Google 2025 論文解讀:只要「複製貼上」就能變強?Prompt Repetition 如何成為 LLM 的免費午餐

1 前言
歡迎來到 “Prompt Repetition Improves Non-Reasoning LLMs” 的論文筆記。這篇論文由 Google Research 團隊於 2025 年 12 月發表,它提出了一個簡單到令人難以置信,卻又極具啟發性的發現。
- 論文連結: arXiv:2512.14982
在 AI 研究中,我們常追求複雜的模型架構修改或昂貴的訓練流程來提升效能。但這篇論文反其道而行,它告訴我們: 「有時候,只要把輸入的 Prompt 複製貼上一次,就能獲得顯著的性能提升。」
本篇筆記將帶領我們從 Transformer 的 Causal Attention 出發,理解為什麼模型會「看不懂」單次的輸入,以及為什麼 Prompt Repetition 可以被視為一種在 Decoder-only 架構上模擬 Bidirectional Attention 的巧妙手段。
這篇筆記的核心價值在於釐清以下三個重點 (TL;DR) :
- 方法論: 將輸入從 變為 。
- 原理: 利用第二次的重複輸入,讓 Token 能夠「看見」完整的上下文,從而修復 Key/Value 的表徵品質。
- 效益: 這是一份 「免費的午餐 (Free Lunch) 」。它利用了 GPU 平行運算的特性,在不增加推論延遲 (Latency) 的前提下提升準確率。
2 問題定義
本篇論文試圖解決的核心問題,源於目前主流大型語言模型 (LLMs,如 GPT-4, Gemini, Llama) 的基礎架構限制。這些模型大多採用 Transformer Decoder-only 架構,這意味著它們在處理資訊時存在著單向的「視力缺陷」。
本篇論文想處理的挑戰可以總結為:
如何在不改變模型架構 (Black-box compatible) 且不增加生成延遲 (Zero latency overhead) 的前提下,克服因果模型的單向注意力瓶頸,讓模型獲得類似「雙向注意力」的理解能力?
2.1 The Causal Attention Bottleneck
在 Decoder-only 架構中,模型是 Causal 的。這代表模型在生成或處理序列中的第 個 Token 時,只能「看見 (Attend to) 」位置 的 Token,而無法看見未來的 Token 。
這導致了一個根本性的問題: Token 的 Representation Quality 受限於其出現的時間點。
讓我們回想一下我們之前討論過的數學直覺: 在 Transformer 的每一層,Attention 機制如下運作:
當模型處理序列前端的 Token 時,它所生成的 Key () 和 Value () 僅包含了該時間點之前的資訊。這意味著這些早期的 Token 是在「對未來一無所知」的狀態下被編碼的。
2.1.1 實例解析: 歧義性問題
為了讓這點更具體,請看以下的例子:
輸入語句:
"The bark was rough. <Question> ..."
- Early Token Processing: 當模型讀到
"bark"這個字時,它只看得到"The bark"。此時,模型無法確定這裡的 “bark” 是指「狗叫聲」還是「樹皮」。因此,它生成的 Key/Value 向量可能是一個模糊的混合體。 - Late Token Processing: 當模型讀到後面的
"rough"(粗糙的) 時,雖然最後這個 Token 知道整句話是在講樹皮,但它必須回頭去 Attend 前面"bark"的資訊。 - Noisy In, Noisy Out: 雖然最後一個 Token 擁有全局視角,但它所抓取的原料 (即
"bark"的 向量) 是早期生成的、品質低落且含糊不清的。這限制了模型最終的理解能力。
2.2 Sensitivity to Input Order
由於上述的單向注意力限制,模型對 Prompt 的順序變得極度敏感。這在論文的實驗中被稱為 “Options-first” vs. “Question-first” 的挑戰。
- Context/Options First (
<Context> <Question>): 模型在閱讀 Context 時,還不知道 Question 是什麼。因此,它無法針對性地提取與問題相關的資訊 (Key/Value 是非特定目標的) 。 - Question First (
<Question> <Context>): 模型先看到問題,理論上在閱讀 Context 時會有更好的聚焦。但隨著 Context 變長,模型可能會遺忘前面的問題,或者注意力被分散。
2.3 The Trade-off
在 Prompt Repetition 出現之前,我們通常面臨兩種解決方案,但都有明顯缺陷:
Chain-of-Thought (CoT): 讓模型 “Think step by step” 或先複述問題。
- 優點: 模型透過生成過程,強迫自己重新處理資訊,解決了上述的表徵問題。
- 缺點: 昂貴且慢。這增加了生成的 Token 數量 (Decode 階段) ,直接導致 Latency 增加和 API 成本上升。
Bidirectional Attention / Prefix LM: 像 BERT 或 T5 那樣,允許 Input Token 互相看見。
- 優點: 從根本上解決表徵問題。
- 缺點: 這需要改變模型架構或訓練目標。對於我們只能透過 API 呼叫的現成 Decoder-only 模型 (如 GPT-4, Claude 3) ,這是不可能的任務。
這部分是本篇論文最精華、也是最令工程師興奮的地方。因為通常在 AI 領域,「效果越好」往往意味著「計算越慢」或是「架構越複雜」。但 Prompt Repetition 打破了這個常規。
讓我們來深入了解這個方法的具體實作及其背後的系統運作原理。
3 方法介紹
這篇論文提出的方法在概念上極度直觀,甚至可以用一行程式碼來概括:將使用者的輸入 Prompt 原封不動地複製一遍。
3.1 核心操作:Prompt Repetition
假設使用者的原始輸入為 ,其中可能包含了一段很長的文章 (Context) 和一個問題 (Question) 。 在標準的做法中,模型的輸入序列 就是 。
但在 Prompt Repetition 中,我們將輸入轉換為:
也就是 <QUERY><QUERY> 的形式。
3.1.1 為什麼這樣做有效? (從 Attention 視角解析)
讓我們將重複後的輸入序列標記為兩個部分:第一遍的 和第二遍的 。
(The “Context” Provider): 當模型處理 時,它就像平常一樣,受限於因果注意力,對後面的資訊一無所知。這裡產生的 Key/Value 表徵可能是不完美的。
(The “Context-Aware” Reader): 這才是魔法發生的地方。當模型開始處理 中的每一個 Token 時,由於 Causal Mask 允許它看見前面的所有 Token, 中的每一個位置都能完整地「看見」整個 。
這創造了一種 Pseudo-Bidirectional Attention 的效果:
- 在 中,原本位於開頭的 Token (例如 Context) ,現在可以透過 Attention 機制去查詢 結尾的 Token (例如 Question) 。
- 這意味著 生成的 Key/Value Pairs 是 「已經看過全文」 的高品質表徵。
- 當模型最終要生成答案時,它會高度依賴這些來自 的高品質資訊,從而做出準確的預測。
<Context><Question> 還是 <Question><Context>,在重複之後, 的部分都能確保「互相關照」。開發者不再需要煩惱 Prompt 該怎麼擺放,這極大提升了系統的 Robustness。3.2 Variations & Ablations
為了證明這個效果不是巧合,作者設計了幾種變體來進行測試。這部分對於我們理解「為什麼是重複」很有幫助。
Prompt Repetition:
- 格式:
\( <QUERY><QUERY> \) - 結論:這是論文的主推方法,效果穩定且高效。
- 格式:
Prompt Repetition - Verbose:
- 格式:
\( <QUERY> \text{Let me repeat that:} <QUERY> \) - 邏輯:測試模型是否需要像人類一樣的自然語言轉折。
- 結論:效果與標準重複差不多,但多了一些 token,性價比略低。
- 格式:
Padding:
- 格式:
\( ...(\text{dots})... <QUERY> \) - 邏輯:我們需要驗證:性能提升是因為「重複了有意義的資訊」,還是僅僅因為「輸入變長了,讓模型有更多運算空間」?
- 結論:Padding 完全無效。這反證了提升的來源確實是來自於我們推導的「雙向注意力模擬」,而非單純的深度增加。
- 格式:
3.3 為什麼這是 “Free Lunch”?
你可能會擔心:「輸入長度變兩倍,難道不會變慢嗎?」
答案在於 LLM 推理過程的兩個階段差異:Prefill 與 Decode。
3.3.1 Prefill 階段 (處理 Prompt)
- 這是模型閱讀
<QUERY><QUERY>的階段。 - 特性: GPU 可以 高度平行化 (Parallel) 運算。同時計算 1000 個 Token 的 Attention Matrix 和計算 500 個 Token 的時間差異極小 (通常在毫秒等級) 。
- 影響: 雖然我們把輸入加倍了,但這部分的額外時間成本對使用者來說幾乎是無感的。
3.3.2 Decode 階段 (生成答案)
- 這是模型一個字一個字吐出 Output 的階段。
- 特性: 這是 序列化 (Serial) 的過程,受限於記憶體頻寬 (Memory Bandwidth) ,是造成 LLM 延遲的主要元兇。
- 影響: Prompt Repetition 並沒有改變 Prompt 的語意 (例如沒有要求 “Think step by step”) ,因此模型生成的 Output 長度保持不變。
3.3.3 總結比較
| 方法 | 輸入長度 | 輸出長度 | Prefill 時間 | Decode 時間 | 總延遲 (Latency) |
|---|---|---|---|---|---|
| Baseline | 短 | 短 | 快 | 快 | 低 |
| CoT (Reasoning) | 短 | 長 (變慢的主因) | 快 | 慢 | 高 |
| Prompt Repetition | 長 (由平行化吸收) | 短 | 快 (微幅增加) | 快 | 低 (接近 Baseline) |
這就是為什麼作者敢大膽聲稱這是一個 “Free Lunch”:我們利用了 GPU 在 Prefill 階段過剩的算力,換取了模型對內容的精確理解,且完全沒有犧牲使用者的等待時間。
4 實驗結果
以下是 5 個最值得關注的實驗發現,它們不僅驗證了 Prompt Repetition 的有效性,也揭示了 Transformer 運作的深層特性。
4.1 驚人的「零敗績」紀錄
首先,最震撼的結果莫過於這個方法的普適性。作者使用了 McNemar 檢定 來評估統計顯著性 (設定 ) 。
- 戰績: 在總共 70 個「模型-任務」的組合測試中,Prompt Repetition 取得了 47 勝 0 敗 的壓倒性成績 (其餘為平手/無顯著差異) 。
- 意義: 這在機器學習領域極為罕見。通常某個 Trick 可能對 GPT 有效,對 Claude 卻無效。但 Prompt Repetition 跨越了不同的模型架構與參數量級。
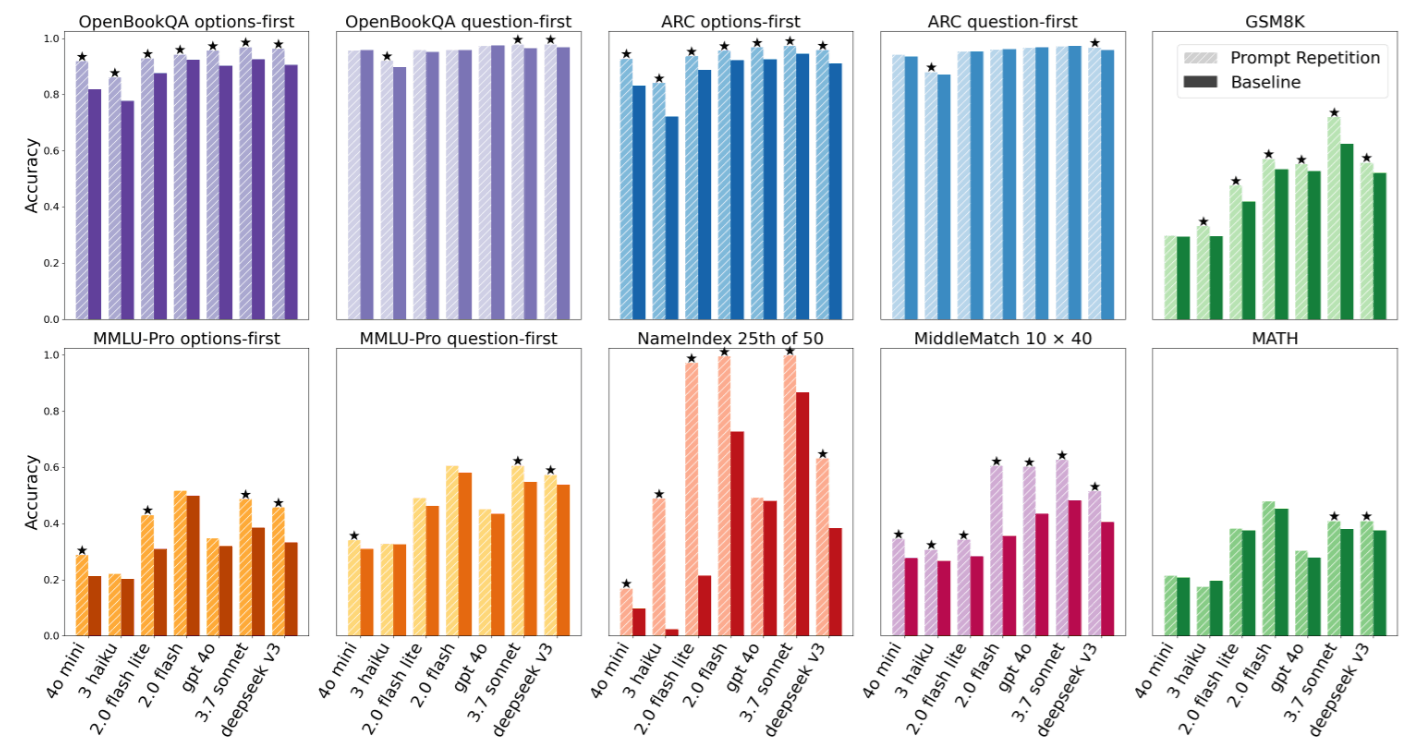
4.2 對「輸入順序」的強大修復力
我們在「問題定義」中提過,LLM 通常對 Prompt 的順序很敏感。論文比較了兩種格式:
- Options-first:
<選項> <問題> - Question-first:
<問題> <選項>
實驗發現,在 Baseline 中,Options-first 的表現通常較差 (因為讀選項時不知道問題) 。然而,一旦使用了 Prompt Repetition:
Options-first的性能獲得了巨大的提升。- 其表現甚至追平或超越了原本較優的
Question-first。
這證實了我們的理論:重複輸入讓模型在閱讀第二次的選項時,已經知道了問題是什麼。這意味著開發者不再需要煩惱 Prompt 該怎麼擺放,Prompt Repetition 為系統帶來了極高的 Robustness。
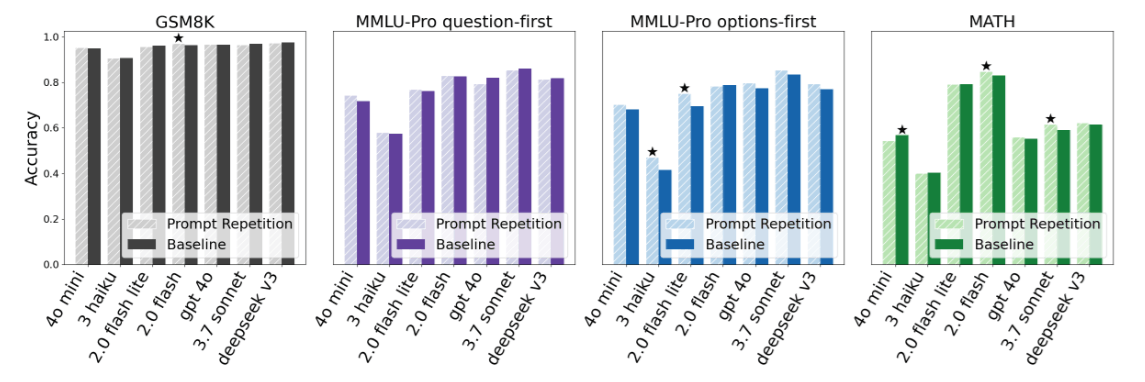
4.3 「免費午餐」的實證:延遲與長度不變
請參考論文中 Figure 2 的實驗數據:
- Output Length (生成長度): 兩者高度一致。這證明 Prompt Repetition 不會像 CoT 那樣觸發模型生成長篇大論的解釋。
- Latency (延遲): 幾乎持平。即使輸入變兩倍長,End-to-End 的延遲幾乎沒有增加。
4.4 4. 推理任務 vs. 非推理任務
為了探討邊界,作者做了一個有趣的對照實驗:強制模型開啟 “Think step by step” (CoT)。
- 結果: 當開啟 CoT 後,Prompt Repetition 的效果變成了 「中性至微幅正面」 (5 勝 1 敗 22 平) 。
- 解讀: 這完美印證了我們之前的推論。
- Baseline + CoT: 模型自己在 Output 階段做了重複/思考,修復了表徵問題。
- Repetition + CoT: 雖然沒壞處,但因為模型已經會自己修復了,我們在 Input 端幫它重複一次的邊際效益就遞減了 (Diminishing Returns)。
這告訴我們:Prompt Repetition 最適合那些「需要精準理解,但不需要複雜多步推理」的任務 (如資訊提取、閱讀測驗) 。
4.5 自定義任務的「顯微鏡效應」
為了證明效果不是運氣,作者設計了兩個極端的「查找任務」 (Appendix A.3) ,其中最經典的是 NameIndex 任務。
- 任務: 給一串 50 個名字,問:「第 25 個名字是誰?」
- Gemini 2.0 Flash-Lite 的表現:
- Baseline: 21.33% (幾乎是瞎猜)。
- Prompt Repetition: 97.33% (接近完美)。
為什麼差距這麼大?
因為在 Baseline 中,模型讀到第 25 個名字時,還不知道問題是「找第 25 個」,所以它沒有特別記住那個名字。等到讀完問題,已經來不及回頭了 (因果限制) 。而 Prompt Repetition 讓模型在讀 第二遍 時,帶著「我要找第 25 個」的強烈意圖去掃描列表,自然一抓一個準。
這個極端的例子,是本篇論文最有力的證據,證明了 Prompt Repetition 賦予了模型類似 Random Access Memory 的能力。
5 結論
閱讀這篇論文的過程,就像是解開了一個存在於大型語言模型 (LLM) 底層的公開秘密。我們從一個看似簡單到不可思議的操作 —— 「把 Prompt 再貼一次」 —— 出發,最終深入到了 Transformer 架構最根本的 Causal Attention 機制。
5.1 我們學到了什麼?
因果模型的先天缺陷: 所有的 Decoder-only 模型 (如 GPT、Gemini) 都患有「單向視力」的毛病。早期的 Token 無法看見未來的 Token,這導致了表徵品質的低落與對輸入順序的過度敏感。
時間換取空間的藝術: Prompt Repetition 透過在輸入端重複資訊,巧妙地利用了 Transformer 的架構特性。它讓第二遍的 Token 成為「全知者」,能夠回頭去修復第一遍資訊中的模糊與歧義。我們用 Prefill 階段 (廉價、可平行化) 的計算量,換取了原本只有在 雙向注意力模型 (如 BERT) 才能擁有的理解力。
免費午餐是存在的: 最令我們印象深刻的,莫過於它在工程上的高效性。因為利用了 GPU 的平行運算能力,我們幾乎在 Zero Latency Overhead 的情況下,獲得了顯著的準確率提升。這在資源受限的實際應用中極具價值。
與推理模型的連結: 透過我們的討論,我們更洞察到了 RL 訓練的 Reasoning Models 為何會有「複述問題」的湧現行為。這不是偶然,而是模型為了克服注意力瓶頸而演化出的生存策略。現在,我們只需顯式地使用 Prompt Repetition,就能在非推理模型上復現這種優勢。