[EMNLP 2025] TableRAG 深度解析:表格不是拿來「讀」的,是用 SQL 來「查」的!

1 前言
在當前的企業級 RAG 應用中,我們面臨最大的痛點往往不是「找不到文件」,而是「讀不懂文件中的結構化數據」。當一份財報或規格書同時包含落落長的文字描述與精密的數據表格時,傳統 RAG 往往會顧此失彼。
這篇發表於 EMNLP 2025 的論文 TableRAG,正是為了這個真實世界的難題而生。它提出了一個優雅的解決方案: 不要試圖把表格當作文字來讀,而是讓它們回歸數據的本質。
TableRAG 是一個專為「異質文檔 (Heterogeneous Documents,即文字與表格混合) 」設計的 RAG 框架。它摒棄了傳統將表格「壓扁」成文字進行向量檢索的做法,轉而採用 雙軌並行 (Dual-Track) 策略:
- 非結構化文字: 依然使用向量檢索 (Vector Search) 處理語意理解。
- 結構化表格: 引入 SQL 作為符號化執行引擎 (Symbolic Execution) ,確保數據查詢與運算的精確性。
透過一個 Online Iterative Reasoning 迴圈,TableRAG 能夠像剝洋蔥一樣,層層拆解複雜的多跳 (Multi-hop) 問題,最終結合文字檢索與 SQL 查詢的結果,給出精準答案。
這篇論文的價值在於它 「承認了 LLM 的局限性」。作者不強求 LLM 去做它不擅長的數學運算或全表掃描,而是讓 LLM 扮演「指揮官」與「程式設計師」,將繁重的數據操作外包給最擅長此事的 SQL 資料庫。這種 「各司其職」的系統設計思維,是構建可靠 AI 應用的關鍵。
2 問題定義
在深入 TableRAG 的架構之前,我們必須先理解它誕生的背景: 表格 (Table) 與自然語言 (Text) 有著本質上的不同。
2.1 現有 RAG 的三大痛點
傳統的 RAG 技術在處理純文字文檔時表現優異,但當面對企業常見的「異質文檔 (Heterogeneous Documents,即文字夾雜表格) 」時,我們發現主流做法 (將表格轉為 Markdown 文字並切塊) 會導致三個致命缺陷:
結構性資訊的流失 (Structural Information Loss)
- 現狀: 為了讓向量資料庫能吃進去,我們通常把二維的表格「壓扁」成一維的 Markdown 文本,然後像切蛋糕一樣切成多個 Chunk。
- 後果: 表格的行 (Row) 與列 (Column) 之間強烈的邏輯關聯被打斷了。比如表頭在第一個 Chunk,數據在第二個 Chunk。檢索時,模型往往只抓到數據卻丟失了表頭的定義,導致 LLM 看著數字卻不知道這是「營收」還是「成本」。
缺乏全局視野 (Lack of Global View)
- 現狀: RAG 的黃金標準是 “Top-N Retrieval”。
- 後果: 這對查找單一事實有效,但對於需要「全局統計」的問題 (Global Queries) 是災難。
- 案例回顧: 如果我們問「2023 年所有產品的平均價格是多少?」,RAG 可能只檢索到表格的前 5 行 (Top-N) 。LLM 只能基於這 5 行算平均值,答案絕對是錯的。因為它從未看過「整張表」。
複雜推理能力的不足 (Reasoning Limitations)
- 現狀: 我們強迫 LLM 去做它不擅長的事——大數運算與多步驟邏輯。
- 後果: 雖然 LLM 能寫詩,但叫它去算一個 50 行表格的加權平均,它很容易出現幻覺 (Hallucination) 。即使是 GPT-4,在面對長文本中的分散數據時,計算能力也不如一個簡單的計算機。
2.2 核心洞見
TableRAG 的作者意識到,要解決這些問題,不能再把表格當作文字來處理。他們的解決方案直擊本質:
Text is for Reading, Tables are for Querying.
因此,TableRAG 提出了一種 Hybrid 的推理路徑: 保留向量檢索來處理文字語意,但引入 SQL 作為表格的「專屬語言」。這不僅解決了視野問題 (SQL 可以 SELECT *) ,也解決了計算問題 (SQL 的 AVG() 絕對準確) 。
3 方法介紹
TableRAG 並不是一個單一的模型,而是一個精心設計的系統框架。我們可以將其運作流程分為兩個階段: 「離線建置」與「線上推理」。
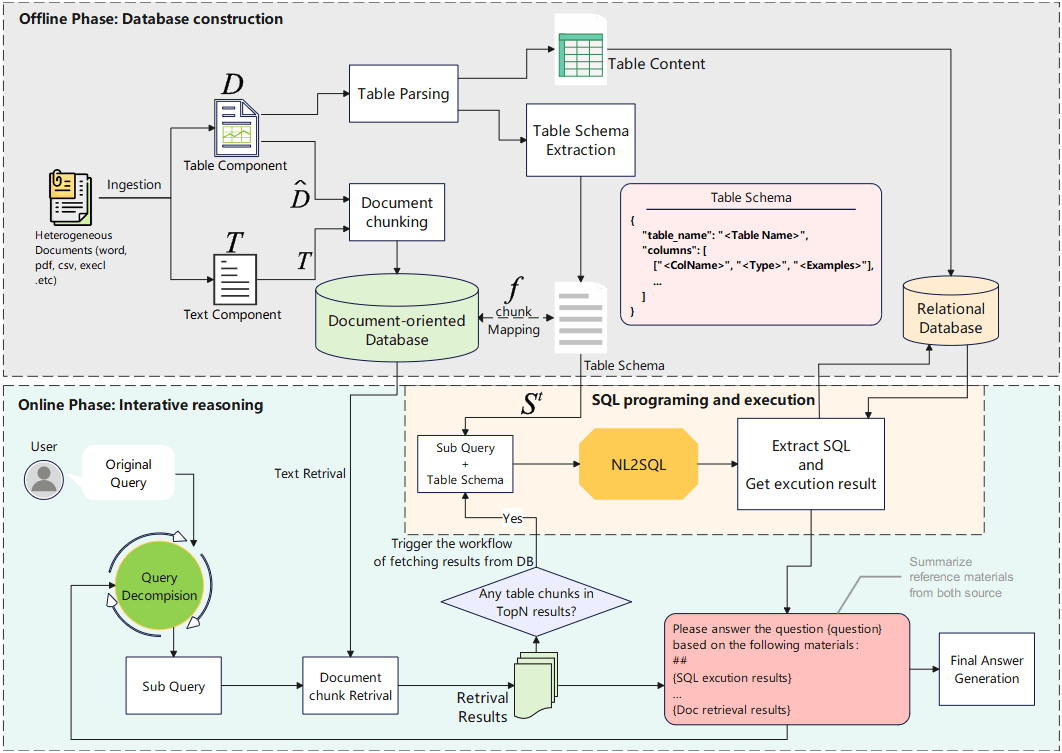
3.1 離線階段: 資料庫建置 (Offline Database Construction)
在我們之前的討論中,我們將這個階段總結為 「一源三存」 策略。為了讓系統既能「讀懂」也能「執行」,TableRAG 將同一個表格處理成三種形式:
3.1.1 Textual Knowledge Base —— 為了檢索
這是為了讓向量檢索模型 (Embedding Model) 能找到表格。
- 作法: 將表格轉換為 Markdown 格式,若表格過大則進行切塊 (Chunking) 。
- 目的: 當使用者問「2012 澳洲電影…」時,系統能透過語意相似度,先撈到這些 Markdown 片段作為「索引卡」。這些片段記為 。
3.1.2 Tabular Schema Database —— 為了理解結構
這是連結「模糊語意」與「精確執行」的橋樑。
- 作法: 對每個表格 ,提取其標準化結構描述 ,包含表名、欄位名稱、資料型態。
- 關鍵機制: Mapping Function 這是一個至關重要的映射函數: 它的意思是: 當我們檢索到第 個 Markdown 片段 時,系統能透過這個函數,立刻反查到其背後完整的 Table Schema 。這讓 LLM 即使只看到表格的一角,也能瞬間掌握全貌。
3.1.3 Relational Database —— 為了執行
- 作法: 將原始數據匯入標準的 SQL 資料庫 (如 MySQL) 。
- 目的: 這是 SQL 程式碼實際跑的地方,保證運算的絕對精確。
這就是我們所說的「分而治之」。
- Markdown 片段 是「誘餌」,用來被檢索。
- Schema 是「地圖」,告訴 LLM 表格長什麼樣。
- MySQL 是「引擎」,負責執行繁重的數據計算。
3.2 線上階段: 四步驟推理 (Online Iterative Reasoning)
一旦資料庫準備就緒,TableRAG 就進入了線上推理模式。這是一個 Loop,系統會不斷重複以下四個步驟,直到解決使用者的問題。
3.2.1 Context-Sensitive Query Decomposition
這是系統的大腦。面對複雜問題 (e.g. Multi-Hop Question) ,LLM 需要決定「下一步該做什麼」。
- 為什麼叫 “Context-Sensitive”? 這個步驟並非憑空發生。在分解問題之前,系統會先進行一次檢索,讓 LLM 看到相關的 Markdown 片段 (即 Schema 資訊) 。
- 運作邏輯:
LLM 就像看著菜單點菜。它看到檢索回來的 Schema 中有
Revenue和Cost欄位,才會生成「計算 Profit」的子問題。這避免了 LLM 幻想出不存在的欄位 (Hallucination) 。 - Prompt 實作細節: 雖然論文的 Prompt Template 看起來是靜態的,但實際上這是一個 ReAct Agent。每一輪的輸出 (Thought/Action) 和執行結果 (Observation) 都會被動態加入到對話歷史中,讓 LLM 知道「我已經查過 A 了,現在該查 B」。
3.2.2 Text Retrieval
針對 Step 1 生成的子問題 ,系統進行檢索:
- Recall: 使用向量檢索撈出 Top-N 相關片段。
- Rerank: 使用 Cross-Encoder 精選出 Top-k 片段 () 。
- 關鍵點: 這裡的檢索結果混合了「純文字」與「表格 Markdown 片段」。
3.2.3 SQL Programming and Execution
這是 TableRAG 的殺手鐧。
- 觸發條件: 系統檢查 Step 2 的 Top-k 結果中是否包含表格片段?
- 若無: 跳過此步 (退化為傳統 RAG) 。
- 若有: 啟動 SQL 引擎。
- 執行流程:
- 利用 Mapping Function 獲取完整 Schema。
- LLM 根據子問題 與 Schema 生成 SQL 語句 (例如:
SELECT AVG(score) FROM students) 。 - 將 SQL 丟給 MySQL 執行,得到精確結果 。
3.2.4 Compositional Intermediate Answer Generation
現在,LLM 手上有兩份證據:
- 檢索到的文字 (可能包含上下文或定性描述) 。
- SQL 執行結果 (精確的定量數據) 。
- 衝突解決與加權 (Adaptive Weighting):
這裡沒有數學公式,而是透過精妙的 Prompt Engineering 實現「軟性加權」:
- 若 SQL 執行失敗 (語法錯誤) ,Prompt 指示 LLM 忽略 SQL,全權依賴文字。
- 若兩者一致,直接輸出。
- 若兩者衝突,LLM 被指示進行 交叉比對 (Cross-Examination),通常優先採信 SQL 的數據結果,但會參考文字的上下文解釋。
3.3 迭代與終止 (Iteration & Termination)
生成中間答案 後,系統會回到 Step 1,評估原始問題是否已解決。
- 已解決: 輸出最終答案 。
- 未解決: 利用 作為新的上下文,生成下一個子問題 ,繼續迴圈。
4 實驗結果
為了驗證 TableRAG 的效能,作者進行了極為嚴苛的測試。我們不僅要看它贏了多少,更要看它在什麼樣的場景下展現出絕對優勢。
4.1 實驗設置: 涵蓋三大維度的挑戰
實驗使用了三個 Datasets ,分別代表了不同的難度維度:
- WikiTQ: 側重於複雜的表格操作 (如聚合、比較) ,考驗 SQL 的精確度。
- HybridQA: 標準的文本與表格混合數據集,考驗整合能力。
- HeteQA (本文提出): 專門設計的多跳異質推理 (Multi-hop Heterogeneous Reasoning) ,這是最接近真實場景、難度最高的數據集。
4.2 關鍵成效: 為什麼 TableRAG 能全面制霸?
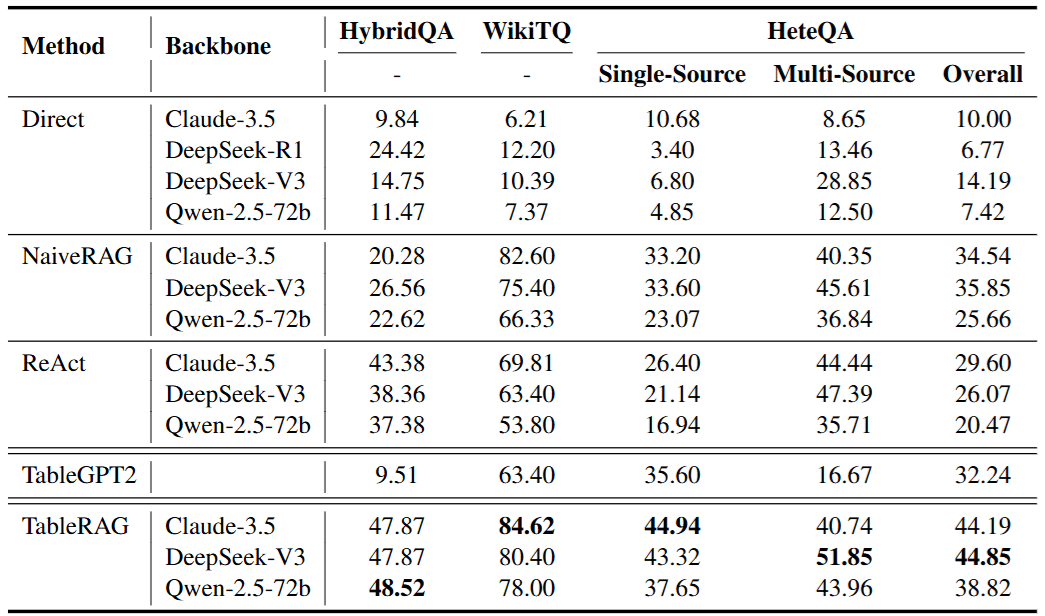
從 Table 1 的數據中,我們讀出了這幾個關鍵故事:
- 完勝 NaiveRAG: NaiveRAG (將表格線性化) 在 WikiTQ 這種需要精確計算的場景表現極差。這證明了 「把表格當文字讀」是有天花板的,一旦涉及運算,向量檢索就會失效。
- 超越 ReAct 的關鍵在於「不碎裂」: ReAct 雖然也是迭代推理,但在 HeteQA 的 Multi-source 場景表現不如 TableRAG。原因在於 ReAct 傾向於將問題拆得「太碎」,導致推理鏈過長而崩潰;而 TableRAG 透過 SQL 將複雜的表格操作「塌縮」成一次精確執行,大幅提升了穩定性。
- TableGPT2 的致命傷: TableGPT2 雖然擅長寫 Python/Pandas,但在 HeteQA (包含大量文本資訊) 中表現大幅下滑。這證明了 「只有表格能力是不夠的」,缺乏文本檢索能力的系統無法處理現實世界的複雜文件。
4.3 消融實驗: 拆解「雙軌並行」的貢獻
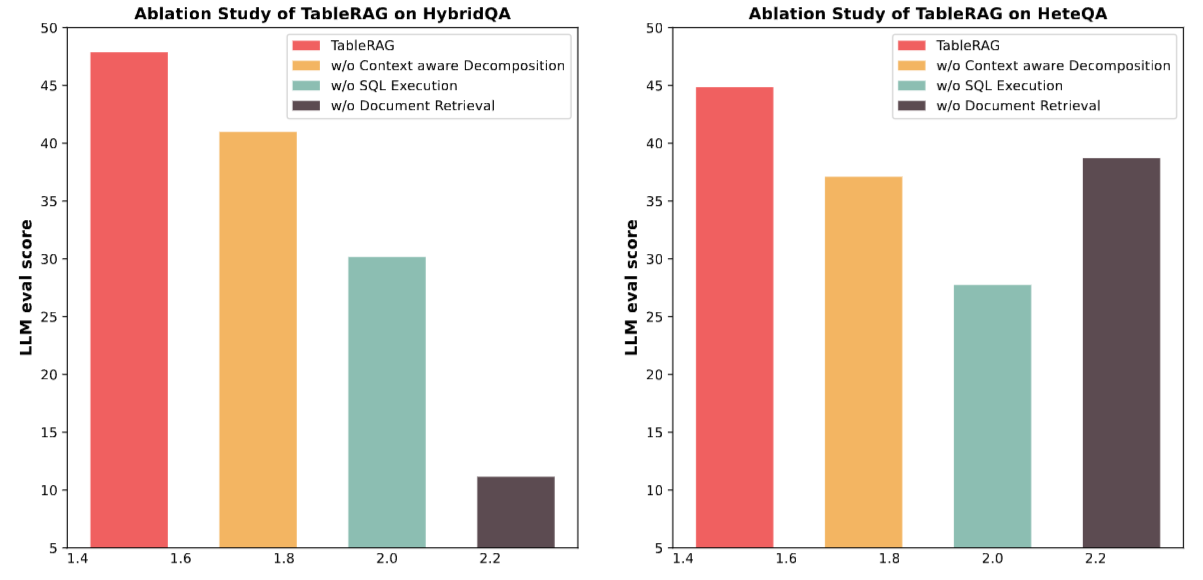
我們在分析 Figure 4 時有了一個重要的發現:
- 拿掉 SQL (w/o SQL Execution): 在 HeteQA 上的性能急劇下降。這說明了當問題涉及多個表格步驟時,單靠 Markdown 表格片段檢索完全無法應對。
- 拿掉文本檢索 (w/o Text Retrieval): 在 HybridQA 這種高度依賴上下文資訊的數據集上,表現幾乎崩盤。
- 結論: 這證實了我們的核心洞見——文字與表格是互補的。SQL 提供了精確度,而檢索提供了上下文。
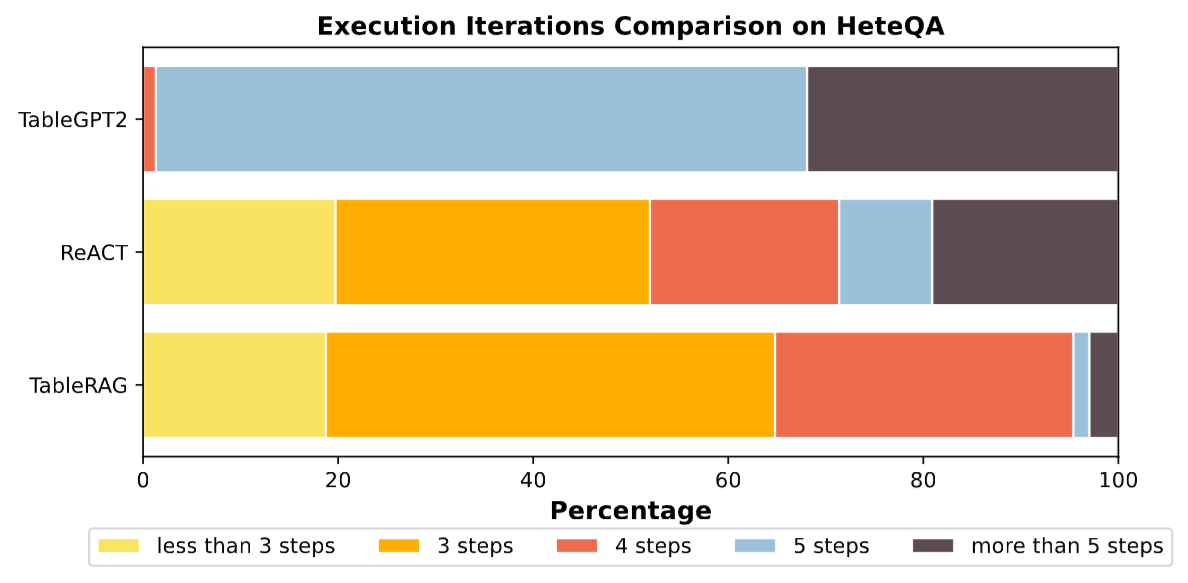
4.4 效率分析: 更快、更準、更省
5 結論
5.1 總結
這篇論文精準捕捉到了現有 RAG 系統在處理「異質文檔」時的無力感。
- 挑戰: 表格被壓扁導致結構喪失,且 Top-N 檢索導致無法全局計算。
- 對策: 提出 TableRAG 框架,透過「離線一源三存」與「線上迭代推理」實現雙軌並行。
- 成果: 在多個基準數據集上達成 SOTA,並證明了基於 SQL 的符號執行能顯著提升複雜推理的準確度與效率。
5.2 限制與展望
儘管 TableRAG 非常強大,但我們也要清醒地看到它的限制:
- 模型依賴性: 其效能高度依賴於底層 LLM (如 Claude-3.5 或 DeepSeek-V3) 的 Text-to-SQL 能力與邏輯拆解能力。若使用較弱的小模型,系統表現會顯著退化。
- 跨語言能力的缺失: 目前的測試與 Benchmark (HeteQA) 僅限於英文。
- SQL 容錯性: 雖然有衝突解決機制,但若 SQL 生成出現邏輯錯誤 (而非語法錯誤) ,系統仍有誤導 LLM 的風險。未來的改進方向可以引入多個 SQL 候選進行自我檢驗。