RAG 懂語義卻不懂時間?深入剖析 EMNLP 2025 的 MRAG 模組化檢索框架

1 前言
大家在做 RAG (Retrieval-Augmented Generation) 的時候,應該都有過這種經驗:
你問 ChatBot:「2019 年的英國首相是誰?」 結果它自信滿滿地吐出:「鮑里斯·強森 (Boris Johnson) 。」 這看起來沒問題。
但如果你問:「2019 年之前的首相是誰?」 它可能還是把包含 “2019” 和 “Boris Johnson” 的文檔撈出來,然後告訴你還是強森。這時候你的使用者體驗 (UX) 就炸裂了。
最近我讀了一篇 EMNLP 2025 (Findings) 的論文《MRAG: A Modular Retrieval Framework for Time-Sensitive Question Answering》,它非常精準地打中了這個痛點。這篇 Paper 給我最大的啟發不是它用了什麼新的 LLM,而是它指出了現有 RAG 架構的一個巨大盲點:我們太依賴 Embedding 模型的語義理解,卻忘了它們根本不懂時間邏輯。
今天這篇文章,就來帶大家硬核拆解這篇論文,看看如何透過「模組化」與「符號邏輯」來拯救你的 RAG 系統。
- 痛點:現有的檢索器 (如 Contriever, BM25) 只會做「關鍵字匹配」,無法理解 這種時間邏輯。
- 解法:MRAG 提出了一種 Training-free 的模組化架構,將「語義理解」與「時間推理」解耦 (Disentangle) 。
- 核心技術:利用 LLM 進行細粒度的證據摘要,並結合 符號算法 (Symbolic Algorithms) 進行混合排序。
- 成效:在新的 TempRAGEVAL 基準測試上,大幅超越現有的 SOTA 模型,證明了「神經網絡 + 符號邏輯」是處理複雜推理的正確方向。
2 為什麼 RAG 會由「智」轉「愚」?
在深入 MRAG 的架構之前,我們先來聊聊為什麼這個問題這麼難搞。
現有的 SOTA 檢索器 (無論是 Dense Retriever 還是 BM25) ,本質上都是在算「相似度」。當你輸入 “Who is the UK PM in 2019?",模型會把這句話轉成 Vector,然後去向量資料庫 (Vector DB) 裡找最接近的文檔。
這裡有個魔鬼細節: 模型把「2019」當成了一個普通的 Token,就像 “Apple” 或 “Banana” 一樣。
- 字串匹配陷阱:如果文檔裡寫著 “In 2019…",模型能找到。
- 邏輯崩潰:如果你問「2021 年 5 月的首相是誰?」,而正確文檔只寫了 “Boris Johnson (2019–2022)"。這時候模型就傻了,因為它不懂 這個區間邏輯。它反而可能去抓取包含 “May 2021” 字串但內容完全無關的新聞。
簡單來說,神經網絡 (Neural Networks) 擅長模糊的語義匹配 (Vibes) ,但非常不擅長精確的數值邏輯。
3 MRAG 的解法:分而治之 (Divide and Conquer)
MRAG (Modular Retrieval Augmented Generation) 的核心洞見非常漂亮:既然 Embedding 模型學不會數學,那我們就不要逼它學。
作者提出了一個 解耦 (Disentanglement) 的策略:
- 語義 (Semantics):交給擅長的神經網絡。
- 時間 (Temporality):交給確定性的 符號演算法 (Symbolic Algorithms)。
這是一個 End-to-end 流程被拆解後的樣子:
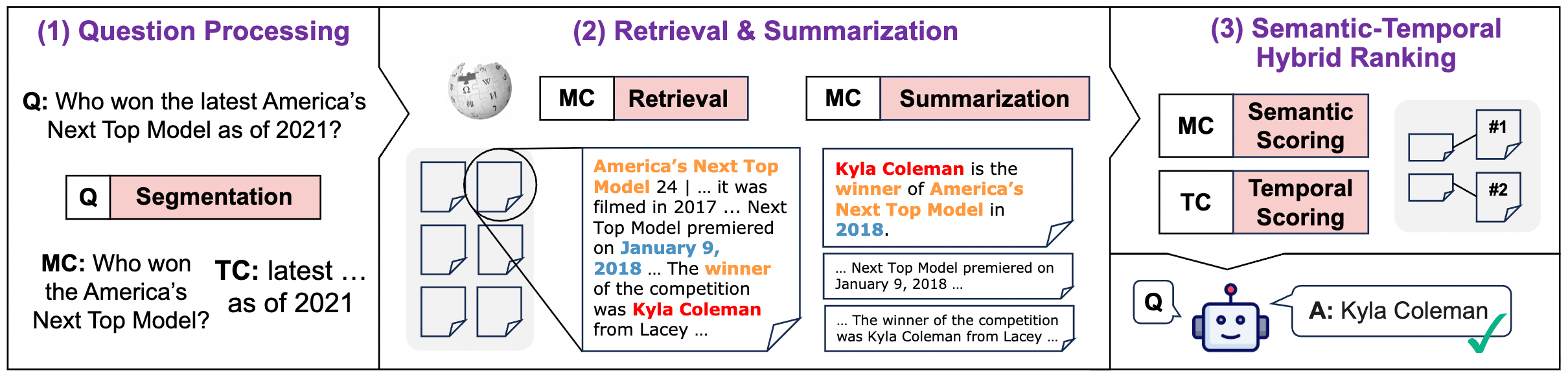
讓我們一步步拆解這個 Pipeline。
3.1 Phase 1: 意圖拆解 (Question Processing)
首先,系統不會直接把整句問題丟給檢索器。它會先把使用者的 Query 拆解成兩個獨立訊號:
- 主要內容 (Main Content, MC):去除時間限制,只保留核心實體。
- Query: “Who is the UK PM as of 2019?”
- MC: “Who is the UK PM?”
- 目的: 先把所有相關的人事物都撈回來,不管時間對不對,確保 Recall 足夠高。
- 時間限制 (Temporal Constraint, TC):提取具體的時間點與關係。
- TC: Relation=“as of”, Timestamp=“2019”。
這一步通常結合 Regex 或 NLP 工具 (如 spaCy) 來做,比純用 LLM 更穩健,畢竟我們不需要 LLM 在這裡產生幻覺。
3.2 Phase 2: 由粗到細的證據處理 (Retrieval & Summarization)
傳統 RAG 最常犯的錯誤就是直接檢索一整個 Chunk (段落) 。一個段落可能包含某個實體幾十年的歷史,這會導致時間資訊混合 (Temporal Mixing)。
MRAG 的做法是:
- 先廣泛檢索:用 MC 撈出 Top-K (例如 100 篇) 文檔。
- 再細粒度切分:這是關鍵。系統會把文檔切分為 「單一事實單位」。
- 作者推薦使用 LLM 摘要:讓 LLM 讀過段落後,生成一句「濃縮的句子」,確保這句話只包含一個明確的時間點和事實。
這樣一來,我們就得到了一堆乾淨的 證據對,雜訊被大幅降低。
3.3 Phase 3: 語義-時間混合排序 (The “Secret Sauce”)
這是 MRAG 的靈魂所在。系統對每一個證據進行兩次打分:
- 語義分數 ():用 Embedding 模型算相似度。這大家都很熟了。
- 時間分數 ():完全不使用神經網絡,而是基於規則的 Spline Functions。
作者設計了 6 種數學曲線來對應不同的時間意圖:
| 意圖 | 關係 | 物理意義 |
|---|---|---|
| Last (找最新) | before | 在截止時間前,越接近越好 (Recency Bias)。 |
| First (找最早) | after | 在起始時間後,越接近起始點越好。 |

最後的總分公式是:
這個乘法公式非常暴力且有效,它具有 「一票否決權」:
- 如果時間完全錯誤 () ,即使語義再相關 (例如關鍵字完全命中) ,總分也是 0。
- 這直接解決了「關鍵字匹配但年份錯誤」的經典 RAG 問題。
4 實驗結果:斷崖式的領先
為了驗證這套架構,作者搞了一個新的 Benchmark 叫 TempRAGEVAL。他們做了一件很壞 (但也很好) 的事:引入 時間擾動 (Temporal Perturbations)。
例如把 “Who was PM in 2019?” 改成 “Who was PM before 2020?"。
結果非常殘酷:

- 傳統方法崩潰:強如 GEMMA (基於 LLM 的 Reranker) ,在面對擾動後,Performance 下降許多,這證實了它們只是在做高級的關鍵字匹配。
- MRAG 逆勢上揚:MRAG 不僅抗住了擾動,在證據召回率 (ER@5) 上甚至達到了 59.2%,遠超 GEMMA 的 45.3%。
更有趣的是,在 TimeQA (包含更多冷門長尾知識) 的測試集上,MRAG 的優勢更大。這說明了:當 LLM 無法靠「背誦」訓練資料來回答問題時,精確的檢索邏輯就成了唯一的救命稻草。
5 結論
- 不要迷信 End-to-End:在 LLM 時代,我們很容易變懶,想把所有東西都丟進 Context Window 讓模型自己學。但 MRAG 證明了,對於 精確邏輯 (數學、時間、程式碼執行),將其從神經網絡中剝離出來,交給確定性的符號系統 (Symbolic System) ,效果往往更好。
- 架構設計 > 模型大小:這篇論文沒有訓練什麼幾千億參數的大模型,而是透過優雅的 Pipeline 設計解決了問題。這才是工程師該發揮價值的地方。
- Neuro-Symbolic AI 是未來:這種「神經網絡負責語義,符號邏輯負責推理」的混合架構,我認為會是未來構建複雜 Agent 的主流方向。
如果你正在為 RAG 系統的「幻覺」或「邏輯錯誤」頭痛,不妨參考 MRAG 的思路,試著把你的問題解耦看看。