告別長文本帶來的「智力退化」:WebResearcher 如何透過迭代研究架構超越 OpenAI?

1 前言

1.1 從「被動檢索」到「主動知識構建」的範式轉移
在追求通用人工智慧 (AGI) 的路徑上,學術界與工業界正經歷一場 Paradigm Shift。過去的 LLM 發展核心在於 Scaling Law,透過擴大參數與數據量來累積被動知識 (Passive Knowledge),讓模型具備驚人的記憶與檢索能力。
然而,真正的人類智慧體現在 「主動知識構建 (Active Knowledge Construction)」。這意味著 AI 不應只是背誦訓練集裡的內容,而必須像一名資深研究員一樣: 自主拆解複雜問題、調度多元工具 (搜尋、計算、程式碼) 、驗證衝突資訊,並最終合成一份邏輯嚴密的深度報告。 這種具備長週期 (Long-horizon) 特性的系統,正是目前最頂尖的 Deep Research 領域。
1.2 業界現狀: 閉源巨頭的壟斷與開源界的死胡同
目前,Deep Research 領域由 OpenAI Deep Research、Gemini Deep Research、Grok DeepSearch 與 Kimi Researcher 等閉源系統主導。雖然這些系統在 Humanity’s Last Exam (HLE) 等極難榜單中表現優異,但其底層架構對外界而言仍是「黑盒子」。
反觀開源界 (如 WebThinker, WebSailor 等) ,雖然嘗試跟進,卻普遍陷入了 「單一上下文範式 (Mono-contextual Paradigm)」 的技術死胡同:
- 線性累積的詛咒: 這些 Agent 傾向於將所有的搜尋紀錄、原始 HTML 與思考過程不斷地 Append 到同一個 Prompt 裡。
- 技術直覺的錯誤: 許多開發者迷信「Context Window 越長越好」,認為只要 Context 夠大,模型就能處理無限的資訊。
1.3 核心挑戰: 資訊膨脹帶來的「智力退化」
論文一針見血地指出,這種線性累積的架構在處理複雜研究時會觸發兩大致命傷:
- Cognitive Workspace Suffocation: 隨著搜尋步數增加,Prompt 中充斥著大量低價值的噪音 (如網頁選單、格式代碼),這會嚴重稀釋 Self-Attention 的注意力,導致模型在關鍵決策時「失焦」,產生 Premature Conclusions (草率結案)。
- Irreversible Noise Contamination: 在沒有「刪除/改寫」機制的 Context 中,早期的錯誤推論或虛假網頁資訊會像滾雪球一樣影響後續每一步,導致 Error Propagation。
1.4 WebResearcher 的核心使命
由 Tongyi Lab 發表的 WebResearcher,是為了打破上述「線性累積」的桎梏。它提出了一個解決方案: 將 Deep Research 重新定義為馬可夫決策過程 (MDP)。
- 它不再保留冗長的歷史,而是透過 IterResearch 機制,在每一輪研究中「提煉精華並重構工作區」。
- 它同時開發了 WebFrontier 資料引擎,量產出高品質軌跡,解決了訓練資料匱乏的問題。
總結來說: WebResearcher 證明了,要讓 Agent 具備「不受限」的研究能力,除了 Context Window 的大小之外,模型如何 「優雅地遺忘雜訊,精準地提煉記憶」 的能力扮演至關重要的角色。
2 核心痛點: 傳統 Agent 的「線性累積」死穴
2.1 Mono-contextual Paradigm
目前絕大多數的開源 Agent (如早期 AutoGPT、WebThinker、WebExplorer) 都遵循一種直覺但低效的架構: 「線性累積 (Linear Accumulation)」。
在這種範式下,Agent 每一輪的輸出 (Thought, Action) 以及外部環境的回饋 (Observation, HTML 原始碼) ,都會被無差別地 Append 到同一個 Context Window 裡。
技術特徵: 隨著搜尋步數 的增加,Context 的長度呈 線性成長。開發者往往希望 Long-context LLMs 能從這座資訊大山中撈出黃金,但現實卻觸發了嚴重的技術悖論。
2.2 Cognitive Workspace Suffocation
這是一個由 Transformer 底層 Attention 決定的物理限制。
- Attention Dilution: 當 Context 填滿了數萬個 Token 的原始網頁資料、廣告文字、無關的導航選單時,模型對「核心問題」與「關鍵線索」的 Attention Weights 會被大幅稀釋。這不只是長度的問題,而是 Signal-to-Noise Ratio, SNR 的崩潰。
- Lost in the Middle: 研究顯示模型對 Prompt 開頭與結尾的感知最強。在長週期研究中,最重要的「初始問題」在開頭,最新的「關鍵證據」在結尾,而中間充斥著大量的搜尋雜訊。這導致模型在做第 20 步決策時,已經忘了第 1 步的初衷。
- Premature Conclusions 當 Workspace 被塞滿後,模型會感受到巨大的「認知壓力」,為了符合輸出長度限制或避免進一步的雜訊,它傾向於在未充分探索前就給出一個應付式的結論。這就是為什麼傳統 Agent 在複雜問題上總是「點到為止」,無法深入。
2.3 Irreversible Noise Contamination
在傳統的 Prompting 機制中,Context 是 Append-only 的。這產生了嚴重的路徑依賴問題。
- Error Propagation:
假設 Agent 在第 3 步誤信了一個包含假資訊的網頁,或者產生了一個邏輯錯誤的
Thought。在線性累積架構下,這個錯誤會永遠留在 Context 裡,成為後續所有推論的「事實基礎」。 - 缺乏「修改記憶」的能力: 傳統 Agent 沒辦法執行「Delete」或「Overwrite」操作。即便模型在第 10 步意識到第 3 步錯了,那份錯誤的記錄依然會干擾它的注意力。這種雜訊會像滾雪球一樣,在長週期任務中導致整條推理鏈條徹底崩解。
2.4 Capability Gap
除了架構問題,論文指出了一個關鍵的資料缺口: 被動回想 vs. 主動建構。
- 現有資料的缺陷: 多數 SFT 資料集練的是「模型從肚子裡掏知識 (Passive Recall)」。
- Deep Research 的需求: 真正的研究需要模型具備「跨來源證據對齊」、「計算驗證」與「矛盾處理」的能力 (Active Construction)。
- 傳統 Agent 因為缺乏這種「博士級研究軌跡」的特訓,即便給它再長的 Context,它也只會像個笨拙的搬運工,而不是精明的分析師。
這是為你深入撰寫的筆記第三章節。本章聚焦於 WebResearcher 的靈魂 —— IterResearch。我們將從數學建模 (MDP) 到工程實作 (State Reconstruction) 進行全方位拆解。
3 IterResearch 迭代研究架構
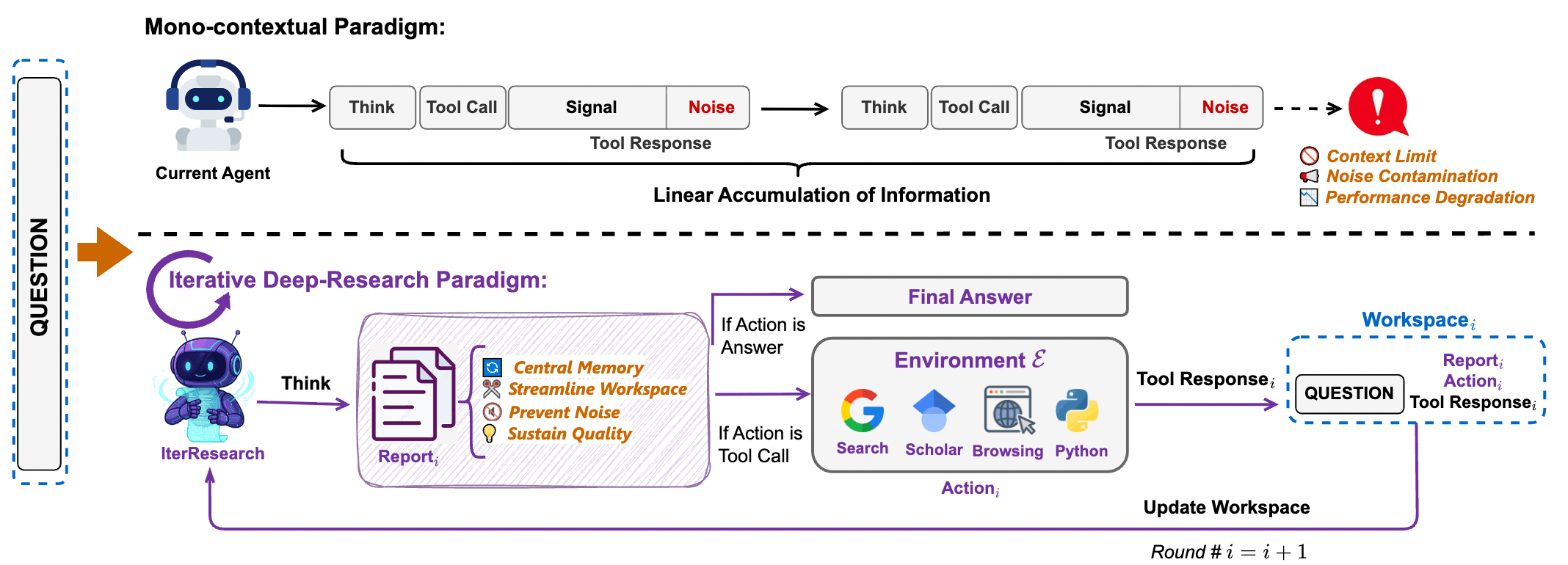
3.1 核心哲學: 從「堆疊歷史」到「重構狀態」
WebResearcher 最具破壞性的創新在於它完全拋棄了傳統 Agent 的「Append-only」思維,轉而採用 馬可夫決策過程 (Markov Decision Process, MDP) 來重新建模 Deep Research 任務。
3.2 State Reconstruction: 維持 的認知壓力
在每一輪研究 (Round ) 開始時,系統會為主動為模型「打掃」工作區,重建一個極度精簡的 Workspace。
- Workspace (Input State ) 的組成:
- Original Question (): 確保模型不忘初心,始終對準目標。
- Latest Report (): 上一輪提煉出的最新進度報告 (這是唯一的長期記憶) 。
- Last Tool Response (): 最近一次工具呼叫的指令及其回傳的原始結果 (例如 5 筆搜尋結果或 Python 執行數據) 。
- 被「丟棄 (Discard)」的內容:
- 過往所有輪次的
Think(內心獨白)。 - 除最後一輪外,所有歷史的
Action與Observation(原始網頁數據)。
- 過往所有輪次的
這種設計將 Context Window 的成長度從 降到了 。無論研究進行到第 10 步還是第 200 步,模型處理的 Token 數量始終維持在最佳的 Attention 區間內。
3.3 結構化輸出: Think-Report-Action 協奏曲
模型被要求以固定的結構化格式進行輸出,這三個部分各司其職,構成了 Agent 的認知循環:
Think(認知草稿 / 暫存記憶):- 角色: 模型內心的 CoT。
- 功能: 分析最新的
Obs是否解決了問題?有沒有發現新線索?下一步該做什麼? - 命運: 本輪結束後即被銷毀。 它是輔助生成的「梯子」,用完即撤,避免過程中的無用思考干擾未來的判斷。
Report(中央記憶體 / 持久化狀態):- 角色: 研究專案的「活文件 (Live Document)」。
- 功能: 模型必須將
Obs中的新知識與舊Report進行融合 (Synthesis)。它需要執行「去重、修正衝突、補充數據、提煉結論」。 - 價值: 它是唯一被帶入下一輪的「精華」,確保了資訊的 高信噪比 (High SNR)。
Action(具體行動 / 環境交互):- 角色: 執行手。
- 功能: 決定下一階段的工具 (Search, Scholar, Visit, Python) 或在證據充足時給出 Final Answer。
3.4 技術邏輯對比: 線性 vs. 迭代
# 傳統 Mono-contextual (歷史包袱極重)
[Question] -> [T1, A1, O1] -> [T1, A1, O1, T2, A2, O2] -> ... -> [T1...On]
# WebResearcher IterResearch (永遠保持清醒)
Round 1: [Question, Empty_Report] -> Output: [T1, R1, A1]
Round 2: [Question, R1, A1, O1] -> Output: [T2, R2, A2] # T1 被丟棄,O1 被 R2 吸收
Round 3: [Question, R2, A2, O2] -> Output: [T3, R3, A3] # T2 被丟棄,O2 被 R3 吸收這是為你深入撰寫的筆記第四章節。本章聚焦於 WebResearcher 的數據動力源——WebFrontier。我們將拆解它如何透過「自我進化」與「能力缺口過濾」,量產出人類標註員也難以企及的高難度研究軌跡。
4 WebFrontier 資料引擎
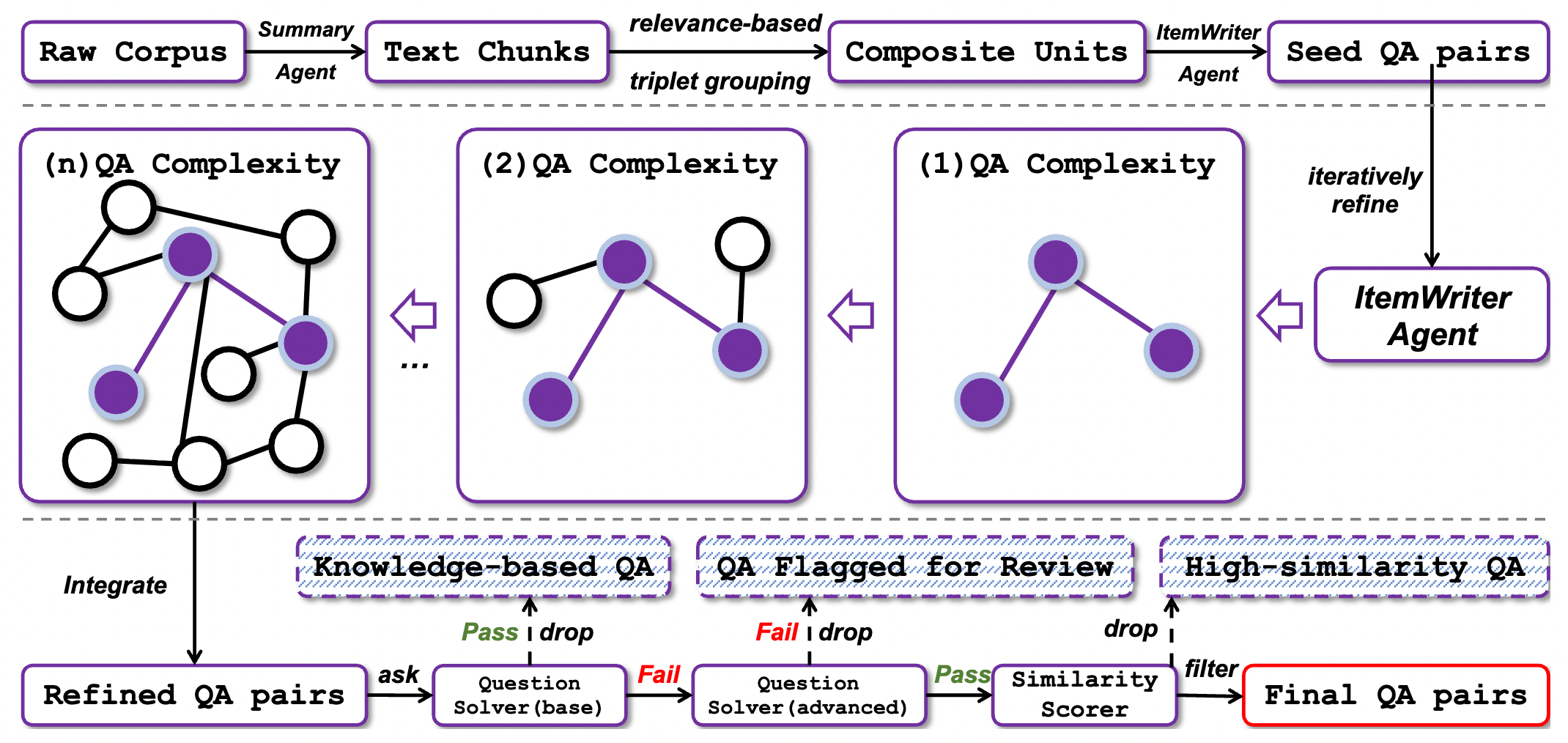
4.1 核心理念:解決專家數據匱乏的問題
在 Agent 領域,高品質的訓練軌跡 (Trajectories) 極其稀缺。網路上的內容多為「結果 (文章) 」,而非「過程 (研究路徑) 」。
WebFrontier 的存在,是為了解決一個核心矛盾:如何在大規模合成數據的同時,確保任務具備「極高難度」且「事實絕對對齊 (Factual Grounding)」?
它採用了一套三階段的 Self-bootstrapping 流水線:
4.2 Stage 1: Seed Generation
如果直接叫 LLM 「生一個難題」,它通常會生出單一事實的常識題。
- Composite Units 機制:
- 從海量語料 (網頁、論文) 中提取文本塊 (Chunks) 。
- 關鍵創新: 系統會刻意將 2~3 個主題相關但來源不同的 Chunks 綁定在一起。
- 要求
ItemWriter Agent根據這些「碎片化資訊」產出原始問題。
- 效果: 確保了問題必須具備多源資訊整合的特質。
4.3 Stage 2: Complexity Escalation
這是 WebFrontier 的靈魂,將「大學生問題」提升至「博士生難度」。這不是單次 Prompt 呼叫,而是一個配備 Tool (Search, Scholar, Python) 的 Agentic Workflow。
**四大核心進化操作 (The Four Operations): **
- **知識擴展 (Knowledge Expansion): ** 呼叫搜尋,將問題的範疇從 A 擴展到 A+B,強迫模型進行更廣泛的檢索。
- **概念抽象 (Conceptual Abstraction): ** 將具體數據提煉為底層原則。例如:從「查營收」變成「分析市場競爭格局與財報透明度的關聯」。
- **事實錨定 (Factual Grounding): ** 這是最重要的「防幻覺」機制。Agent 在升級問題時,必須親自去網路上跑一次研究,確保升級後的問題在現實世界中「確實有解」且「有據可查」。
- **計算公式化 (Computational Formulation): ** 刻意引入需要量化分析的條件,強迫模型呼叫 Python 進行運算,增加邏輯鏈深度。
這裡的實作是多輪交互。Agent 可能要跑 5~10 次 API Call 才能「磨」出一筆高品質的難題。這種「用算力換數據」的作法,雖然前期昂貴,但產出的數據具備極高的 ROI (投資報酬率)。
4.4 Stage 3: Quality Control
生出了超難題後,如何挑選出最適合訓練模型的那一批?WebFrontier 設計了一場「殘酷的雙向淘汰賽」來尋找 Capability Gap:
- 過濾「太簡單」的 (Baseline Mode): ** 讓模型在不准上網**的情況下回答。如果答對了,代表這題靠內建參數知識就能解決,不需要「研究」能力,直接丟棄。
- 過濾「無解/太難」的 (Advanced Mode): ** 讓模型配備全套工具**去解題。如果連最強的工具化模型都解不出來,代表題目可能有瑕疵或數據遺失,直接淘汰。
- 鎖定「黃金樣本」: 只有那些 「光靠大腦解不出來,但給了工具就能解出來」 的題目,才是訓練 IterResearch 的完美養分。
4.5 Data Synthesis Loop
for seed_qa in corpus:
# Stage 2: 多輪工具交互,將難度拉滿
complex_qa = agent.refine_with_tools(seed_qa)
# Stage 3: 雙重驗證
can_solve_without_tools = base_model.solve(complex_qa.question)
can_solve_with_tools = expert_model_with_tools.solve(complex_qa.question)
# 尋找 Capability Gap
if not can_solve_without_tools and can_solve_with_tools:
# 錄製專家模型解題時的 [Think, Report, Action] 軌跡
final_dataset.add(expert_model_with_tools.trajectory) 5 訓練演算法:RFT 與 GSPO 強化學習
5.1 訓練哲學:從「模仿專家」到「超越專家」
即便有了 WebFrontier 的高品質資料,直接進行標準 SFT (Supervised Fine-Tuning) 仍不足以應對極長週期的研究任務。論文採用了兩階段訓練策略:
- **RFT (第一階段): ** 透過「拒絕採樣」篩選出最純粹的推理路徑,建立模型的格式與邏輯底座。
- **GSPO (第二階段): ** 透過「群組序列優化」強化模型在不確定環境下的決策與總結 (Synthesis) 能力。
5.2 第一階段:Rejection Sampling Fine-Tuning (RFT)
RFT 的核心在於 「嚴格的結果導向過濾」。
軌跡生成與篩選: 針對每一個問題 ,讓模型生成多條研究路徑。系統會實施一票否決制:只有最終答案與參考答案完全一致 (Exactly Match) 的軌跡,才會進入訓練集。
馬可夫訓練目標:
- 核心直覺: 我們強迫模型學習「給定當下精簡狀態 ,產出最佳結構化回應 (Think-Report-Action)」。
- 關鍵細節 (Gradient Isolation): 在計算梯度時,只針對模型生成的 Token () 計算 Loss,對於工具回傳的 (Observation) 僅視為 Context。這確保了模型是在學「如何思考與總結」,而不是在背誦搜尋引擎的回傳內容。
5.3 第二階段:Group Sequence Policy Optimization (GSPO)
這是 WebResearcher 性能爆發的關鍵。GSPO 是對 DeepSeek GRPO 的進階改良,專為 Multi-round Sequence 場景設計。
5.3.1 從 GRPO 到 GSPO 的演進
- GRPO: 針對單一 Prompt 生成多個 Answer 進行同儕互評。
- GSPO: 針對單一問題生成多條軌跡,將整條軌跡上的所有 Round 全部展開,視為一個整體的「群組 (Group)」進行評分。
5.3.2 Advantage Calculation
Reward Inheritance: 如果一條軌跡最終成功,該路徑上所有的 Round ( 到 ) 都會獲得 。
Group Normalization: 假設一個問題下有 8 條軌跡,共計 80 個 Round。GSPO 會計算這 80 個 Round 的平均 Reward () 與標準差 ()。
計算 Advantage :
- 直觀理解: 只要你的這一步 (Round) 所在的隊伍贏了,你的得分就會高於群組平均,模型就會強化這一步的行為。
5.4 為什麼 IterResearch 練得更快?
- 傳統架構的低效: 一條 20 步的軌跡在線性累積下是「一個超長樣本」,模型負擔極重,且學習訊號微弱。
- IterResearch 的高效: 同樣 20 步的軌跡被拆解成 20 個獨立的、高信噪比 (High SNR) 的狀態轉換對。
- 結果: 訓練資料量在物理上雖然沒變,但在「有效學習樣本 (Effective Samples)」上翻了數十倍,且每個樣本的 Input 長度都是精簡的 ,大幅提升了收斂速度與 GPU 利用率。
5.5 Minimal-loss Downsampling
為了在多顯卡環境下穩定執行 GSPO,論文解決了 Batch Size 不對齊的問題:
- 問題: 不同問題的步數不同,會導致每張顯卡拿到的 Round 數量不一致。
- 解法: 找到小於總樣本數且能整除顯卡數 () 的最大整數,隨機捨棄極少量樣本(通常 )。這保證了全同步訓練 (Full Sync) 時,沒有任何一張顯卡會因為等待而閒置 (Stall)。
6 Test-time Scaling (Inference Optimization)
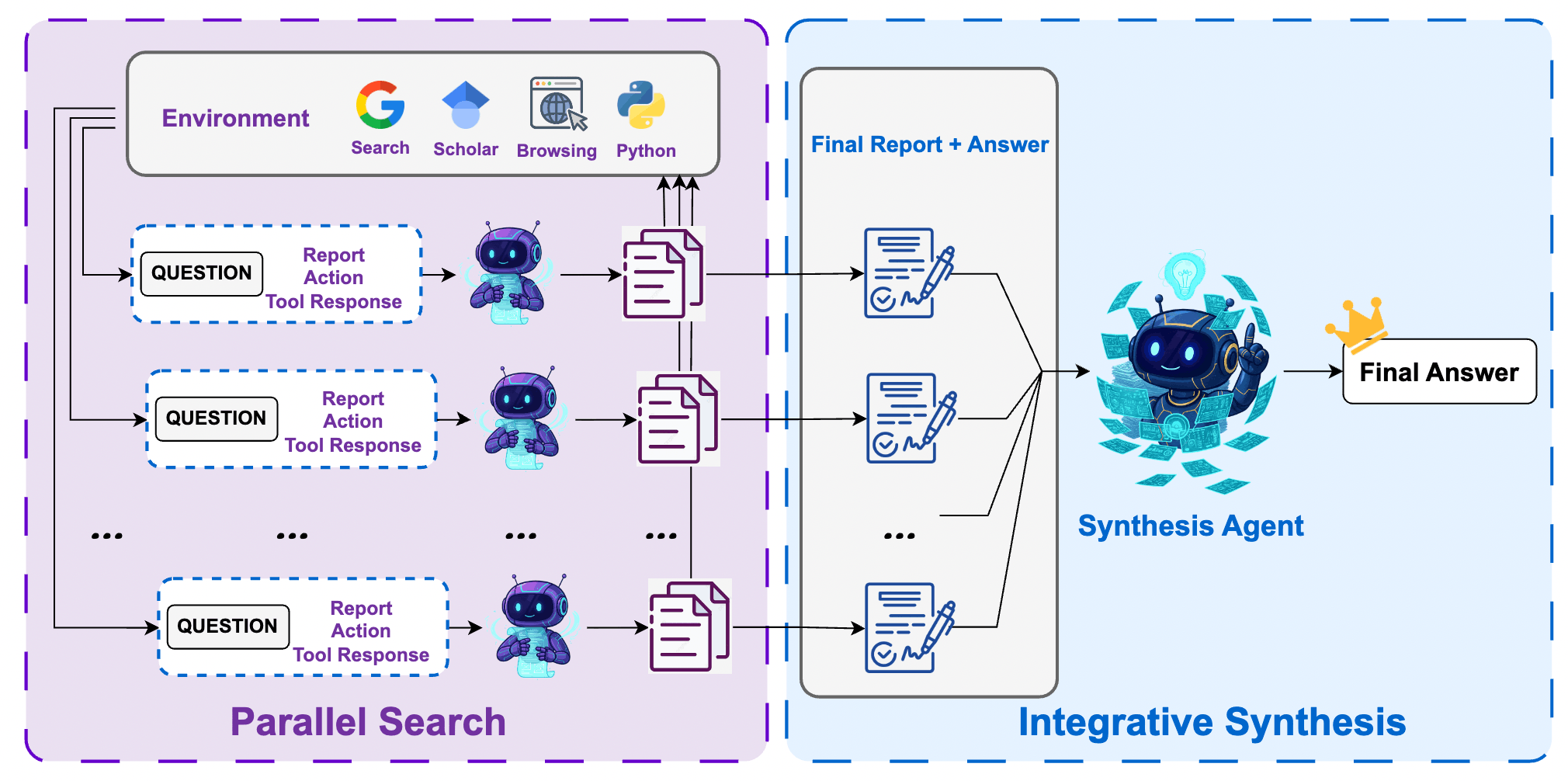
6.1 推論哲學:用「推理算力」換取「決策邊界」
在長週期研究任務中,單次推論()往往會受限於搜尋引擎的隨機性、網頁內容的碎片化或模型在某一步的判斷偏差。
WebResearcher 提出了一個優雅的 Research-Synthesis Framework,其核心邏輯是:「與其指望一個 Agent 完美解決問題,不如讓一群專家分頭研究,最後由一位首席科學家進行情報統合。」
6.2 傳統 Majority Vote 的崩潰
在簡單的數學或邏輯題中,我們可以讓模型跑 10 次並投票。但在 Deep Research 中,這行不通:
- 資訊互補性: Agent A 找到線索 1,Agent B 找到線索 2。兩者分開看都推不出正確答案 (投票會失敗),唯有「整合」兩者的證據才能破題。
- Context 爆炸: 如果嘗試把 8 個 Agent 的所有搜尋歷史 (包含數百個原始網頁) 直接塞給一個模型總結,Context 會突破數十萬 Token,導致嚴重的雜訊干擾與注意力迷失。
6.3 解決方案:Research-Synthesis Framework
6.3.1 第一階段:Parallel Research
- 作法: 同時啟動 個獨立的 WebResearcher Agent。
- 特性: 由於 LLM 採樣的隨機性,這 個 Agent 會分頭採集不同的網頁。
- 產出: 每個 Agent 最終會產出一份 Final Report 以及一個 Predicted Answer。
- 優勢: 這些 Report 已經過 IterResearch 的高密度提煉,去除了 95% 的網頁雜訊,僅保留核心證據。
6.3.2 第二階段:Integrative Synthesis
- 角色: 找一個最強的大模型(如 Qwen3-235B)擔任 Synthesis Agent。
- 輸入: 將這 份 Final Reports 與答案全部組合在一起。
- 動作: 綜合大腦不再親自上網,而是閱讀這 份專家報告。它會執行「證據對齊 (Evidence Alignment)」,找出不同報告中的矛盾點,並根據交叉驗證的強度給出最終答案。
6.4 Context 的降維打擊
為什麼這個框架能 Scaling?因為它在物理上解決了資訊密度的難題:
- 傳統架構: Context 需求 = (所有網頁原始碼 + 所有思考過程) 無限大,無法處理。
- WebResearcher: Context 需求 = (精簡過後的 Final Report) 線性可控,維持高信噪比 (High SNR)。
這種設計讓 Synthesis Agent 能夠在有限的 Context Window 內,處理比對手多出數倍的「有效證據量」。
這是為你深入撰寫的筆記第七章節。本章節聚焦於 WebResearcher 如何透過數據「證明」其架構的優越性。身為技術主管,我將帶你跳過表面的分數,直接看懂實驗背後的因果關係 (Causality)。
7 實驗節果
7.1 HLE (Humanity’s Last Exam)
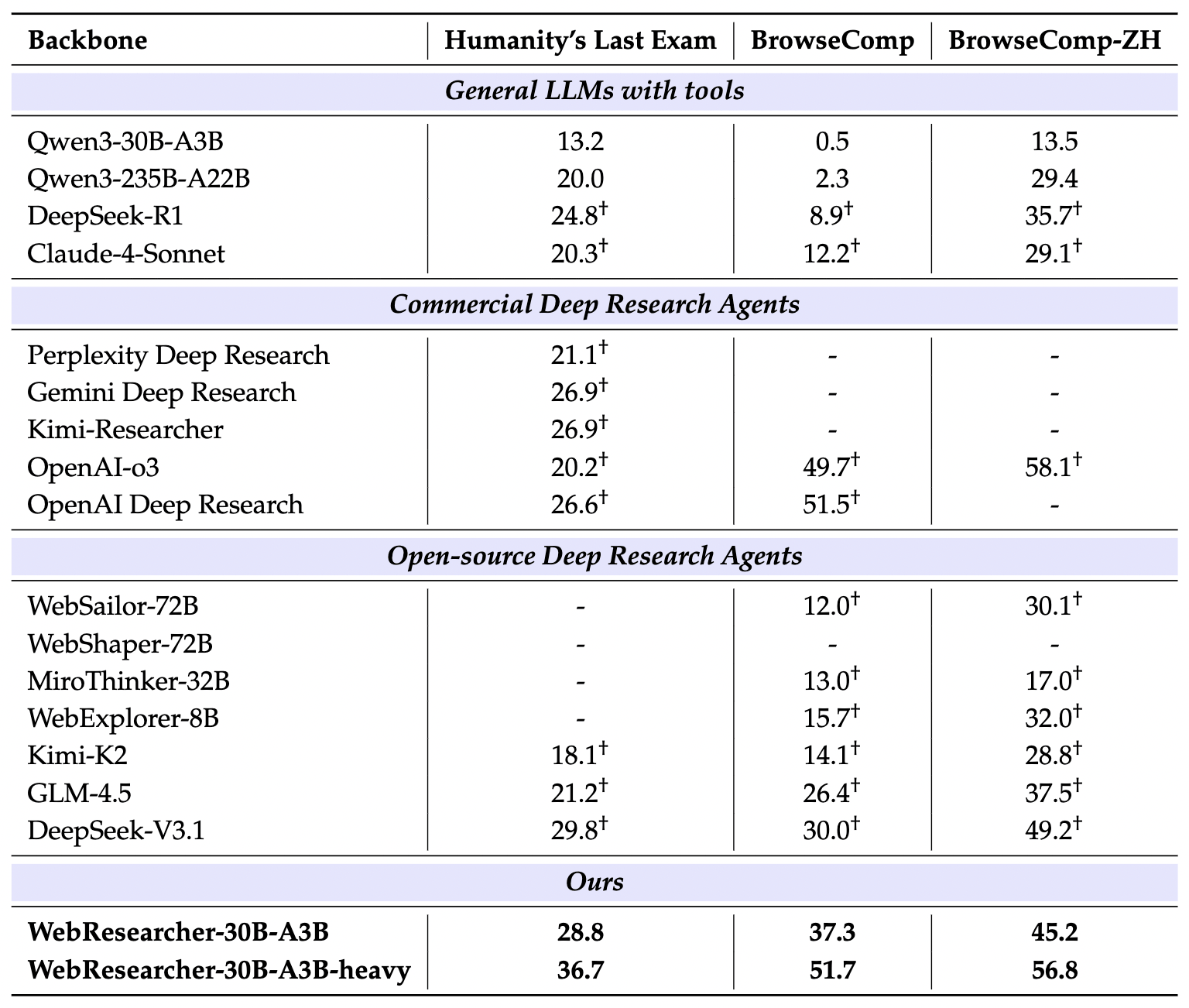
HLE 被公認為目前 AI 領域最難的「博士級」基準測試,題目涵蓋極廣泛的學科,且設計初衷就是為了讓模型無法輕易透過檢索得到答案。
- 實驗結果: WebResearcher-heavy 達到 36.7% 的準確率。
- 對比分析:
- OpenAI Deep Research: 26.6%
- DeepSeek-V3.1 (R1-based): 29.8%
- Gemini Deep Research: 26.9%
在 HLE 這種高難度任務中,WebResearcher 領先次強對手近 7 個百分點。這證明了對於需要「深度知識合成 (Deep Synthesis)」而非「簡單檢索」的任務,IterResearch 的報告迭代機制能大幅提升決策的精準度。
7.2 資料 vs. 架構
這是全篇論文最具說服力的實驗,它回答了一個核心問題:「強大的是資料 (WebFrontier),還是架構 (IterResearch)?」
| 模式 (Agent) | HLE 準確率 | BrowseComp (EN) |
|---|---|---|
| Mono-Agent (傳統) | 18.7% | 25.4% |
| Mono-Agent + Iter Data (餵好資料但架構不變) | 25.4% | 30.1% |
| WebResearcher (全武裝:架構 + 資料) | 28.8% | 37.3% |
- 兩次跳躍的解析:
- 第一次跳躍 (18.7% → 25.4%): 證明了 WebFrontier 合成的高難度軌跡,能有效提升任何模型(即便架構沒變)的推理能力。
- 第二次跳躍 (25.4% → 28.8%): 這是最重要的!它證明了在資料完全相同的情況下,「迭代重構 (MDP)」 本身就是性能的乘數。這驗證了「線性累積」確實存在能力上限,而 IterResearch 突破了這個天花板。
7.3 Test-time Scaling 的收益遞減曲線
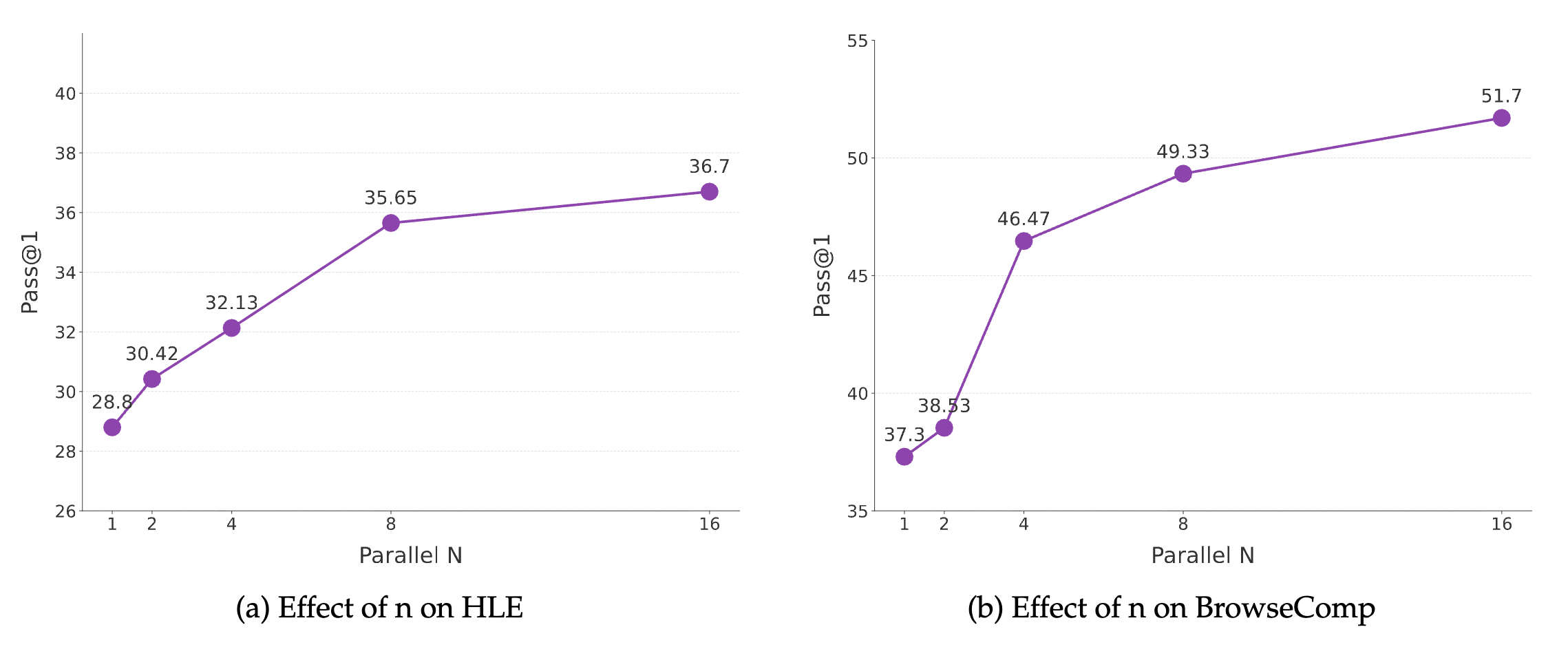
推論算力 (Inference Compute) 真的能換取智商嗎?
- 實驗觀測: 當平行研究數量 從 1 增加到 8 時,分數呈現指數級上升。
- 飽和點: 在 之後,收益開始出現遞減。
- 關鍵結論: 證明了 Synthesis Agent (綜合大腦) 的強大。即便每個研究 Agent 只有 30B 的規模,只要給予足夠的平行視角,最終產出的結論質量就能超越單一的巨型閉源模型。
8 落地挑戰與思考
8.1 落地的三大工程瓶頸
即便 WebResearcher 在 Benchmark 上刷出驚人高分,但在真正商用化 (如:企業級 AI 智庫、自動化研報系統) 時,我們會面臨以下現實挑戰:
- Latency 的極致考驗:
- 計算累積: 每一步都要生成
Think和Report,這意味著 Token 生成量遠高於傳統 Agent。 - 序列阻塞: Deep Research 任務通常需要 20~60 步,哪怕是 的平行研究,最後的 Synthesis 必須等待所有 Agent 跑完。對於追求「秒回」的 C 端產品,這種分鐘級的等待體驗極其糟糕。
- 計算累積: 每一步都要生成
- Inference Cost 的爆炸:
- Token 消耗: 每一輪都要重新輸入
Question和Report。隨著研究深入,Report 會變厚。雖然比線性累積省錢,但比起簡單的 RAG 依然昂貴許多。 - 算力預算: 為了達到 SOTA,必須使用 Test-time Scaling (n=8) 配合 235B 的大模型進行總結。這種算力配比在商業大規模推廣時,毛利空間會被壓縮得非常厲害。
- Token 消耗: 每一輪都要重新輸入
- Infrastructure Robustness:
- 瀏覽器集群: 維護一個能穩定爬取 JavaScript 渲染網頁、處理驗證碼(CAPTCHA)且不被封鎖的瀏覽器集群,其工程難度不亞於開發模型本身。
- Python 沙盒安全: 頻繁執行模型生成的程式碼,需要極其嚴格的隔離機制。
8.2 The Markovian Curse
IterResearch 雖然優雅,但它隱藏著一個致命的風險:資訊遺漏後的「不可挽回性」。
- Information Bottleneck:
系統的成敗 100% 押注在模型「提煉 Report」的能力上。如果模型在第 3 輪認為某個網址或某個小數據不重要,沒有寫入
Report,那麼在第 4 輪該 Observation 就會被徹底丟棄。 - 風險: 一旦發生這種遺漏,Agent 就會像丟了關鍵線索的偵探,即便後續再強,也無法從已經消失的歷史中找回真相。這就是為什麼論文必須使用強大的 WebFrontier 資料來特訓「總結能力」。
8.3 對 Synthesis Agent 的過度依賴
- 最後的決策品質高度取決於那個「首席科學家 (論文中使用 235B 模型)」。
- 如果 Synthesis Agent 的推理能力不足,它可能會在 份各具道理的報告中感到困惑,甚至被其中一份包含幻覺的報告誤導。這意味著這套框架目前無法實現「全小模型化」,必須依賴一個巨型大腦坐鎮。
9 結論
9.1 WebResearcher:從「長文本」到「長邏輯」的範式轉移
WebResearcher 的成功,標誌著 AI Agent 發展史上一次關鍵的範式轉移。它向全球研究者證明了一個深刻的道理:要賦予模型「不受限的推理能力 (Unbounded Reasoning)」,關鍵不在於給它一個無限大的 Context Window,而在於給它一套優雅的「狀態提煉機制」。
這篇論文的核心貢獻可以歸納為以下三個技術維度:
- Architecture: 透過將 Deep Research 建模為 馬可夫決策過程 (MDP),IterResearch 徹底解決了「線性累積」帶來的認知窒息與雜訊污染。它證明了 「結構化迭代」比「暴力堆疊」更能釋放模型的高階智力,讓 的 Context 長度也能支撐 200 輪以上的複雜研究。
- Data: WebFrontier 資料引擎打破了專家數據匱乏的僵局。透過「工具增強的難度升級」與「能力缺口篩選」,它量產出了高品質、具備事實對齊的「博士級研究軌跡」。這套引擎不僅練就了 WebResearcher 的大腦,更為開源界提供了合成專家數據的新標竿。
- Optimization: GSPO 強化學習 解決了長序列獎勵分配的難題,讓模型學會為「每一次總結」負責;而 Research-Synthesis 框架 則驗證了「推論時算力 (Test-time Scaling)」在複雜決策中的巨大潛力。
9.2 技術標竿:HLE 36.7% 的深層意義
WebResearcher-heavy 在 HLE 榜單上取得的 36.7% 成績,不只是一個數字,它代表了開源中型模型 (30B) 配合正確的架構與算力策略,是有能力在特定領域超越頂尖閉源模型 (OpenAI, Gemini) 的。 這為許多算力有限的公司與研究團隊指明了方向:優化認知流程,往往比單純盲目追逐參數規模更有效。
9.3 未來展望:Agent 的下一站
雖然 WebResearcher 已經非常強大,但它仍為未來留下了值得探索的空間:
- 低成本化: 如何在不依賴 Test-time Scaling (n=8) 的情況下,達到接近的性能?
- 更強的自我糾錯: 是否能引入更精密的「反思機制 (Reflexion)」,讓 Report 的提煉更加無損?
- 多模態研究: 擴展到圖像、表格、影音等更複雜的網頁環境。