RAG 架構大翻轉!MIT 新論文 ReDE-RF:不讓 LLM 寫作改當「裁判」,檢索速度暴增 10 倍

1 前言
最近在社群裡跟不少做 RAG (Retrieval-Augmented Generation) 的朋友聊天,大家最大的痛點往往不是 LLM 回答得不夠好,而是 「根本撈不到對的資料」。
尤其在沒有標註資料(Zero-Shot)的冷門領域,大家通常會先想到用 HyDE (Hypothetical Document Embeddings)。這招聽起來很性感:讓 LLM 先「腦補」一篇假文章,再拿這篇假文章去搜真文章。但實作過的人都知道,這招有兩個致命傷:一是慢(生成 Token 很貴),二是容易「一本正經地胡說八道」(幻覺)。
最近我讀到了一篇來自 MIT Lincoln Laboratory 與 MIT 的新 Paper —— ReDE-RF。這篇論文給了我一個很大的啟發:如果我們不再強迫 LLM 去「寫作」,而是讓它專注於「當裁判」,檢索系統是否能更準確、且快上 10 倍?
今天這篇文章,就來深度拆解這篇論文,看看它如何用工程思維解決學術問題。
- 典範轉移:ReDE-RF 不像 HyDE 依賴 LLM 生成虛構文檔,而是採用先檢索真實文檔,再讓 LLM 評分的策略。
- 極致效能:它不讓 LLM 生成文字,而是直接抽取 Output Logits 的機率值(Yes/No),避開了昂貴的 Decoding Loop,速度提升 4-11 倍。
- 消除幻覺:透過錨定「真實存在」的文檔來修正 Query,大幅提升了在生醫、財經等低資源領域的準確度。
- 模型蒸餾:這套流程甚至可以蒸餾(Distill)給小模型,上線時完全不需要 LLM 參與。
2 為什麼 HyDE 還不夠好?(問題定義)
在深入 ReDE-RF 之前,我們先來複習一下目前的 SOTA —— HyDE 是怎麼運作的。
簡單來說,HyDE 就像是一場 「寫作比賽」。當使用者問了一個問題,HyDE 會強迫 LLM 憑空撰寫一篇它認為「理想的文檔」。接著,我們把這篇虛構文檔 (Hypothetical Document) 轉成 Vector,去資料庫找相似的內容。
這個思路在通用領域(如 Wikipedia)很強,但在企業內部或特定領域(Domain Specific)就會撞牆:
知識幻覺 (Hallucination): 想像你在搜一份公司內部的 Legacy Code 文件。LLM 根本沒看過這些 Code,它生成的「虛構文檔」只會充滿錯誤的 Function Name 和邏輯。這叫 Garbage in, Garbage out,錯誤的幻覺會把檢索器帶到陰溝裡。
生成式的高昂成本 (High Latency): 為了讓幻覺看起來像真的,通常需要 LLM 生成數百個 Token。這意味著 GPU 要跑幾百次 Autoregressive Decoding。在講求 Real-time 的搜尋場景,讓使用者等 3-5 秒只為了生成一個 Search Query,這 User Experience 是不及格的。
於是,ReDE-RF (Real Document Embeddings from Relevance Feedback) 提出了一個反直覺但極其合理的洞見:
與其強求 LLM 去「生成」它不知道的內容,不如利用它強大的推理能力去「判斷」眼前的內容。
3 ReDE-RF 的核心機制:從「寫作」轉向「選拔」
ReDE-RF 的架構非常優雅,可以拆解為先撒網,後過濾,再導航的三部曲。
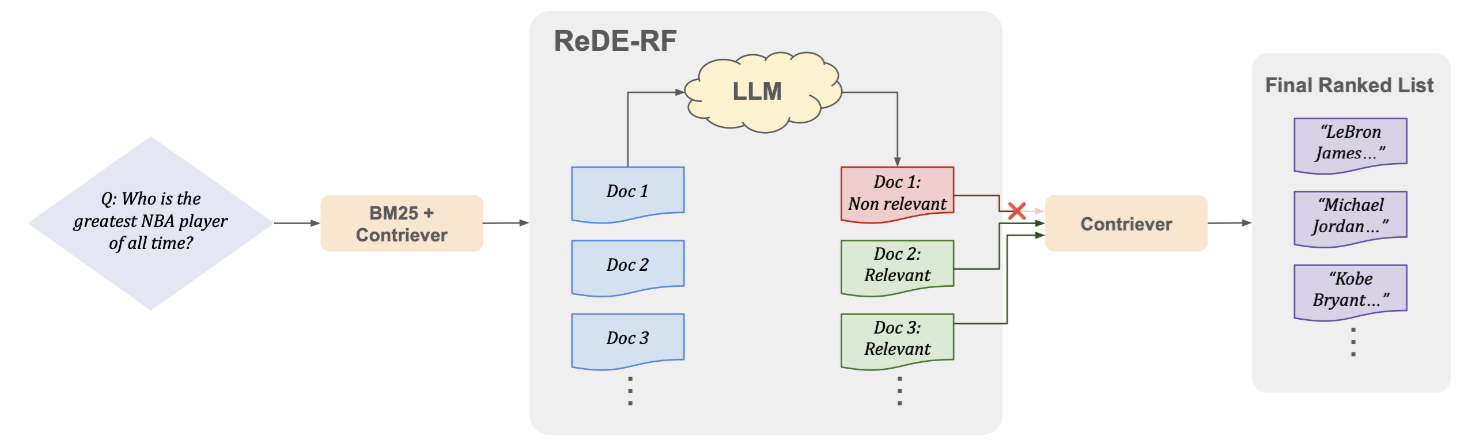
3.1 第一步:初步檢索 (Initial Retrieval) —— 先撒網
既然我們沒有 Label Data,那就先用現成的非監督檢索器(如 BM25 或 Contriever)先抓 Top- 篇文檔回來。這一步不需要完美,只要確保這堆文檔裡「混有」一些正確答案即可。
3.2 第二步:LLM 當裁判 (Logits Over Generation)
這是整篇論文最讓我驚豔的工程細節。
傳統做法是讓 LLM 讀完文章後生成 “Yes” 或 “No”。但 ReDE-RF 的作者認為這太慢了。他們採用了 Logits 判斷法:
- 把 Prompt 和文檔餵給 LLM。
- 只做一次 Forward Pass(不進入生成迴圈)。
- 直接查看 Output Layer 中,代表 “1” (Relevant) 和 “0” (Not Relevant) 的 Logits 分數。
- 用 Softmax 算機率:
這是一個極具 Engineering Sense 的設計:
- 速度:省去了生成文字的時間,Latency 直接砍到地板。
- 穩定:不需要寫 Regular Expression 去解析 LLM 那種 “I think it is highly likely…” 的囉唆回答,數值最誠實。
- 截斷:作者甚至大膽地將輸入文檔截斷為 128 tokens,犧牲一點細節換取數倍的吞吐量 (Throughput)。
3.3 第三步:修正方向 (Updating Query Representation)
現在我們手上有了一組被 LLM 認證過的 「真實文檔」。我們用這些文檔的向量,把原本的 Query Vector 拉向正確的語意空間:
這裡有個魔鬼細節: 代表的是資料庫中既有的真實文檔向量。 這意味著什麼?意味著我們不需要在推論時重新算向量!這些向量早就存好在 Vector DB 裡了,我們只需要做極快的 Lookup 操作。這跟 HyDE 每次都要對新生成的虛構文檔做 Embedding 相比,運算量天差地遠。
4 實驗數據:真實世界不相信幻覺
實驗結果非常直接地打臉了生成式方法,特別是在我們最在意的低資源領域 (Low-Resource Domains)。
4.1 1. 誰在冷門領域更準?
作者在 BEIR Benchmark(包含生醫、財經、科學查核等特定領域資料集)上進行測試:
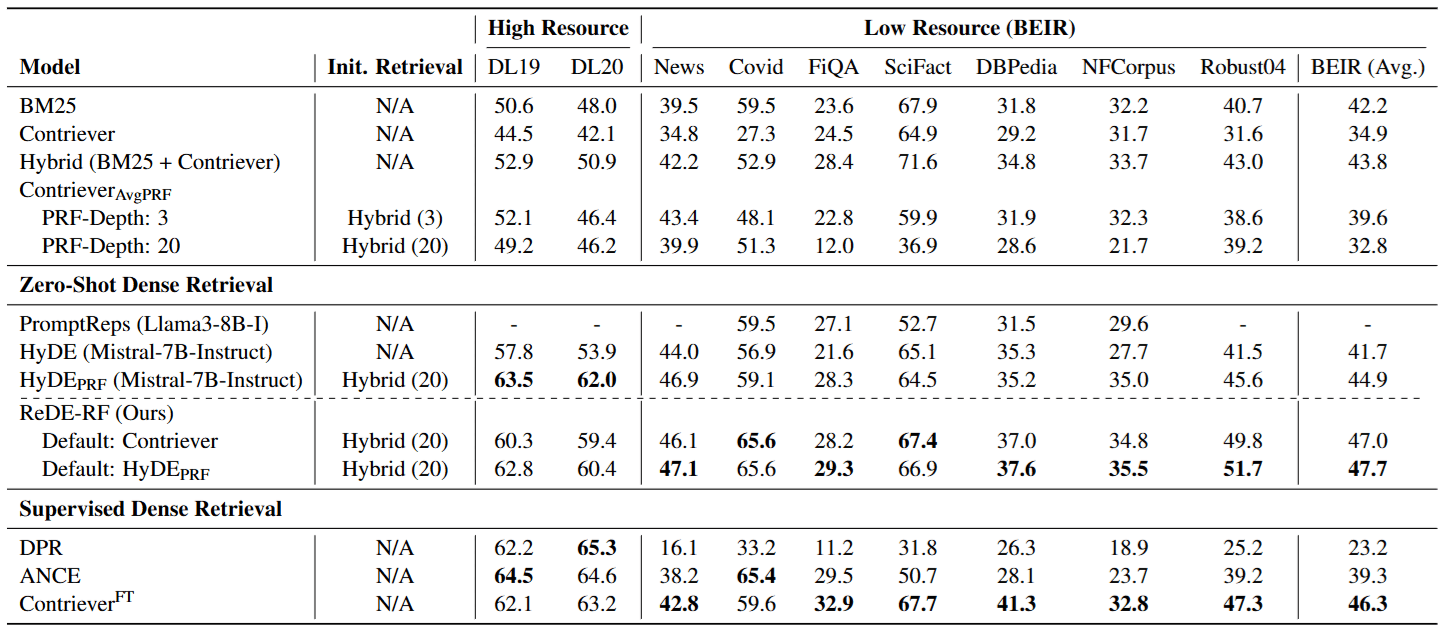
- HyDE 的失敗:在這些領域,LLM 因為不懂專有名詞,生成的虛構文檔充滿了誤導性的關鍵字。
- ReDE-RF 的勝利:因為它是基於真實文檔來修正 Query,所以永遠不會「無中生有」。它抓到的特徵(Feature)都是資料庫裡真實存在的。
4.2 2. 速度革命
這張圖應該會讓所有做系統架構的人感到興奮:
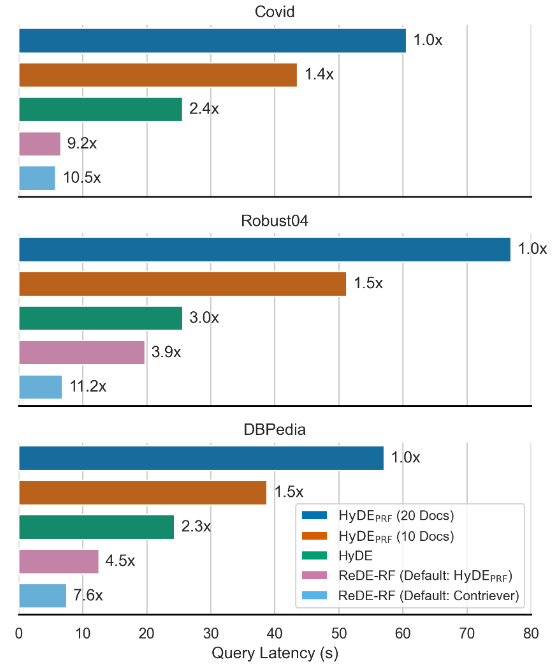
數據顯示,ReDE-RF 比標準 HyDE 快了約 4 倍,比 HyDE-PRF 快了 7 到 11 倍。這證明了「Logits 判斷」在工程落地上的巨大優勢。
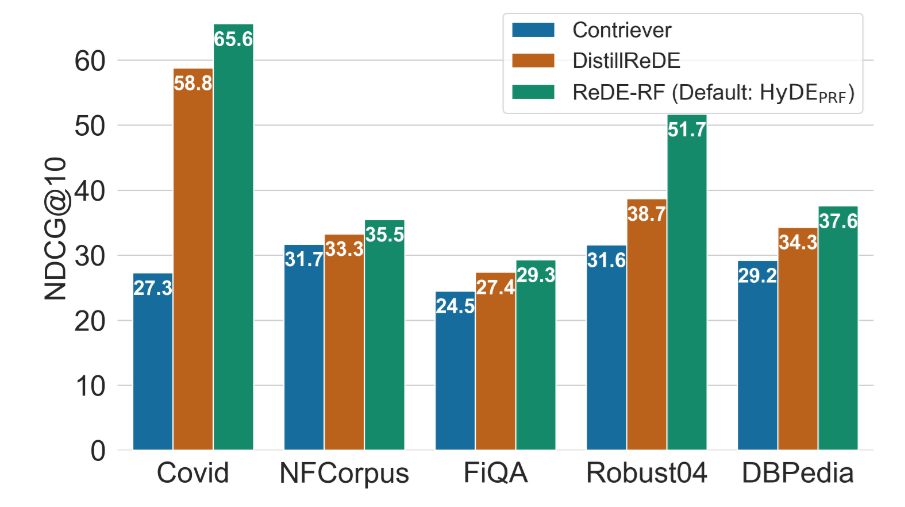
4.3 3. 可以蒸餾 (Distillation) 嗎?
如果我連 LLM 那一次 Forward Pass 都不想跑呢? 論文提出 DistillReDE:利用 ReDE-RF 產生的結果作為 Teacher,訓練一個小型的 Contriever 模型。 結果發現,這個小模型保留了絕大部分的效能提升(見下圖橘色 Bar),而且上線時完全不需要 LLM。
5 結論與啟發:Grounding on Reality
讀完這篇論文,我認為它給我們最大的啟發不僅僅是演算法層面的,更是思維模式的轉變。
過去一年,大家太迷信 Generative AI 的創造力,總想著讓 LLM 生成各種中間產物(Intermediate Steps)來輔助任務。但 ReDE-RF 告訴我們:在 AI 應用中,「判斷 (Judgment)」往往比「生成 (Generation)」更廉價、更準確,也更可控。
與其讓不懂醫學的 LLM 去「寫」一篇醫學論文來做搜尋關鍵字(HyDE),不如先隨便抓幾篇真的醫學論文,讓 LLM 負責「挑」出哪篇像是真的(ReDE-RF)。
“Grounding on Reality” —— 基於真實數據的修正,永遠比基於想像的修正來得可靠。這或許是我們在設計下一代 Agent 或 RAG 系統時,最值得深思的一點。