不只學「對」的,更要學「錯」的?深入解析 SENSE 如何用強弱 LLM 打造頂尖 Text-to-SQL 模型 (ACL 2024)

1 前言
本篇文章介紹 SENSE: Synthesizing Text-to-SQL Data from Weak and Strong LLMs 論文。本篇論文發表在 ACL 2024,論文的核心目標在於如何透過 Supervised Fine-Tuning (SFT) 訓練出一個厲害的 Text-to-SQL 模型。
本篇論文以 Data 的角度出發,提出一種基於 Weak 與 Strong LLM 各自產生不同性質的 Text-to-SQL Synthetic Data 方法,來提升開源模型 Fine-Tuning 後的表現。
作者最終 Fine-Tune 出來的模型稱為 SENSE,雖然有提供 GitHub,但在我撰寫本篇文章時,作者尚未將程式碼以及模型推上去。
2 SENSE 想解決的問題
SENSE 的目標透過 SFT 來提升開源模型的 Text-to-SQL 表現。既然要做 SFT 那會遇到的首要問題就是訓練資料的準備。為了更有效率的準備訓練資料,SENSE 採取 Synthetic Data Generation 的方法。
因此,SENSE 所要處理的問題就會在於:
要生成什麼樣的 Synthetic Data 才能讓模型在 Fine-Tune 後有更好的 Text-to-SQL 能力?
3 SENSE 所提出的方法
作者認為良好的 Text-to-SQL 的訓練資料,需要教會模型以下 2 件事情:
- 模型需要足夠的泛化能力,在看到訓練資料中所沒有的 Table Schema 時,也要能夠產生正確的 SQL
- 模型需要認識常見的 SQL 的錯誤寫法,來減少自己也犯下同樣的錯誤
基於上述兩點,SENSE 的方法可以分為兩個階段:
- 第一階段
- 目標: 讓模型具有足夠的 Text-to-SQL 泛化能力
- 方法: 透過 Strong LLM 來生成高品質資料 (Strong Data),再將模型以 SFT 訓練於 Strong Data 上
- 第二階段
- 目標: 讓模型認識 SQL 中的錯誤寫法
- 方法: 透過 Weak LLM 來生成常見的 SQL 錯誤語法 (Weak Data),再將模型以 DPO 訓練於 Weak Data 上
3.1 Strong Data: Supervised Fine-tuning
在 Strong Data 的準備上,作者透過 Prompting GPT-4 來進行 Synthetic Data 的生成。以下是作者所使用的 Prompt:
Your task is to generate one additional data point at the {the_level} difficulty level, in alignment with the format of the two provided data points.
1. **Domain**: Avoid domains that have been over-represented in our repository. Do not opt for themes like Education/Universities, Healthcare/Medical, Travel/Airlines, or Entertainment/Media.
2. **Schema**: Post your domain selection, craft an associated set of tables. These should feature logical columns, appropriate data types, and clear relationships.
3. **Question Difficulty** - {the_level}
- **Easy**: Simple queries focusing on a single table.
- **Medium**: More comprehensive queries involving joins or aggregate functions across multiple tables.
- **Hard**: Complex queries demanding deep comprehension, with answers that use multiple advanced featuresㄡ
4. **Answer**: Formulate the SQL query that accurately addresses your question and is syntactically correct.**Additional Guidelines**:
- Venture into diverse topics or areas for your questions.
- Ensure the SQL engages multiple tables and utilizes advanced constructs, especially for higher difficulty levels.
Ensure your submission only contains the Domain, Schema, Question, and Answer. Refrain from adding unrelatedcontent or remarks.
(...examples and generations goes here...)在每一次的生成中,作者都會從 Spider 的訓練資料集中,隨機選取兩個樣本作為上述 Prompt 中的 Few-Shot Examples。
當 Synthetic Strong Data 準備好之後,就會透過 SFT 的方式將模型進行第一階段的訓練,也就是最小化以下 Loss Function:
其中 是語言模型的參數,而 是给定 Input Prompt 時,模型產生目標 SQL Code 的條件機率。 則是 的整個 Sequence 的長度, 是 Auto-Regressive 的 Decoding Step。
3.2 Weak Data: Preference Learning
在 Weak Data 的準備上,作者透過 Prompting 比較小且弱的模型來進行 Synthetic Data 的生成:
- 基於一個自然語言所描述的問題, 透過 Weak LLM 得到 Generated SQL Code
- 將 Generated SQL Code 透過 SQL Executor 執行
- 如果 SQL Executor 的執行結果和 Ground-truth 吻合,則 Generated SQL Code 標記為 Positive Sample ;反之標記為 Negative Sample 。
建立好 Preference Dataset 後,就可以透過 DPO 再對模型進行訓練,也就是最大化以下 Objective Function:
4 SENSE 實驗結果
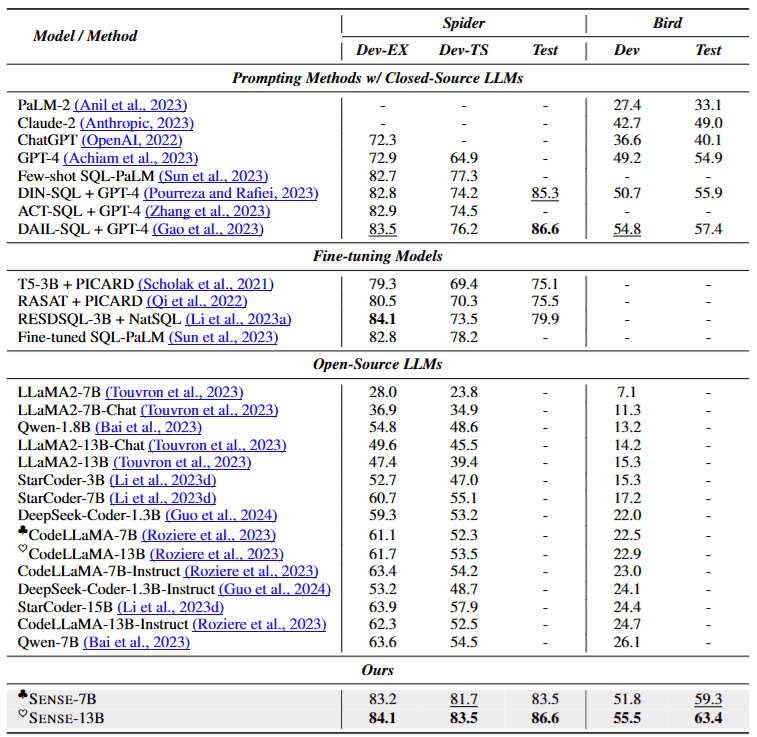
由上表實驗結果可以發現,Closed-Source 模型真的很強,單純透過 Prompting 就可以達到接近 SOTA 的效果;反之,Open-Source 模型的表現就相當不好。
從最後兩個列可以看到,作者分別基於 CodeLLaMA-7B 與 CodeLLaMA-13B 所訓練出來的 SENSE-7B 與 SENSE-13B 達到 SOTA 的表現!
5 結語
在本篇文章中,我們分享了一篇 ACL 2024 的論文 - SENSE: Synthesizing Text-to-SQL Data from Weak and Strong LLMs。從本篇論文中,我們學習到如何簡單透過 Weak LLM 與 Strong LLM 來建立 Synthetic Text-to-SQL Dataset,並透過 SFT 與 DPO 等兩個階段的訓練,大幅提升 Open-Sourced 模型在 Text-to-SQL 上的表現。