VideoDR:多模態 AI 的新戰場 — 當「影片理解」遇上「開放網路搜尋」的挑戰與機遇

1 前言
在人工智慧的研究浪潮中,我們見證了 Video Understanding 與 Agentic Search 各自的飛速發展決。然而,這兩個領域之間長期存在著一道鴻溝。今天要探討的這篇論文 《Watching, Reasoning and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning》 (以下簡稱 VideoDR),正是為了填補這塊拼圖而生。(arXiv 原文 | GitHub)
1.1 一分鐘摘要
這篇論文定義了一個全新的任務 —— Video Deep Research。不同於以往「答案就在影片裡」的封閉式問答,這個任務要求 AI 模型必須先從影片中提取視覺線索 (Visual Anchors),轉化為搜索查詢,並在 Open Web 上進行多步檢索與推理,才能找到最終答案。作者構建了一個經過嚴格「雙重消融測試」的高難度 Benchmark,並對比了 Workflow 與 Agentic 兩種主流範式,揭示了模型在處理長序列任務時面臨的「目標漂移」挑戰。
1.2 核心價值
在我們深入探討之前,必須先釐清這篇論文解決了什麼「痛點」。
突破「封閉式證據」的限制: 傳統的 Video LLMs 評測 (如 Video-MME) 假設所有答案都在影片裡。但在現實生活中,影片往往只是「引子」。例如,看到旅遊 Vlog 裡的某個無名雕像,我們想知道它的歷史背景。這需要模型跳出影片,走向網路。
彌補「純文字搜索」的不足: 現有的 Search Agents (如 Search-o1) 大多從文字問題出發。然而,視覺資訊具有不可替代性。很多時候,我們無法用文字精確描述影片中的物體,必須依賴模型對「多幀視覺信號」的理解與提取。
對 Agent 架構的現實檢驗: 業界對於該用穩定的 Workflow 還是靈活的 Agent 一直爭論不休。這篇論文提供了一個公平的競技場,讓我們看清了兩者的邊界。
1.3 導讀: 最讓我們驚豔的洞見
這篇論文最讓我們印象深刻的並非某個新模型架構,而是其對問題本質的深刻剖析與反直覺的實驗結果。以下是貫穿整份論文的兩個核心觀點:
VideoDR 最精彩的地方在於它對數據集的「潔癖」。作者通過一種否定式的定義來篩選數據:
- 如果不上網只看片能回答 -> 刪除 (這是傳統 Video QA) 。
- 如果不看片只上網能回答 -> 刪除 (這是 Text Search) 。
留下來的,是那些必須先看懂影片中的視覺暗示 (Visual Anchors),才能構建出有效搜索策略的問題。
2 問題定義
2.1 現狀的斷裂: 兩座孤島
在我們深入研究 VideoDR 之前,我們必須先理解為什麼這個領域需要這篇論文。在 VideoDR 出現之前,多模態 AI 的研究彷彿被割裂在兩座互不相通的孤島上:
- 孤島 A: 封閉式影片問答
- 現狀: 傳統的 Benchmark (如 Video-MME, MVBench) 假設答案就在影片裡。模型只需要具備足夠強的視覺感知能力,就能從畫面、字幕或旁白中提取答案。
- 痛點: 這與現實脫節。當我們看完一部旅遊 Vlog,想知道「片中那家餐廳的訂位電話」或「那個雕像的歷史背景」時,這些資訊根本不在影片裡。
- 孤島 B: 純文本深度搜索
- 現狀: 現有的 Agent 評測 (如 GAIA, Search-o1) 大多從文字指令開始。即便支援多模態,也往往只處理靜態截圖。
- 痛點: 它們缺乏**時間維度 (Temporal Dimension)**的感知。這些模型無法理解「影片第 5 分鐘出現的那個建築」與「第 10 分鐘出現的內部裝潢」是同一個地點,更無法從動態的視覺流中提取搜尋的線索。
2.2 核心痛點: 缺失的連結
我們發現,現實世界中的 Video Question Answering 往往是 Open-domain Factoid 的。這意味著:
- 知識在網上: 答案分佈在互聯網的海量資訊中,而非影片內。
- 索引在片中: 搜索的關鍵字必須通過理解影片的視覺細節 (Visual Anchors) 來生成。
過去的模型要麼「只懂看片但不能上網」,要麼「只懂上網但看不懂時間序列」。VideoDR 的核心洞見,就是強行將這兩者綁定,填補了「影片感知」與「網路搜尋」之間的真空地帶。
3 方法介紹
為了測試模型是否具備這種「看片 + 搜尋」的綜合能力,作者並沒有提出一個新模型,而是精心設計了一套評測任務與數據構建流程。這部分是論文方法論的精華,特別是其數據過濾的邏輯,充滿了設計巧思。
3.1 任務定義
首先,我們用數學語言來精確描述這個任務。VideoDR 將任務定義為函數 :
其中每一個變數都代表了特定的約束:
- (Video): 輸入的影片。它是所有推理的起點 (Anchor) 。
- (Question): 自然語言問題。這個問題是設計過的,無法單憑 或外部常識直接回答。
- (Search Tool): 瀏覽器搜索工具。這是模型獲取外部知識 的唯一途徑。
- (Answer): 最終輸出的事實性答案,必須唯一且可驗證。
這個公式背後隱藏著兩個關鍵操作步驟,這也是我們在討論中反覆強調的重點:
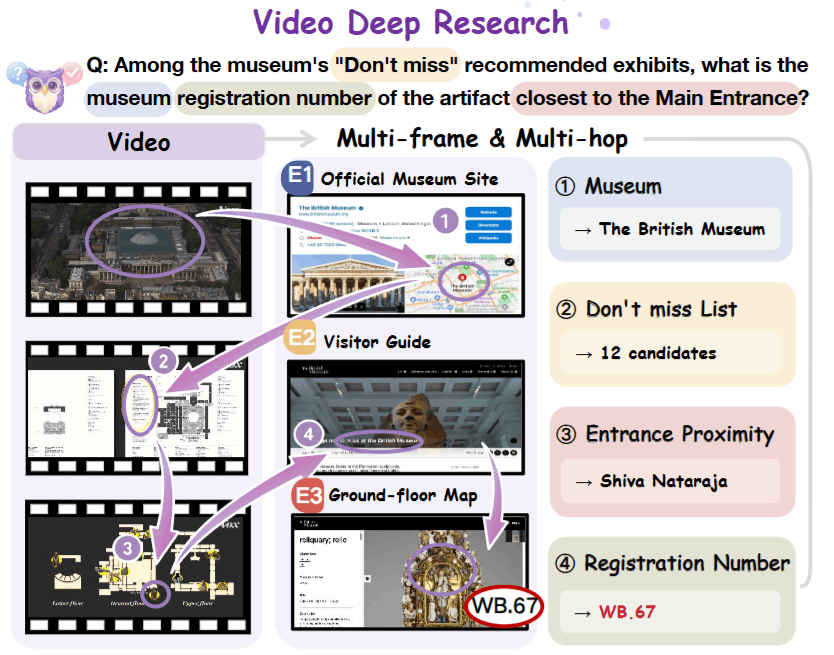
- Visual Anchor 提取: 模型必須先「看」影片,將模糊的視覺訊號 (如「那個紅色的圓頂建築」) 轉譯為具體的文本實體 (如「聖保羅大教堂」) 。
- Multi-Hop Reasoning: 模型不能只搜一次。它通常需要進行
Video -> Web -> Video -> Web的迭代交互。例如: 先確認地點 (Web) ,再回看影片確認路線 (Video) ,最後搜索該路線上的特定商店 (Web) 。
3.2 數據構建: 漏斗式過濾
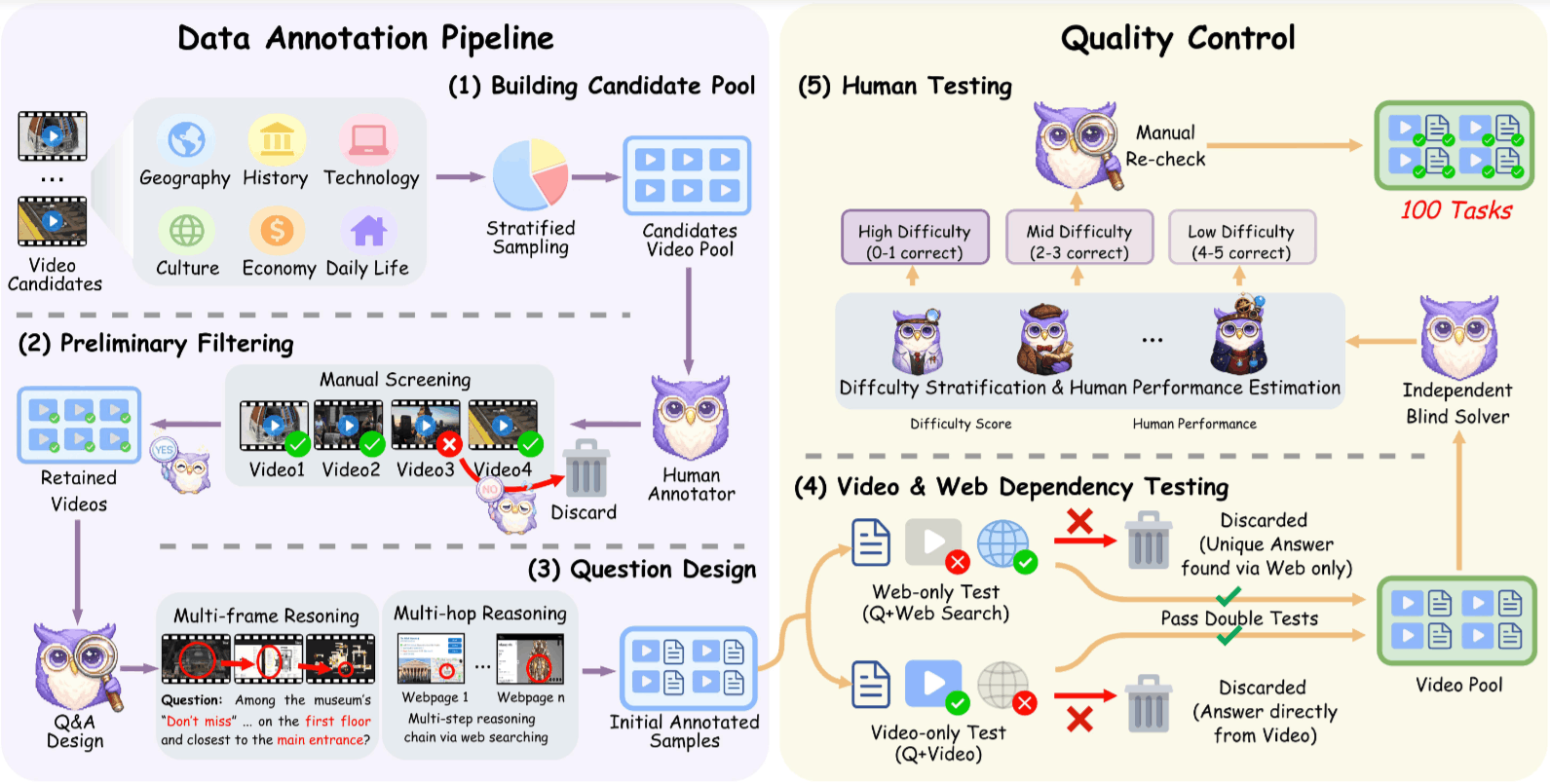
這篇論文最精彩的部分在於數據集的建立。作者不追求數量 (最終僅 100 題) ,而是追求極致的質量。
3.2.1 負樣本過濾
在人工標註前,先剔除「作弊」的可能性:
- 剔除 單一場景: 缺乏時序推理的必要性。
- 剔除 熱門話題: 這是為了防止模型利用訓練數據中的世界知識直接回答 (例如「Taylor Swift 2024 演唱會地點」) 。我們要求模型必須依賴當下的影片內容。
- 剔除 孤立內容: 網上找不到其他資訊的影片。
3.2.2 雙重消融測試
這是 VideoDR 的黃金標準。每一個標註好的樣本 ,都必須通過兩項嚴格測試才能存活:
唯搜尋測試:
- 操作: 只給人類 和搜尋工具 ,不給影片 。
- 判定: 如果能答對,代表問題洩題了 (Information Leakage) ,刪除。
- 目的: 確保問題具有視覺依賴性。
唯影片測試:
- 操作: 只給人類 和 ,不准上網搜尋。
- 判定: 如果能答對,代表這是傳統 Video QA,刪除。
- 目的: 確保問題具有外部知識依賴性。
只有同時通過這兩項測試的樣本,才具備「雙重依賴性」,這就是 VideoDR 數據集的獨特之處。
3.3 評測範式: Workflow vs. Agent
作者在實驗中標準化了兩種解題策略:
3.3.1 Paradigm A: Workflow
這是一種 「先筆記,後搜尋」 的策略。
- 感知階段:
- 模型讀取影片 (轉化為 Visual Tokens) 。
- 根據問題 ,生成一段詳細的結構化中間文本,描述影片中的關鍵視覺線索。
- 關鍵操作: 生成文本後,丟棄原始影片 。
- 推理階段:
- 模型僅使用上述生成的文本和問題 ,利用搜尋工具 找答案。
- 實作細節: 這階段不使用 RAG 來檢索影片幀,而是依賴 MLLM 的 Long Context 能力一次性讀取並總結影片。
3.3.2 Paradigm B: Agent
這是一種 「帶記憶的持續對話」 策略。
- 初始化: 將影片 的 Visual Tokens 放入 Context 開頭。
- ReAct 循環: 模型進入
While迴圈:- 觀察 Context (包含原始影片 tokens) 。
- 生成 Thought 與 Action。
- 執行搜尋,將 Observation (網頁摘要) Append 到 Context 的尾部。
- 決策: 模型自主決定何時停止搜尋並輸出答案。
- 實作隱患: Context 結構為
[Video Tokens] + [History] + [Search Results]。隨著搜尋次數增加,Context 尾部的文字越來越多,模型對開頭 Visual Tokens 的注意力會被稀釋,導致我們觀察到的 Goal Drift 現象。
4 實驗結果
這篇論文的實驗部分並不是為了證明「某個新模型 SOTA 了」,而是為了回答一個更本質的問題: 「在處理需要長時間推理的影片任務時,我們到底應該把影片轉成文字 (Workflow) ,還是直接讓大模型端到端處理 (Agent) ?」
作者選用了目前主流的閉源模型 (GPT-4o, Gemini-1.5 Pro) 與開源模型 (Qwen2-VL, MiniCPM-V 等) ,在 Workflow 與 Agent 兩種範式下進行了「雙雄對決」。
4.1 Agent 並非萬靈丹
這大概是實驗中最讓我們意外的發現。直覺上,我們認為讓模型自主決定何時看、何時搜 (Agent) 應該比死板的步驟 (Workflow) 更強,但數據講了一個不同的故事。
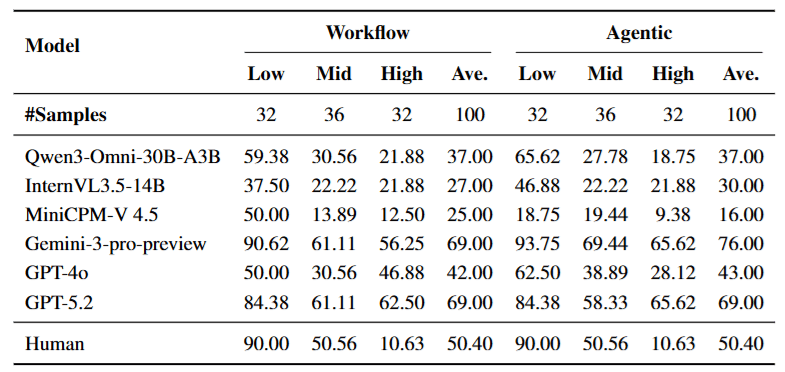
- 強者更強: 對於 Gemini-1.5 Pro 這樣具有超長 Context Window 和強大推理能力的模型,切換到 Agent 模式帶來了顯著提升 (準確率從 69% 升至 76%)。它能有效駕馭複雜的交互循環。
- 弱者崩潰: 對於能力較弱或開源模型 (如 MiniCPM-V 4.5) ,切換到 Agent 模式後,表現反而暴跌 (從 25% 跌至 16%) 。
- 數據背後的故事: 這證明了 Agent 是一把雙面刃。對於弱模型而言,Workflow 產出的「結構化中間文本」雖然丟失了部分細節,但它提供了一個穩定的錨點 (Stable Anchor)。一旦拿掉這個錨點,讓弱模型直接面對海量的搜尋結果與原始影片 Tokens,它們的注意力機制就會「迷路」。
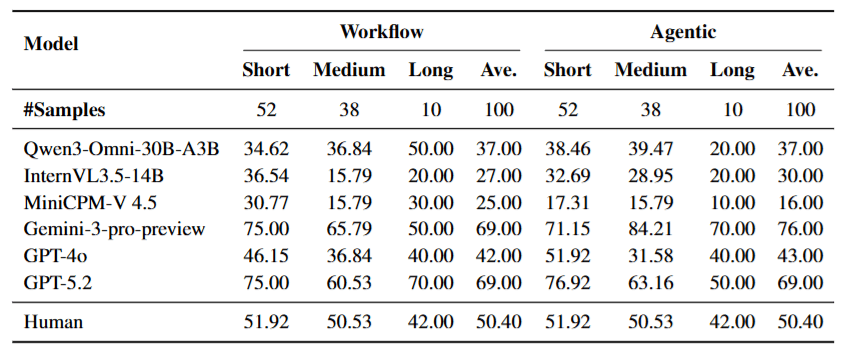
4.2 目標漂移: 長影片的詛咒
為了深入探究「為什麼 Agent 會失敗」,作者按影片時長對結果進行了分層分析。
4.3 錯誤分析: 視覺錨點的丟失
作者進一步分析了錯誤類型,數據再次佐證了上述觀點。
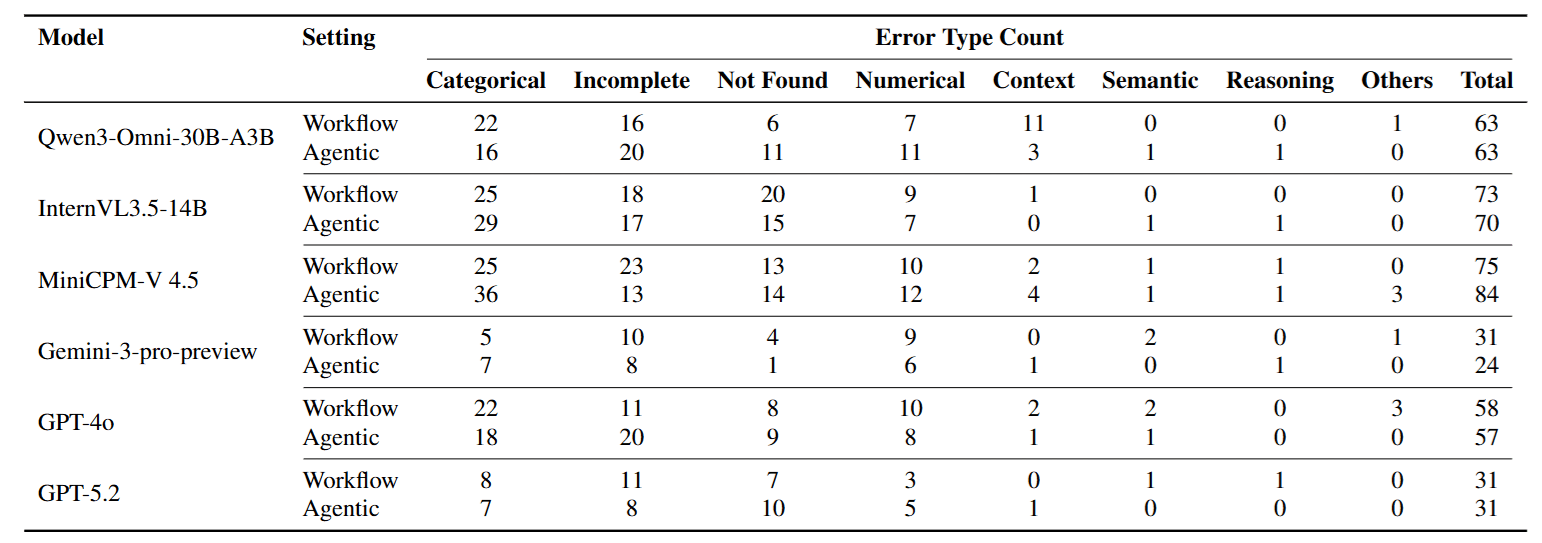
- Categorical Error (類別錯誤) 佔比最高。
- 這意味著模型並不是「算錯了數值」或「推理邏輯錯誤」,而是一開始就找錯對象了 (例如: 題目問 A 博物館,模型去搜 B 博物館) 。
- 這直接證明了模型在多輪搜尋後,丟失了從影片中提取的 Visual Anchor。一旦第一步的視覺鎖定失效,後面的推理再強也是白搭。
4.4 效率分析: 忙碌不代表有效
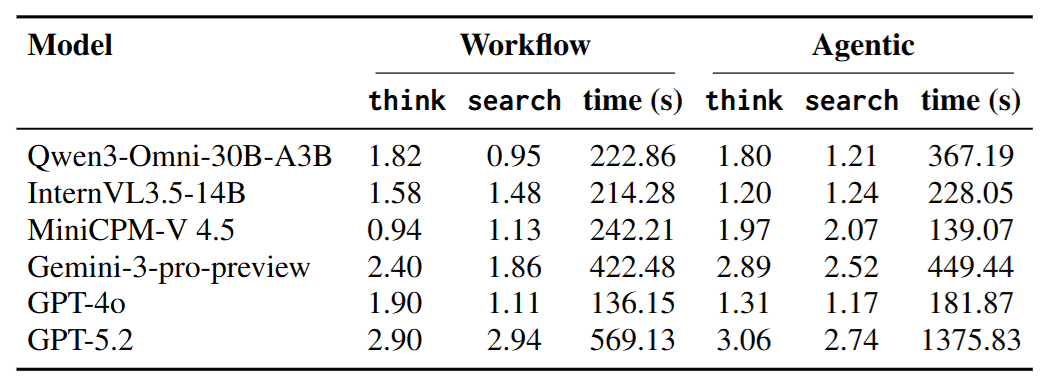
- 無效檢索: 部分開源模型在 Agent 模式下搜尋次數激增,但準確率不升反降。這說明它們在進行無效的「廣撒網」。
- 有效反思: 表現最好的 Gemini,其 Thinking Steps (思考步數) 明顯更多。這告訴我們,在 Video Deep Research 中,「停下來思考 (Reflection)」 (比如反思: 「我搜到的這個信息和影片裡的畫面吻合嗎?」) 比盲目搜尋更關鍵。
5 結論
這篇論文成功地填補了 Video QA 與 Deep Research 之間的空白。
- 問題: 解決了現有評測中「視覺感知」與「外部搜索」脫節的痛點。
- 方法: 提出 VideoDR 任務,利用嚴格的「雙重消融過濾」構建了必須同時依賴視訊錨點與網路證據的數據集。
- 發現: 通過 Workflow 與 Agent 的對比實驗,揭示了 Long-horizon Consistency 與 Goal Drift 是當前多模態 Agent 的最大瓶頸。