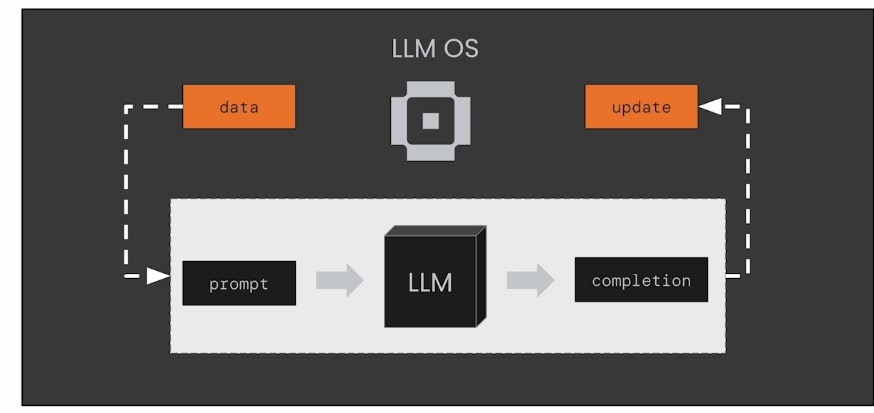
同理,MemGPT 也是為了處理這樣的問題而誕生!如上圖所述,MemGPT 的核心概念,正是希望透過 LLM 打造一個作業系統(Operating System)來管理自己的狀態,決定要把什麼資訊放到 Prompt 中。
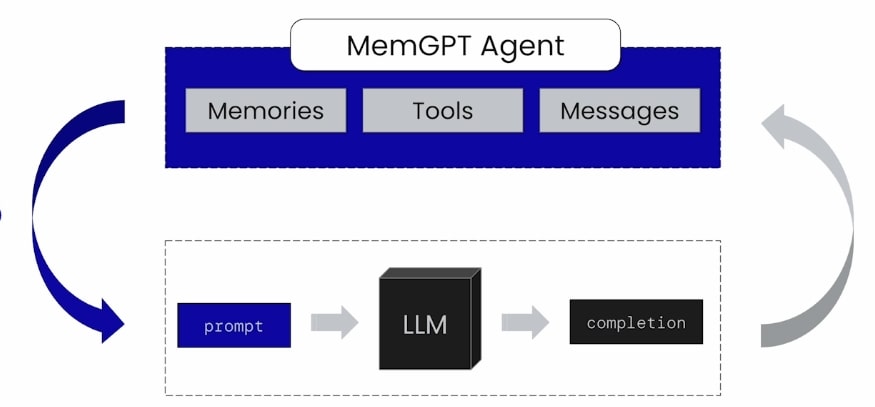
舉例來說,如上圖所示,對於一個 Agent 而言,它目前的狀態 (State) 可以由它的記憶 (Memories), 能夠使用的工具 (Tools) 以及對話紀錄 (Messages) 來表示。可以想像 Agent State 裡頭存放著與 Agent 本身的所有資訊。
而賦予 Agent 對話能力的即是 LLM 模型,LLM 模型的 Context Window 有所限制,導致我們沒辦法把整個 Agent State 都放到 Prompt 裡面。
為了賦予 MemGPT 有這樣的能力,MemGPT 被設計出以下四個特色:
- Self-Editing Memory: Agent 能夠透過 Tool Calling 修改自己的記憶內容
- Inner Thoughts: Agent 每次在輸出之前都可以進行一些思考,而這些思考過程不會輸出給使用者
- Every Output as Tool: Agent 的所有輸出都是 Tool Calling (Inner Thought 除外),就連要輸出資訊給使用者時,都要使用
send_message()工具 - Looping via Heartbeats: Agent 每次在 Tool Calling 時,都可以指定
request_heartbeat這個參數,來自己決定要不要再拿 Tool 的執行結果 Invoke 自己一次,來得到新的輸出
4 MemGPT 的記憶管理方式
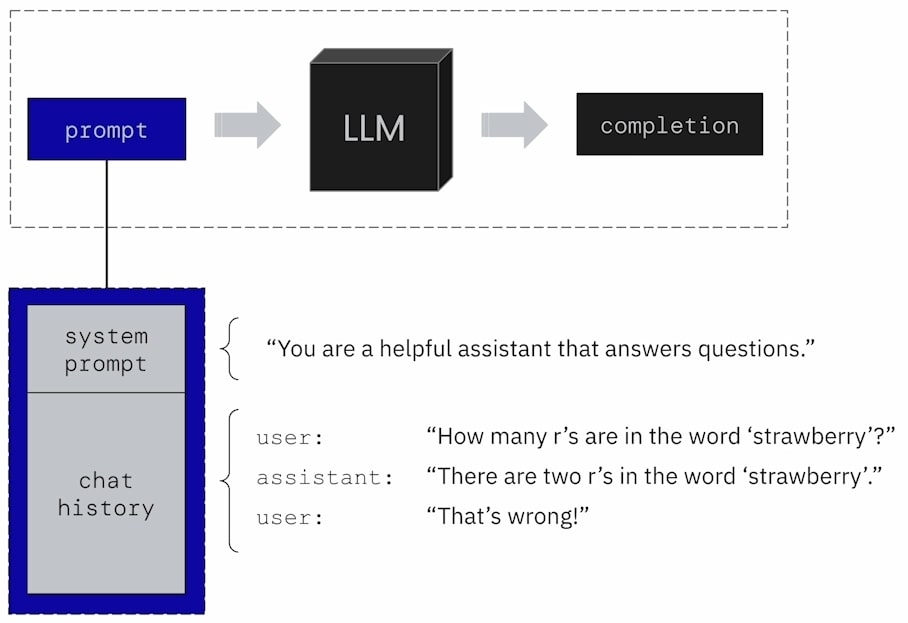
如上圖所示,在一般的 Agent 中,Prompt 的組成通常都是 “System Prompt” 加上 “Chat Hostory”。而在 MemGPT 中,為了做好 Prompt Compilation,將 Prompt 的組成分成很多特別保留區塊 (Special Reserved Section),作為不同資訊存放的目的。
4.1 MemGPT 的 Core Memory
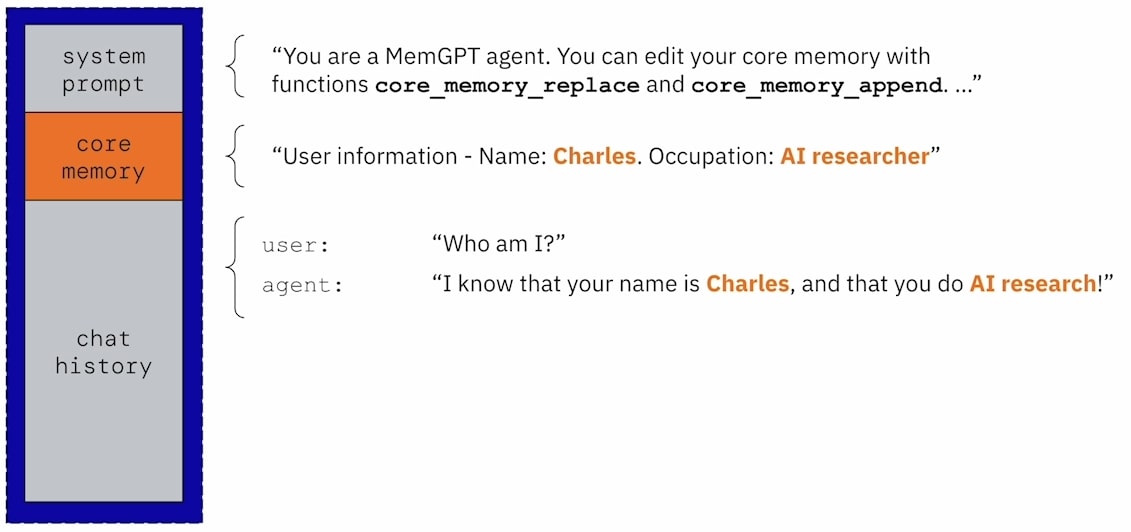
MemGPT 在 Prompt 中規劃了一個 Core Memory 區塊用來保存最重要的少量資訊,Core Memory 中可以分成很多 Block,每個 Block 可以保存不同的資訊 (例如:使用者資訊, Agent 自己的 Persona 等等)。
為了讓 LLM 本身知道有這個區塊的存在,會在 System Prompt 的區塊中紀錄 Core Memory 相關的資訊,包含可以透過一些 Tool 來修改 Core Memory 中的資訊 (例如:core_memory_replace, core_memory_append)。
當接收到使用者的輸入後,MemGPT 會先進行 Inner Thought 後再輸出。如同上文所述,MemGPT 的所有輸出都會是 Tool Calling,因此如果在 Inner Thought 中 MemGPT 覺得這個資訊值得被紀錄在 Core Memory,那這一次的輸出就會是一個 core_memory_append 的 Tool Calling,來將此資訊紀錄到 Core Memory 中。
4.2 MemGPT 的 Chat History
如上圖所示,MemGPT 在 Prompt 中除了規劃一個 Core Memory 之外,還會有一個區塊來放置 Chat History。這裡的 Chat History 就是 MemGPT 與使用者互動的 Multi-Turn Conversation。
當 Conversation 的內容超過 Chat History 區塊大小的限制時,MemGPT 會將一個 Chunk 的 Chat History 透過 LLM 轉為 Chat Summary,並將 Chat Summary 取代原本的 Chunk。
這個 Chunk 的大小可以透過 desired_memory_token_pressure (letta/letta/settings.py) 來控制,在 calculate_summarizer_cutoff (letta/letta/llm_api/helpers.py) 中就會透過這個參數來計算有多少 Token 需要被 Summarize。
在 MemGPT 中,LLM 所生成的 Chat Summary 實際上是一種 Recursive Summary,因為 LLM 在對 Chunk 生成 Summary 時, Chunk 中可能也會包含前一次的 Chat Summary。
4.3 MemGPT 的 Recall Memory
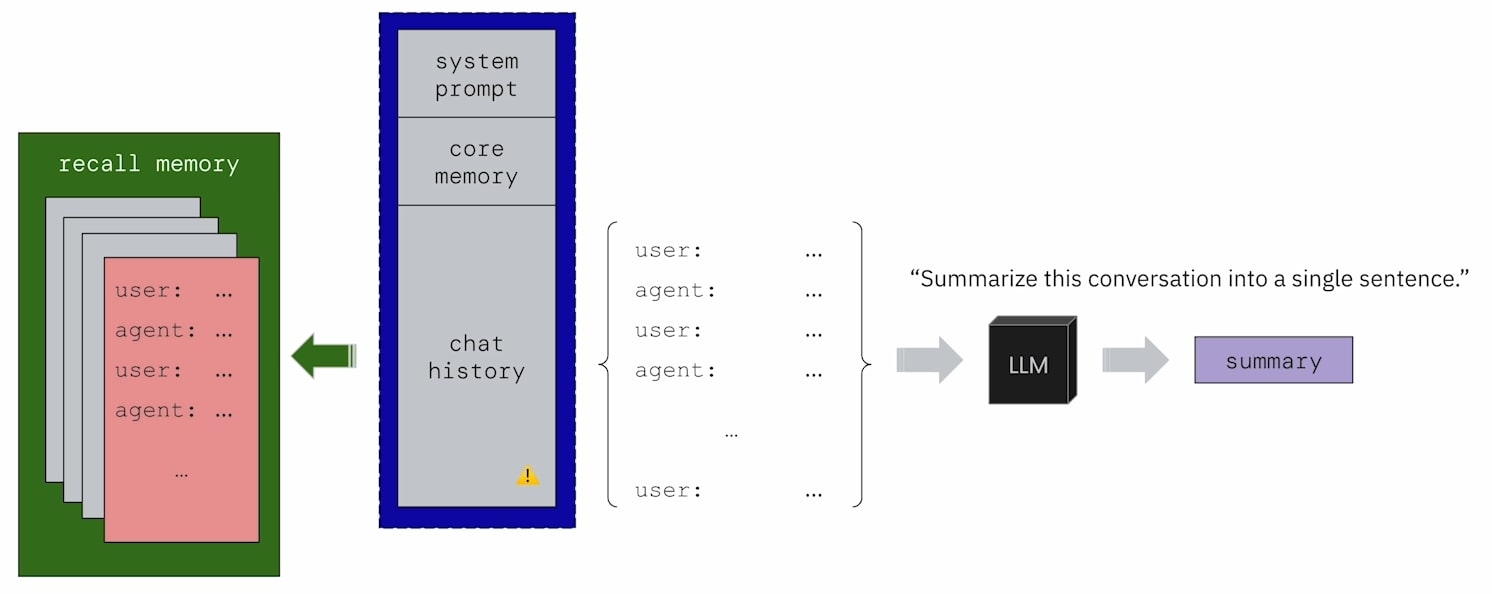
承接 MemGPT 的 Chat History,被 Summarize 的 Chunk 並不會被丟棄,而是會存入一個外部的 Database,我們稱其為 Recall Memory。換句話說,MemGPT 與使用者所有的對話紀錄都不會遺失,全部都會存在 Recall Memory 中。
既然它是一種 Memory,那勢必就能夠從中查找資訊。沒錯!MemGPT 的 System Prompt 中也會告訴 MemGPT 能夠透過 conversation_search 的 Tool 來從 Recall Memory 中查找資訊。
4.4 MemGPT 的 Archival Memory

既然 Chat History 有自己的外部 Database, Recall Memory, 來儲存 Chat History 放不下的資訊,那麼 Core Memory 當然也有自己的外部 Database 來儲存 Core Memory 放不下的資訊。我們稱其為 Archival Memory。
MemGPT 與使用者的互動過程中,如果覺得某一個資訊 (例如:使用者的喜好) 需要被記住,然而 Core Memory (例如:Core Memory 中的 “User” Block) 已經滿了,這時候 MemGPT 可以根據這個資訊的重要程度,進行以下兩種操作:
- 新的資訊很重要:將 Core Memory 中的內容搬到 Archival Memory,然後把這個新的重要資訊存到 Core Memory
- 新的資訊沒那麼重要:直接將新的資訊存到 Archival Memory
Archival Memory 的用途除了可以當 Core Memory 的額外的外部儲存空間之外,也是 RAG (Retrieval-Augmented Generation) 應用中,外部資料會存放的地方。也就是說,當使用者希望 MemGPT 可以根據一份 PDF 回答問題時,這份 PDF 就會被存放在 Archival Memory 中。
當然,在 MemGPT 的 System Prompt 中,我們也會告訴 MemGPT 可以透過 archival_memory_search 的 Tool,來查找 Archival Memory 中的資訊。
4.5 MemGPT 的 A/R Stats
到目前為止,我們已經了解到 MemGPT 有兩個外部的 Database:Archival Memory 和 Recall Memory,分別作為 Core Memory 以及 Chat History 的額外儲存空間。
然而,這兩個外部儲存空間的資訊不會在 MemGPT 的 Context 中,MemGPT 要如何知道他們的狀態呢?
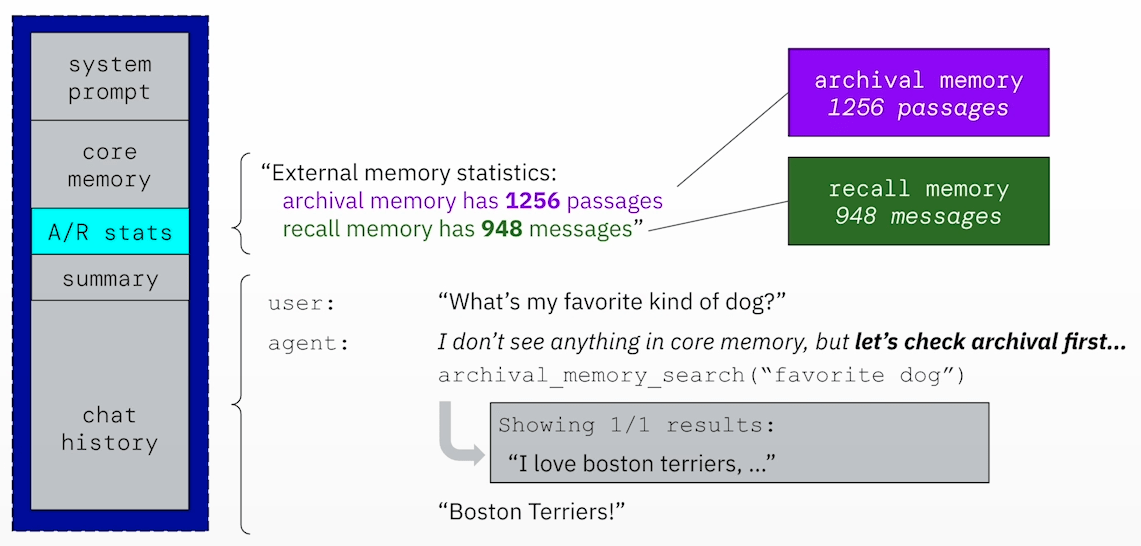
在 MemGPT 中,透過在 Context 中加入一個 A/R Stats 區塊,來紀錄 Archival 與 Recall Memory 中目前的資訊量,得以讓 MemGPT 判斷是否該去兩個 Memory 中查找資訊。
舉例來說,當 Archival 與 Recall Memory 中有存放一些資訊時,透過 A/R Stats,MemGPT 就知道可以去兩個 Memory 中查找資訊:
5 結語
本篇文章介紹 MemGPT: Towards LLMs as Operating Systems 論文,內容主要為 LLMs as Operating Systems: Agent Memory 的課程筆記。
MemGPT 想處理的挑戰就是 Prompt Compilation:如何將大量資訊從 Agent State 精鍊到 Prompt,讓 LLM 基於 Prompt 成功產生正確的輸出。
為了克服此挑戰,MemGPT 將 LLM 的 Context Window (Short-Term Memory) 分為多個區塊,包含 System Prompt, Core Memory, A/R Stats, Chat Summary 以及 Chat History。並設計兩種 Long-Term Memory: Archival Memory 以及 Recall Memory 分別作為 Core Memory 以及 Chat History 的額外儲存空間。
此外,MemGPT 也讓 LLM 以 ReAct-Based Agent 的方式,透過連續循環的 Thinking, Action (Tool Calling), Thinking, Action (Tool Calling)…, 來從不同的 Memory 中查找與精鍊資訊。
最後,以 Long/Short-Term Memory 的角度來看,MemGPT 與 LangMem, Mem0 相似的地方在於, 他們都有針對 Long-Term Memory 提出自己的方法,但比較特別的是 MemGPT 針對 Short-Term Memory (LLM 的 Context Windows) 中應該放置什麼樣的內容有更多的設計與著墨。