為什麼你的 RAG 遇到表格就智商歸零?KDD 2026 頂會論文 MixRAG 帶來的破局之道

1 前言
大家應該都有過這種經驗:當我們用 LangChain 或 LlamaIndex 兜出一個 RAG (檢索增強生成) 系統,拿去跑維基百科或新聞稿時,效果通常滿好的,讓人有種「我懂 AI 了」的錯覺。
但一旦你把這套系統搬到真實世界的商業場景 —— 例如餵給它一份長達百頁、塞滿了冗長論述與「層級化複雜表格 (Hierarchical Tables) 」的財務年報、臨床指南或政府報告時,你會發現系統的 Performance 往往會迎來斷崖式的下跌,甚至可以說是「智商瞬間歸零」。
最近我在啃 KDD 2026 的 Paper 時,關注到一篇論文:《Mixture-of-RAG: Integrating Text and Tables with Large Language Models》 (arXiv:2504.09554) 。這篇論文沒有在那邊跟你玩虛的,它直接拿業界最痛的「異質文檔 (Heterogeneous Documents) 」開刀,提出了一套非常優雅且充滿工程智慧的架構。
今天這篇文章,就讓我們泡杯咖啡,一起深入拆解這個名為 MixRAG 的強大框架,看看他們是如何把艱澀的學術理論,轉化為拳拳到肉的工程實踐。
本篇論文提出 MixRAG 框架,專解 RAG 系統在處理「長篇文字 + 複雜層級表格」時的檢索失準與計算幻覺問題。核心亮點有三:
- 層級表格表示法 (H-RCL):不硬逼模型看二維大表,而是把表格拆解成帶有「祖宗層級路徑」的自然語言句子,讓 Embedding 模型看懂結構化數據。
- 雙階段檢索:先用 BM25 + Embedding 找到父文檔,再透過 LLM 在文檔內部進行「微型向量檢索」來過濾雜訊,極致控管 Context Window。
- 將邏輯與計算解耦 (RECAP 策略):承認 LLM 數學就是爛!強制 LLM 只負責「提取證據」並「寫出計算公式」,最後交由 Python 的計算器算出精確結果。
2 為什麼我們需要這篇論文?
在深入 MixRAG 的精妙架構之前,我們必須先搞懂:在它出現之前,我們到底遇到了什麼跨不過去的坎?
我們發現,現有的 SOTA (State-of-the-Art) 方法在面對這類文字與表格交錯的「異質文檔」時,存在幾個致命的缺陷:
- 粗暴的結構化表示:傳統做法通常是把表格當作一塊普通的文本,直接轉成 Markdown 展平,或者叫 LLM 生成一段籠統的「整表摘要」。這裡有個嚴重的問題:這會徹底破壞表格內部的「層級依賴關係」。
- 想像一下:表格裡有個數字寫著「100」,它上方跨越了「2023年 -> Q1」,左方跨越了「營收 -> 產品X」。一旦轉成純文本丟失了這個「座標路徑」,這個「100」對 Embedding 模型來說就是個毫無意義的數字。
- 檢索精準度的嚴重局限:傳統 RAG 深度依賴語義相似度 (Dense Retrieval) 。但在處理財務數據時,問題往往需要精確的數值或年份比對。單純依賴 Embedding,很容易撈出一堆「語義相似」但「沒有關鍵數據」的廢話;如果只用 BM25 關鍵字檢索,又會漏掉措辭不同但語意相同的段落。
- 災難性的推理準確度:就算你今天人品爆發,把正確的文檔和表格找出來了,當問題涉及到「計算 2013 到 2014 年的增長率」時,依賴 LLM 自己去「心算」跨模態數據,幾乎必然會觸發嚴重的幻覺 (Hallucination) 。
既然把表格當文本處理行不通,MixRAG 的作者決定退一步,重新設計一套專屬的 Pipeline。這套解法的核心 Insight 很簡單:承認 Embedding 看不懂複雜表格,也承認 LLM 數學很爛。
接下來,我們來看看他們是怎麼「對症下藥」的。
3 MixRAG 方法論拆解:準備、挑選與烹飪
MixRAG 的系統架構過程:文檔表示、跨模態檢索、多步推理。
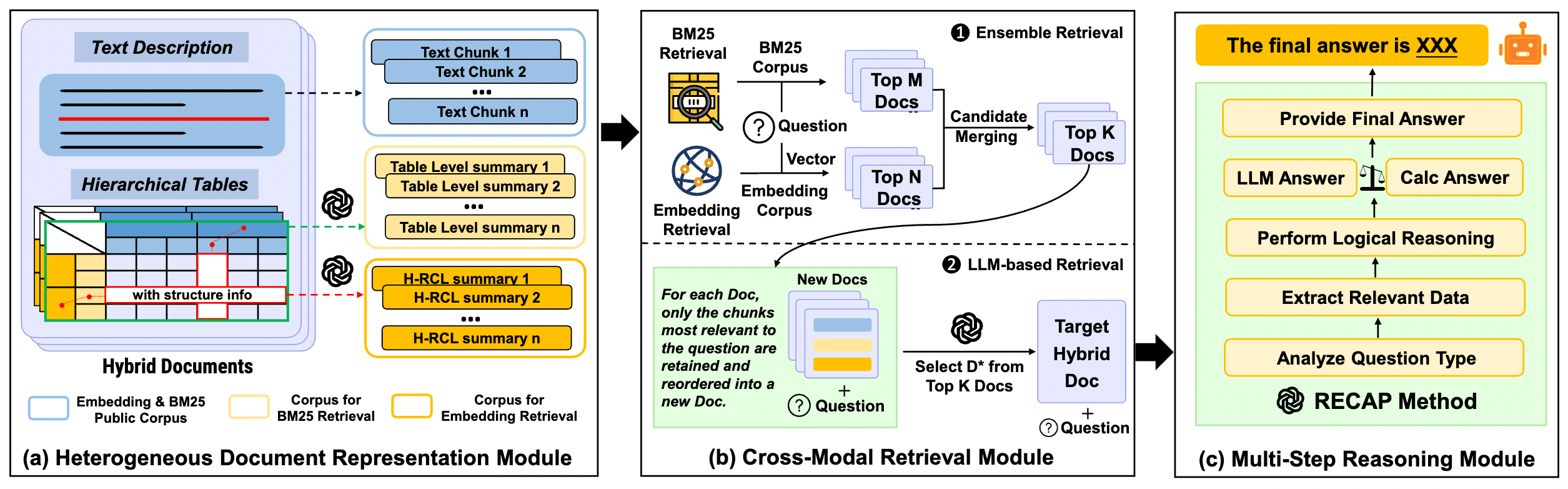
3.1 Heterogeneous Document Representation
這個模組的終極目標,是把「非結構化的文本」和「結構化的表格」轉化為統一的、最適合檢索演算法消化的「區塊 (Chunks) 」。
對於文本,作者不採用生硬的固定 Token 切分法,而是利用 spaCy 進行指代消解 (Coreference Resolution,把 “It” 還原成 “The revenue”) ,然後進行語義完整的句級切分。
但真正的重頭戲在於表格的處理:H-RCL 摘要 (Hierarchy Row-and-Column-Level Summary)。
為了解決前面提到的「迷失座標」問題,H-RCL 採用了降維打擊。要把複雜表格當作一張地圖,要精準定位一個數據單元 ,我們需要它完整的「家譜」:
- 左側標題路徑:
- 頂部標題路徑:
系統會遍歷表格,將這些路徑與數據結合,並交給 LLM 生成自然語言描述 (行摘要 與列摘要 ) 。就這樣,一張 行 列的二維表格,就被「語義化」成了 個獨立的自然語言段落。
在讀這篇 Paper 時,我發現一個極其細膩的工程 Trade-off:MixRAG 並沒有完全拋棄傳統的整表摘要 (Table Level Summary) !
- 給 Embedding 用的資料流:使用拆解後的 個 H-RCL Chunks。因為向量模型需要極度細粒度的語義依賴,才能進行精準匹配。
- 給 BM25 用的資料流:保留了一整份的 Table Level Summary Chunk。為什麼?因為如果你把 “Revenue” 這個詞拆到幾十個 H-RCL 句子裡,會導致 BM25 的詞頻 (Term Frequency) 大亂,產生「關鍵詞過度聚合」的偏差。
這才是真正有實戰經驗的工程師會做出的設計。
3.2 Cross-Modal Retrieval Module
現在我們有了一個充滿各種細粒度 Chunk 的資料庫。接下來要在成千上萬的文檔中,透過一個 「兩階段漏斗」,精準鎖定那篇能回答問題的文檔 。
階段一:Ensemble Retrieval
既然單一演算法有盲點,那就雙管齊下:
- 用 BM25 抓精確關鍵字,找出 Top-M 個 Chunks。
- 計算問題向量 與各個 Chunk 向量 的餘弦相似度,找出 Top-N 個 Chunks。
- 關鍵步驟 (Mapping):我們檢索到的是「句子」,但回傳給下游的必須是「整篇文檔」以保留上下文。所以系統會回溯這些 Chunks 隸屬的父文檔 (Parent Document) ,取聯集去重後,得到 Top-K 個候選文檔。
階段二:LLM-based Retrieval
面對這 K 篇依然冗長的文檔,如果直接塞給 LLM,Context Window 絕對會爆掉,或者發生 Lost in the Middle。 作者引入了 動態內容過濾 (Dynamic Content Filtering):在「文檔內部」再做一次微型向量檢索,剔除低於閾值 的雜訊,將精華重組成「精簡版文檔」。最後才讓 LLM 作為高級評審,選出最完美的那篇 。
3.3 Multi-Step Reasoning Module
拿著最精確的文檔,我們終於要面對 LLM 那糟糕的數學能力了。為此,作者量身打造了 RECAP 提示策略 (Restate, Extract, Compute, Answer, Present)。
這是一個強制 LLM 拆解思考的框架,它必須嚴格按步驟輸出:
- Restate:重述問題。
- Extract:從文檔中明確提取數據 (杜絕幻覺) 。
- Compute (核心亮點):要求 LLM 只寫出精確的數學計算公式,並用特定符號包覆 (例如
##(652-515)/515##) ,不准自己猜答案。 - Answer & Present:格式化輸出。
## 裡的字串。如果抓到數學公式,系統會強制忽略 LLM 的心算結果,直接用 Python 的 eval() 去執行公式,並把絕對精確的數值回傳。
這種「邏輯與計算解耦」的做法,僅需一次 API 呼叫,兼顧了超高準確率與低延遲!4 實驗結果:數據背後的底層邏輯
為了驗證,作者自己建了一個包含 2,178 篇真實異質文檔的高品質資料集 DocRAGLib。讓我們看看 MixRAG 在這個殘酷競技場上的表現。
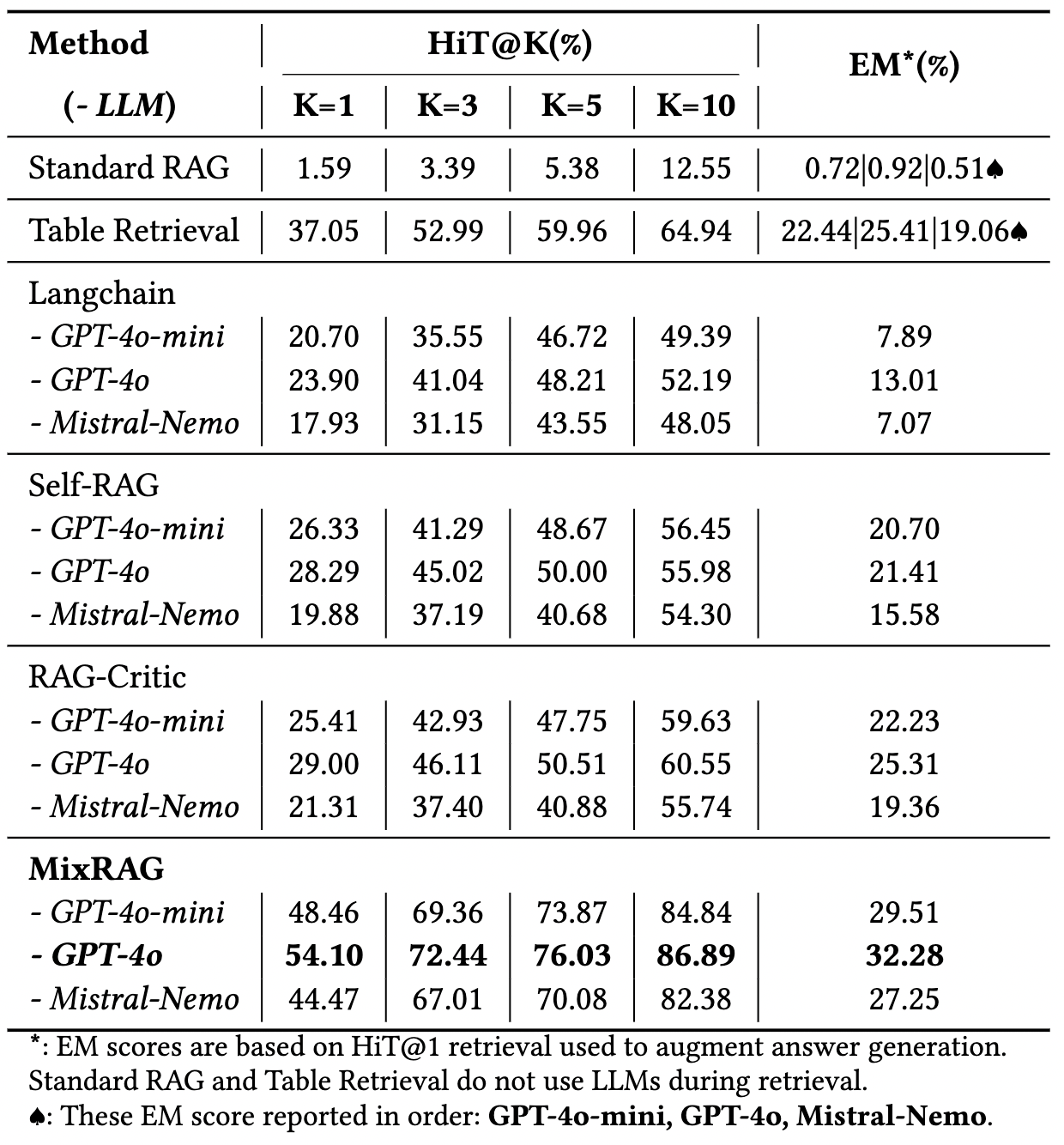
檢索性能的碾壓:
你有看到 Table 1 中 Standard RAG 的 HiT@1 居然只有 1.59% 嗎?這無情地揭露了:當你把複雜表格 PDF 丟進預設的 Text Splitter 時,結構被徹底粉碎,檢索系統基本上就在瞎猜。 而 MixRAG (搭載 GPT-4o) 達到了 54.10%。因為它沒有切碎表格,而是透過 H-RCL 給了 Embedding 模型清晰的座標。
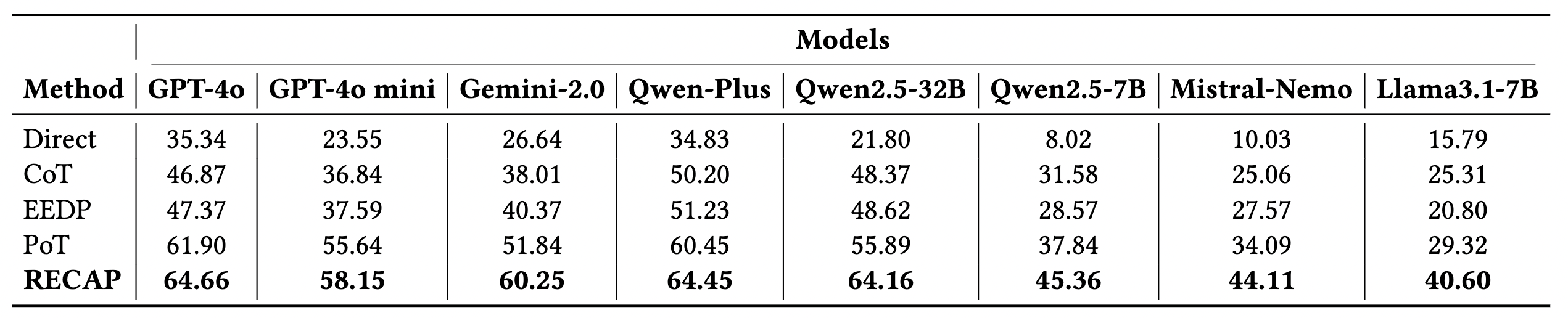
推理的穩健性:
在精確匹配度 (Exact Match) 上,RECAP (64.66%) 明顯擊敗了 CoT (46.87%) 與 PoT (61.90%)。
- 贏過 CoT 是因為我們不讓 LLM 心算。
- 贏過 PoT (要求 LLM 寫出完整 Python Code 解題) 是因為在充滿雜訊的真實文檔中,LLM 寫出的 Code 極易因為變數命名錯誤而直接 Crash。RECAP 的「半自然語言 + 半數學公式」容錯率 (Robustness) 高出太多了。
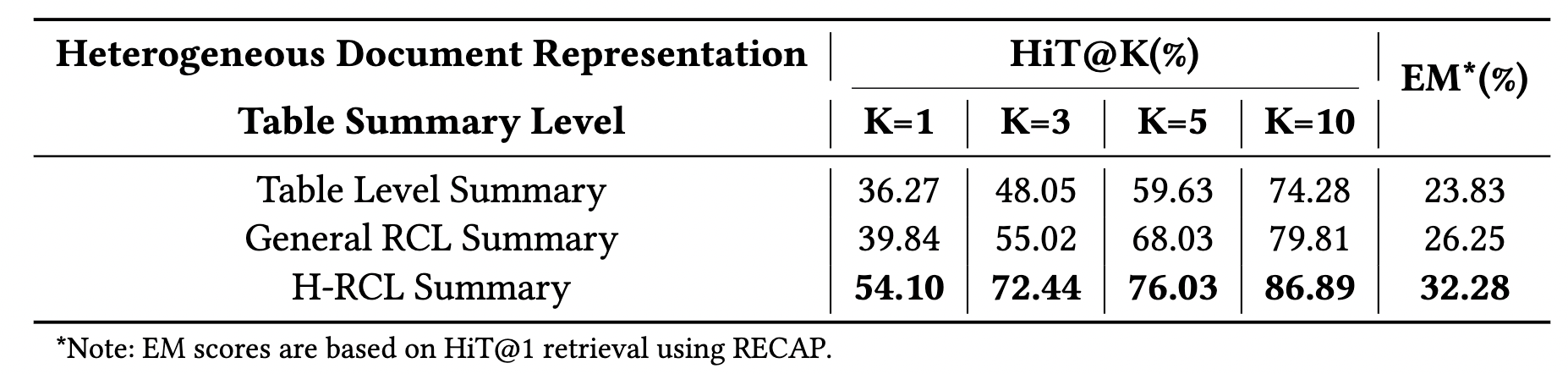
消融實驗:
如果只用「整表摘要」,HiT@1 只有 36.27%;換成完整的 H-RCL (保留祖宗路徑) ,成績暴增至 54.10%。這完美印證了:沒有座標的數據,就是垃圾數據。
5 結論與啟發
誠然,MixRAG 並非完美的銀彈。當用戶提出極度模糊的問題 (沒有明確 Entity) ,或者需要跨五六張表格做超長多步推理時,系統仍可能迷失。未來的解法可能必須走向「問題解構 (Query Decomposition) 」,在檢索前先將複雜問題拆分為子問題,這也是邁向真正 Agentic 系統的必經之路。
MixRAG 最優雅的地方,在於它對邊界感 (Boundaries) 的精準把控。 讓傳統的歸傳統 (BM25) ,讓統計的歸統計 (Embedding) ,讓邏輯的歸模型 (LLM) ,讓計算的歸程式 (Calculator) 。當每一個工具都被放在它最擅長的位置上時,我們才能在最複雜的真實世界場景中,煉成最強大的 RAG 系統。
如果你最近也正在為公司內部的財報、法務文件問答系統苦惱,強烈建議你去翻翻這篇 KDD 2026 的神作,相信一定會給你帶來不少靈感!