UniversalRAG 深度解析:破解多模態 RAG 偏見,提升異質數據的檢索能力

1 前言
在開始深入細節之前,我們得先認識這篇由 KAIST 團隊所提出的作品: UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities。如果你想看更直觀的 Demo 或程式碼,可以參考他們的 Project Page。
為什麼這篇論文值得我們關注?
傳統的 RAG 系統就像一個只能翻閱「文字書籍」的圖書館管理員,即便現在有了多模態 RAG,它們通常也只能在單一的模態 (例如: 只查影像或只查文字) 中運作。然而,真實世界的問題是複雜的,有時答案藏在一段影片的某個瞬間,有時則需要對比一張設計圖與一份技術文件。
UniversalRAG 的核心思維是: 與其強行將所有模態對齊到同一個混亂的向量空間,不如建立一個聰明的「Router (Router) 」,實現「先診斷、後抓藥」的精準檢索。
這篇筆記我們將會涵蓋:
- 核心策略: 如何透過 Modality-aware Routing 避開檢索偏見 (Modality Gap) 。
- 粒度控制: 如何動態決定檢索的資訊大小 (從短段落到整部影片) 。
- 實作細節: 訓練型 (Training-based) 與免訓練 (Training-free) Router 的具體作法。
- 實務思維: 針對企業私有數據 (如 Table vs. Text) 的落地挑戰與解決方案。
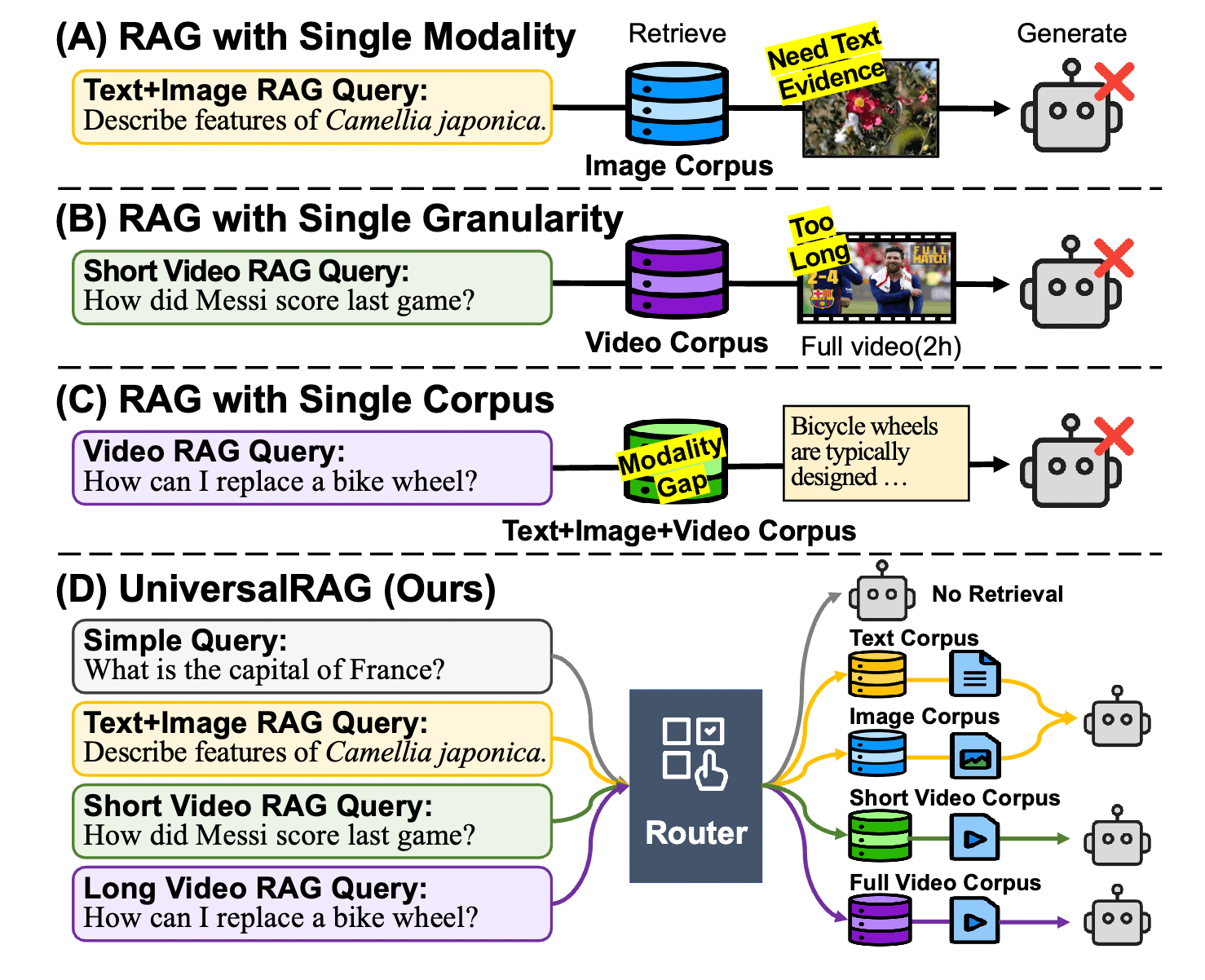
在這篇論文中,作者精確地指出了目前 RAG 系統在邁向「通用化」道路上所遭遇的三大核心挑戰。我們在前面的討論中也提到,這些問題在處理企業級私有數據時會變得更加棘手。
2 問題定義:既有 RAG 系統面臨的三大瓶頸
雖然 RAG 已經顯著提升了大型語言模型的準確性,但現有的解決方案通常假設知識來源是單一且同質的 (Homogeneous) 。然而,現實世界的知識是破碎且異質的。
以下是我們必須克服的技術難關:
2.1 Modality Limitation
大多數傳統的 RAG 系統僅限於純文本檢索。雖然近期有些研究延伸到了影像或影片,但它們通常僅操作於單一模態的特定語料庫。
- 痛點:用戶的問題多變,有些需要查閱產品手冊 (文字) ,有些需要觀看組裝教學 (影片) 。如果系統只能處理單一模態,就無法回答那些需要「跨模態證據」的問題。
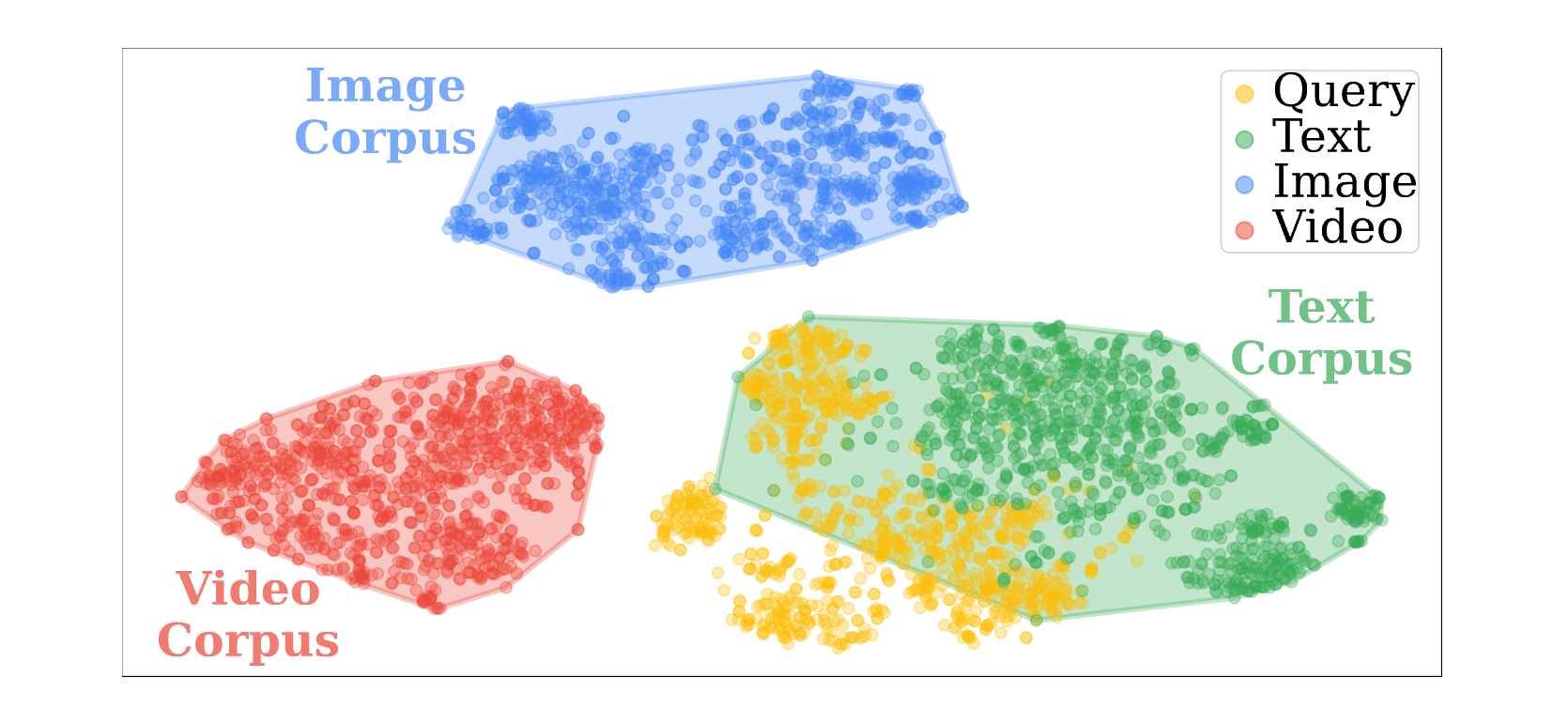
2.2 Modality Gap in Embedding Space
為了解決多模態問題,最直觀的方法是使用如 CLIP 這樣的多模態編碼器,將文字、圖片和影片全部映射到同一個向量空間進行相似度檢索 (Unified Embedding Space) 。然而,這會導致嚴重的模態偏見。
- 現象:在向量空間中,資料點傾向於根據「模態」而非「語意」進行聚集。這意味著文字查詢與文字資料的距離,往往比它與語意更相關的影像資料還要近。
- 後果:當我們輸入一個文字問題時,系統會因為模態相近而優先抓取文字內容,即便最正確的答案其實藏在圖片或影片裡。
2.3 Granularity Mismatch
數據的「大小」或「長度」——也就是檢索粒度 (Granularity) ,對生成品質有著決定性的影響:
- 太細碎 (Too Fine-grained):例如檢索一個極短的句子。這雖然精準,但往往會遺漏回答複雜邏輯問題所需的上下文環境 (Context) 。
- 太粗略 (Too Coarse-grained):例如為了回答一個 10 秒鐘的動作問題,卻抓取了整段兩小時的影片。這會引入大量無關雜訊,干擾模型生成,且極度浪費計算資源。
現有的 RAG 系統通常固定在某一種檢索單位 (如 Paragraph-level) ,缺乏靈活調整的能力。
2.4 Efficiency & Scalability
當我們試圖建立一個包含所有模態、所有粒度的「超級索引庫」時,檢索延遲會隨著資料量 的增加而線性或對數增長。在處理千萬級別以上的企業數據時,搜尋成本與速度將成為不可忽視的負擔。
針對前面提到的種種挑戰,UniversalRAG 提出了一套「先診斷,後掛號」的聰明架構。我們不需要一個萬能的向量空間來容納所有資料,而是需要一個萬能的**指揮中心 (Router) **來決定去哪裡找資料。
以下我們將深入探討這個方法設計背後的邏輯與實作細節。
3 方法介紹:UniversalRAG 的核心架構
UniversalRAG 的設計核心在於將檢索過程從「單一空間搜尋」轉變為「動態路徑選擇」。整個流程可以分為三個階段:Routing、Targeted Retrieval 與 Generation。
3.1 模態與粒度的階層化組織
為了實現精準檢索,我們不能把資料隨便亂丟。UniversalRAG 建議將資料庫根據模態與粒度進行「解耦」:
- 文字模態:分為
Paragraph(段落級) 與Document(文件級,適合多跳推理) 。 - 表格模態:獨立的
Table索引,專門處理結構化數據。 - 影像模態:
Image索引,保留原始視覺特徵。 - 影片模態:分為
Clip(短片段,定位特定動作) 與Video(整部影片,理解長時序劇情) 。
這樣的組織方式確保了每個資料庫都能使用最適合該模態的編碼器 (Encoder) ,避開了強行對齊產生的模態鴻溝。
3.2 The Router
Router 的任務是分析 Query 的意圖,並從 7 個 Pathways 中選出最佳組合。
3.2.1 Router’s Label Space
Router 並非做單選題,而是多選題。它會從以下這組 Modality-Granularity Pair 中挑選:
None: 直接回答,不需檢索。Paragraph: 文字 - 細粒度。Document: 文字 - 粗粒度。Table: 結構化表格。Image: 靜態影像。Clip: 影片 - 細粒度。Video: 影片 - 粗粒度。
3.2.2 Training-based Router
當我們有固定的硬體資源且追求極速時,會採用微調 (Fine-tuning) 輕量化模型 (如 Qwen3-VL-2B) 的做法。
- 自動標籤生成:因為現實數據缺乏標籤,作者利用了 Inductive Bias。例如,來自
WebQA的問題自動標記為Paragraph+Image。 - 損失函數 (Loss Function):這是一個多標籤分類問題。我們對模型輸出的每個類別 的邏輯值 進行 Sigmoid 轉換得到機率 : 接著使用 二元交叉熵 (Binary Cross-Entropy) 來計算總損失: 其中 是真值標籤 (0 或 1) 。在推論時,只要機率超過閾值 ,該路徑就會被啟動。
3.2.3 Training-free Router
這對於我們討論過的企業私有數據 (OOD) 特別有效。我們直接透過 Prompt Engineering 讓強大的 LLM (如 GPT-4o) 進行決策。

這個 Prompt 的設計邏輯在於 「意圖識別」:
- 如果問題涉及「比較、加總、數值」,引導至
Table。 - 如果涉及「外觀、顏色、結構」,引導至
Image。 - 透過 Few-shot 範例教會模型處理複雜意圖 (例如:
Paragraph+Clip) 。
3.3 Generation
一旦 Router 決定了路徑 (例如:Paragraph+Image) ,系統會:
- 並行檢索:同時去文字段落庫和影像庫中搜尋最相關的 Top-K 證據。
- 證據整合:將找回來的文字碎片與影像特徵同時餵給多模態大模型 (LVLM) 。
- 生成回答:模型根據多模態證據進行綜合推理,給出最終答案。
3.4 為什麼這套方法有效?
UniversalRAG 的優雅之處在於它解決了「模態偏見」。
過去的方法是把問題和圖片放在一起算相似度,但文字問題天生就比較親近文字資料。而 UniversalRAG 的路由機制是在 「語義層級」 做決策。當 Router 說「這題要看圖」,系統就只會去影像庫裡搜尋,徹底切斷了模態之間的互相干擾。
在理解了 UniversalRAG 的設計藍圖後,我們必須用數據來驗證這套「指揮中心」策略是否真的優於傳統的做法。實驗結果不僅證明了準確度的提升,更揭示了它在處理大規模數據時的效率優勢。
4 實驗結果
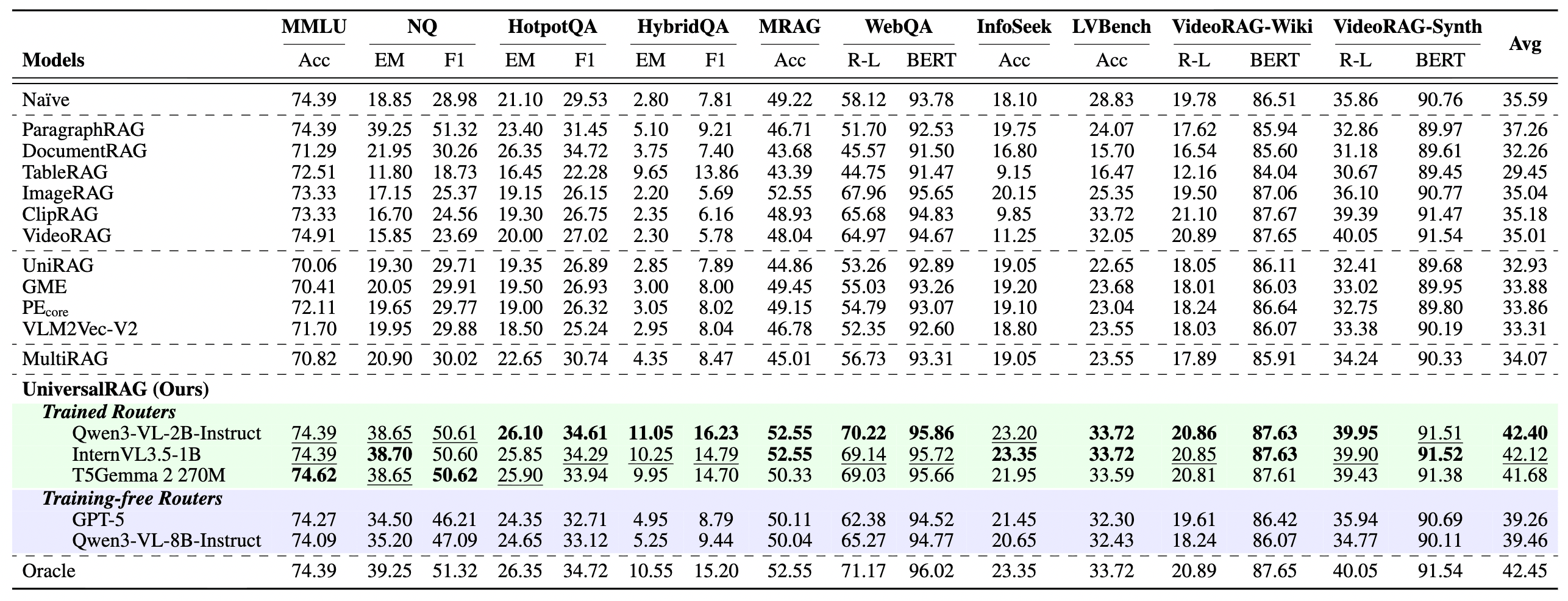
作者在 10 個涵蓋不同模態與粒度的基準測試 (Benchmarks) 上進行了廣泛評估。以下是我們認為最值得關注的幾個關鍵發現:
4.1 全方位的性能領先
在多樣化的 RAG 任務中,UniversalRAG 展現了強大的統治力。無論是單純的文字查詢、圖文結合,還是複雜的影片分析,UniversalRAG 的表現都顯著優於單一模態的 RAG 以及傳統的統一嵌入空間方法。
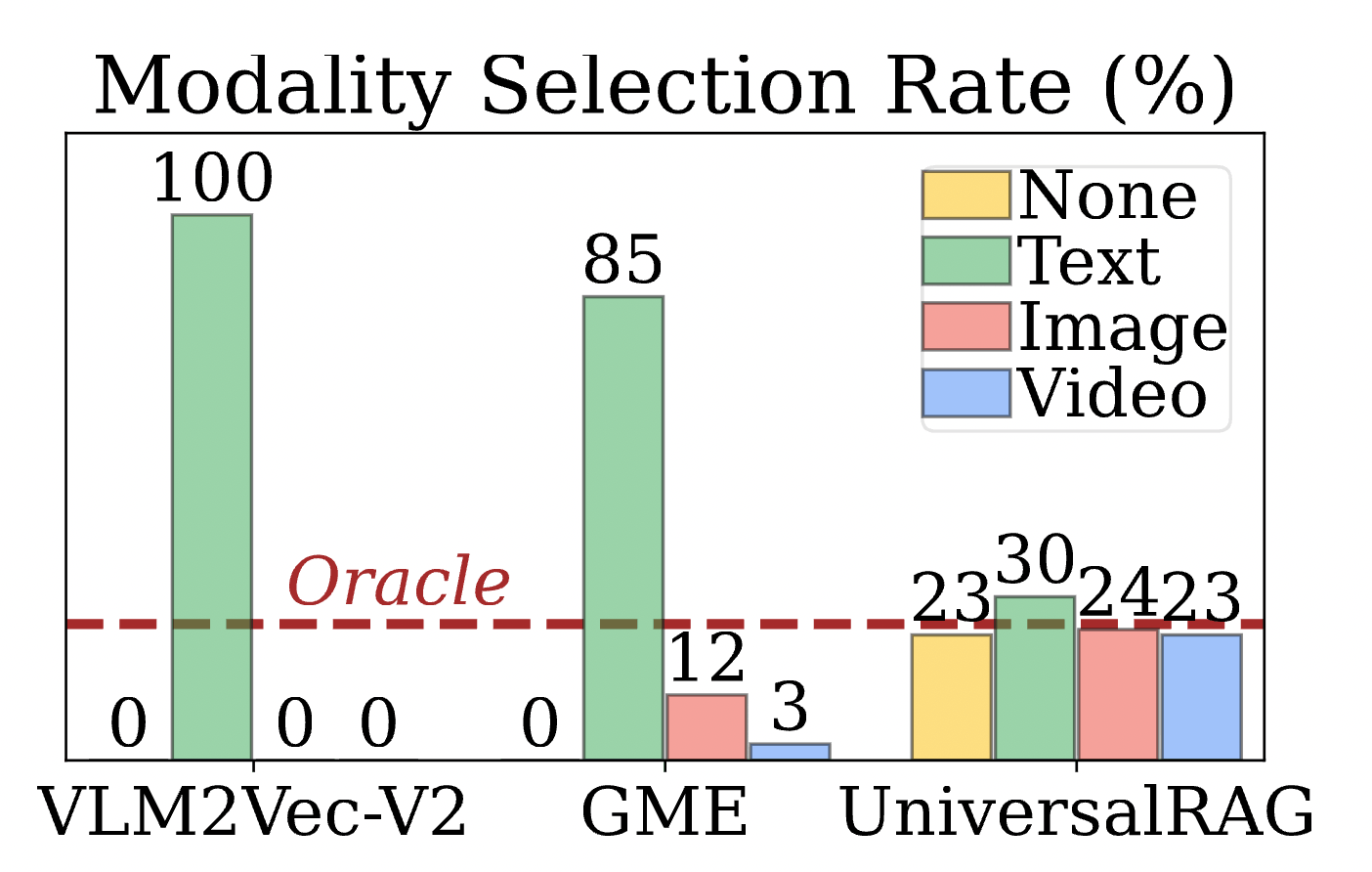
4.2 成功跨越 Modality Gap
這是我們討論中最核心的論點:傳統的 Unified Embedding 真的有偏見嗎?實驗給出了肯定的答案。
- 發現:如 Figure 4 所示,像 GME 或 VLM2Vec 這類將所有模態擠在一起的模型,在檢索時表現出極強的「文字偏見」——即便問題需要影像或影片證據,它們仍傾向於抓取文字。
- 對比:UniversalRAG 的路由器能精準地根據問題意圖分配檢索路徑。這證明了 「先路由、再檢索」 能有效繞過模態鴻溝,讓正確的證據被召回。
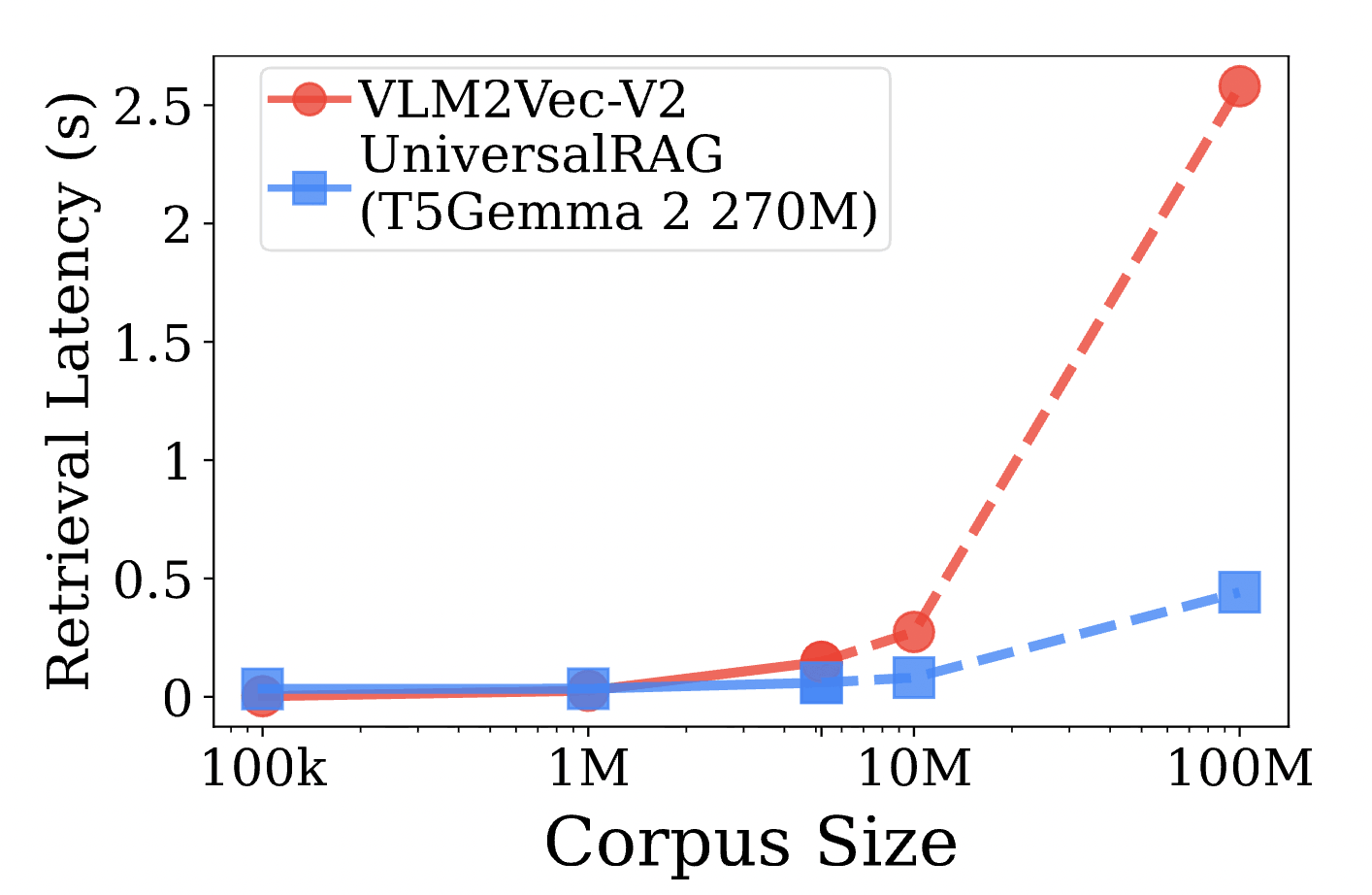
4.3 Scalability
對於我們之前擔心的企業級大規模數據應用,Figure 5 提供了非常有力的支持。
- Sub-linear Latency:在傳統 RAG 中,隨著資料庫 的增加,搜尋時間通常會線性或對數增長。但在 UniversalRAG 中,因為路由器先行過濾掉了無關的庫,實際搜尋的範圍縮小到了 。
- 大數據優勢:當資料規模達到千萬 (10M) 甚至億級時,UniversalRAG 的延遲遠低於統一檢索方法。這意味著路由器的開銷在大規模場景下是完全值得的。
經過了前言的導讀、問題的剖析、方法的詳解以及實驗的驗證,我們終於來到了這篇筆記的終點。這篇論文不僅僅是提出了一個新的 SOTA 模型,更重要的是它為我們提供了一種處理「異質知識」的全新思維。
5 結論
UniversalRAG 的出現,標誌著 RAG 技術從「單一語料庫」向「全能型知識檢索」邁出了一大步。透過這篇論文與我們深入的討論,我們可以總結出以下三個核心啟示:
5.1 Routing 是解決模態鴻溝的銀彈
我們過去習慣於追求一個萬能的「對齊向量空間」,希望文字、圖片、影片能在同一個維度下共存。但 UniversalRAG 告訴我們:強行對齊會帶來偏見。透過在語意層級進行路由,讓每種數據保留其最原始、最專精的表示方式,反而能獲得更公平、更準確的檢索結果。這種「解耦 (Decoupling) 」的思想,是解決複雜多模態問題的關鍵。
5.2 效率與準確度的雙贏
在處理大規模數據時,我們往往擔心系統變得臃腫。UniversalRAG 透過「先診斷、後抓藥」的策略,證明了增加一個輕量級的路由器 (甚至只需要 規模的模型) 不僅不會拖慢系統,反而能在大規模語料庫下實現「子線性」的延遲增長。這為我們在工業界部署超大規模 RAG 系統提供了實質的信心。
5.3 從研究到實務的轉化
雖然論文在 Benchmark 上表現優異,但面對企業內部的私有數據 (Private Data) ,我們總結出了一套更具溫度的落地策略:
- 初期 (冷啟動):採用「免訓練路由器 (Prompt-based) 」並結合「混合檢索 (Hybrid Search) 」,確保系統的穩定性與召回率。
- 中期 (積累期):利用 Teacher LLM 對真實的 User Logs 進行自動化標記,區分出 Table、Text 與 Image 的使用邊界。
- 後期 (優化期):訓練專屬於企業環境的輕量化路由器,實現真正的「UniversalRAG」形態。