[論文介紹] MIRIX: Multi-Agent Memory System for LLM-Based Agents

1 前言
本篇文章介紹 MIRIX: Multi-Agent Memory System for LLM-Based Agents 論文。如標題所述,MIRIX 是一篇與 LLM Memory 相關的論文,類似於我們之前介紹過的 LangMem, Mem0 與 MemGPT。 MIRIX 論文於 2025 年 7 月發表於 arXiv,作者有開源程式碼,也可以在 MIRIX 的官方網站上直接下載基於本篇論文的方法所開發出來的軟體。
有趣的是,在 MIRIX 的官方網站上,除了提供軟體的下載之外,還直接秀出了多個方法在 LOCOMO 與 ScreenshotVQA 的 Benchmark 結果,可以發現 MIRIX 所提出的方法不只贏過 LangMem, Mem0, Zep 等等熱門的方法,也是少數能夠支援 Image 作為 LLM Memory 的方法。
2 MIRIX 方法設計
MIRIX 的方法設計大致上可以分為以下 3 個面向:
- Memory Component Design
- Memory Update Workflow
- Conversation Workflow
2.1 Memory Component Design
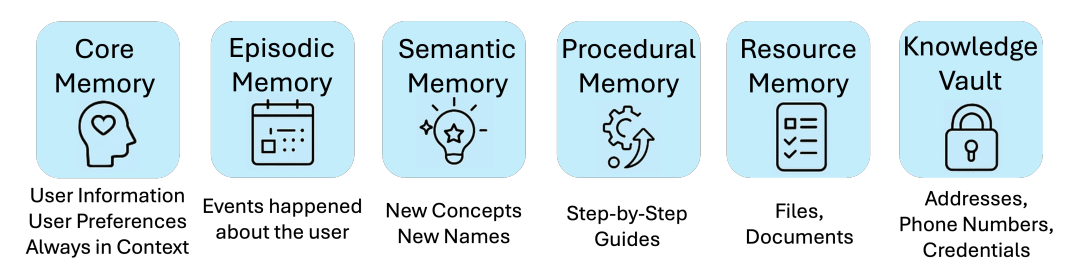
如上圖所示,在 MIRIX 中共定義了 6 種 Memory Component,這些 Memory Component 似乎是總和了 LangMem 與 MemGPT 中所設計的 Memory Component。舉例來說,在 LangMem 中一樣有 Episodic, Semantic 以及 Procedural Memory;而 Core Memory 與 Resource Memory 則可以對應到 MemGPT 中的 Core Memory 與 Archival Memory。
以下說明每一種 Memory Component 所存放的資訊:
- Core Memory: 存放最重要的資訊。模仿 MemGPT 的作法,在 Core Memory 中存放 2 個區塊:
persona與human。在persona區塊中,存放 Agent 自己的身份, 語氣, 應該有的行為,而在human區塊中,則存放使用者的身份資訊。 - Episodic Memory: 存放具有時間戳記的事件。每個 Entry 由以下內容所組成:
event_type: 例如user_message,inferred_result或是system_notificationsummary: 對事件的簡短描述details: 對事件的詳細描述actor: 事件發起人, 可以是user或assistant)timestamp: 例如2025-03-05 10:15
- Semantic Memory: 存放一些既定的事實或是通用的資訊。例如:“Harry Potter is written by J.K. Rowling” 或是 “John is a friend of the user who enjoys jogging and lives in San Francisco."。除非被特別移除或改寫,否則 Semantic Memory 中所存放的資訊是不會過期的。每個 Entry 由以下內容所組成:
namesummarydetailssource
- Procedural Memory: 存放一些幫助 Agent 解決複雜且特定任務的資訊。舉例來說,提供給 Agent 的 Few-Shot Demonstration 或是 Step-by-Step 的 Instructions。每個 Entry 由以下內容所組成:
entry_type: 可以是workflow,guide或是scriptdescription: 針對要完成的任務的描述steps: Step-by-Step 的 Instructions 來完成該任務
- Resource Memory: 存放使用者需要但是不屬於上述任何一類的所有資訊。每個 Entry 由以下內容所組成:
titlesummaryresource_type: 例如doc,markdown,pdf_text,image,voice_transcriptfull content/excerpted content
- Knowledge Vault: 存放一些機密與敏感資訊,例如使用者的住址,聯絡資訊, API Key。每個 Entry 由以下內容所組成:
entry_type: 例如credential,bookmark,contact_info,api_keysource: 例如user_provided,githubsensitivity:low,medium,highsecret_value
2.2 Memory Update Workflow
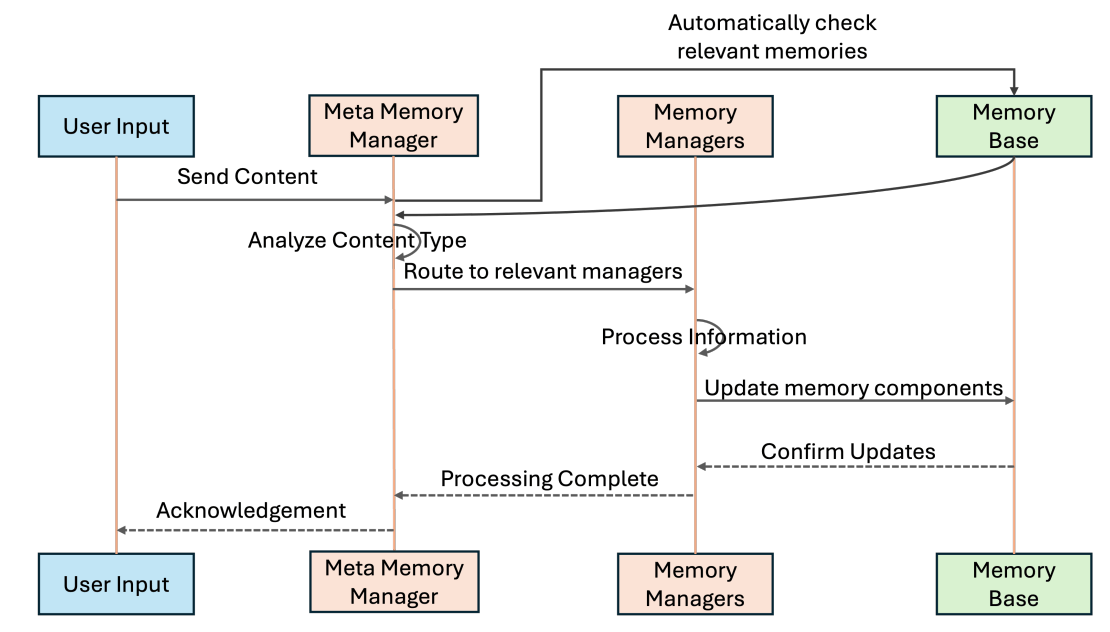
上圖呈現的是 MIRIX 方法下的 Memory 是如何被更新的:基於使用者輸入的內容,先從 6 種 Memory Component 中取出相關資訊。由 Meta Memory Manager 判斷目前使用者所輸入的內容應該屬於哪一種 Memory Component,再指派給該 Memory Component 的 Memory Manager 進行 Memory Update。
2.3 Conversation Workflow
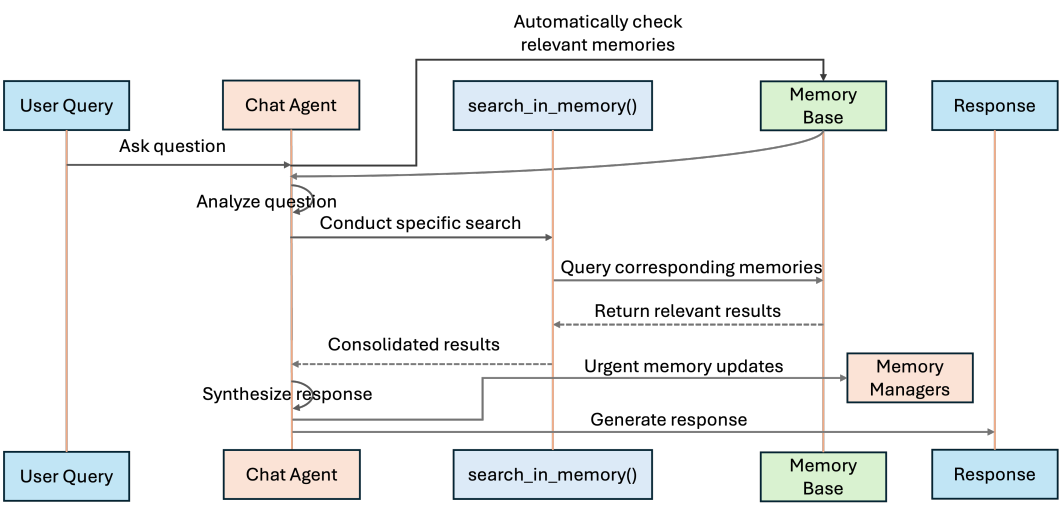
當 MIRIX Agent 收集足夠多的 Memory 後,就可以開始基於 Memory 回答使用者的問題。MIRIX Agent 實際在與使用者對話的過程如上圖所示:基於使用者所輸入的內容,先到 Memory Base 中取出 6 種 Memory Component 的相關資訊 (簡潔的資訊而非所有細節)。Chat Agent 判斷目前使用者輸入的內容,應該是由哪一種 Memory Component 處理,觸發 “Conduct Specific Search”,從該特定的 Memory Component 中取出更詳細更完整的相關資訊。最後則根據這些取出的相關資訊來生成最後的回覆。如果 Chat Agent 認定使用者提供的內容需要進行 Memory Update,則可以直接觸發特定的 Memory Manager 來對特定的 Memory Component 進行更新。
3 實驗結果
在實驗階段,MIRIX 論文中使用了兩個 Deataset — ScreenshotVQA 以及 LOCOMO。
ScreenshotVQA 是本篇論文自行建立的 Multimodal LLM Memory Dataset,這個 Benchmark 包含了 3 位使用者在電腦使用天數為 1 天, 20 天與 1 個月情況下,所收集到的 5886, 18178 與 5349 張螢幕畫面截圖以及相對應的 11, 21 與 55 個問題。而 LOCOMO 則是 Text-Only LLM Memory Dataset,包含了 600 次 Conversation,每次 Conversation 平均包含 26K 個 Token 與相對應的 200 個問題。
在 Evaluation Metric 上,作者基於 GPT-4.1 設計 LLM-as-a-Judge 的方法。此外,MIRIX Agent 在 ScreenshotVQA 與 LOCOMO Dataset 分別以 gemini-2.5-flash-preview-04-17 與 gpt-4.1-mini 作 Backbone Model。

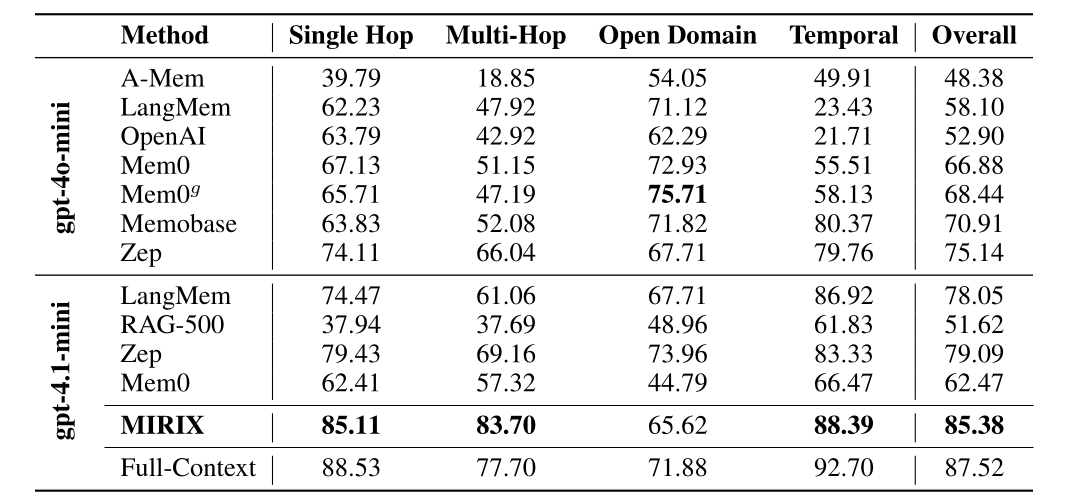
由上方的實驗結果可以看到 MIRIX Agent 在兩個 Dataset 上都取得了相當厲害的表現!
4 結語
本篇文章介紹了 MIRIX 論文所提出的 LLM Memory 方法。讀完本篇論文,最令我印象深刻的是 MIRIX 中定義的 6 種 Memory Component,幾乎涵蓋了各種不同的使用情境,也補足了 LangMem, Mem0 與 MemGPT 中針對 Memory Component 種類設計的不足。至於 Memory Update Worflow 與 Conversation Workflow 我覺得並沒有太特別的地方,但是 MIRIX 特別針對每一種 Memory Component 設計 Memory Agent,也比其他 Baseline 方法有更好的表現,可以想像在 Prompt 設計上應該值得參考。